Comprehensive Scraper Workflow for n8n
An extensive data extraction workflow for n8n designed to gather information from multiple sources.
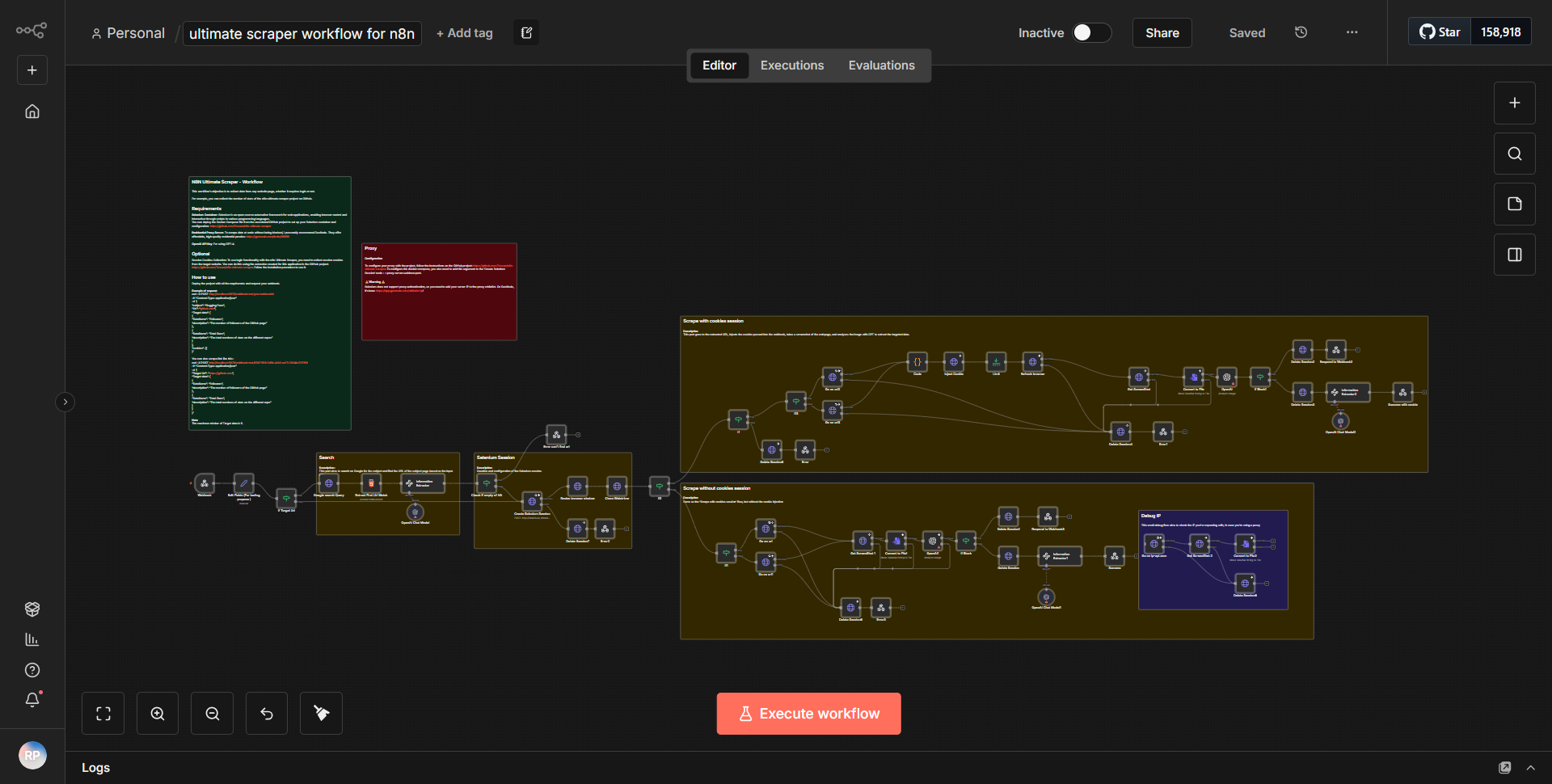
How it works
The Comprehensive Scraper Workflow for n8n is designed to extract data from multiple sources in a structured manner. The workflow begins with a
Cron node
, which triggers the process at specified intervals. This node is configured to run the workflow daily, ensuring that data is collected regularly.Following the Cron node, the workflow utilizes an
HTTP Request node
to fetch data from a specified URL. This node is configured to perform a GET request, allowing it to retrieve the HTML content of the target webpage. The output from this node is then passed to aHTML Extract node
, which is responsible for parsing the HTML content and extracting relevant data points based on predefined selectors.Once the data is extracted, it is sent to a
Set node
where it is formatted and organized into a more manageable structure. This node allows for renaming fields and adjusting the data format as necessary. The processed data is then directed to aFunction node
, which can perform additional transformations or calculations on the data, enhancing its usability.After the data has been transformed, it is sent to a
Database node
for storage. This node is configured to insert the data into a specified database, ensuring that the extracted information is saved for future reference. Finally, the workflow concludes with aWebhook node
, which can be used to notify other services or trigger additional actions based on the completion of the data extraction process.Key Features
1. Automated Data Extraction:
The workflow automates the process of data extraction from multiple sources, reducing manual effort and increasing efficiency.
2. Customizable Scheduling:
With the Cron node, users can easily customize the frequency of data extraction, ensuring that the latest information is always available.
3. Flexible Data Parsing:
The HTML Extract node allows for flexible parsing of HTML content, enabling users to specify exactly which data points to extract based on their needs.
4. Data Transformation Capabilities:
The inclusion of the Set and Function nodes allows for extensive data manipulation, ensuring that the extracted data is in the desired format before storage.
5. Integration with Databases:
The workflow seamlessly integrates with databases, allowing for easy storage and retrieval of extracted data.
6. Notification System:
The Webhook node provides a mechanism for notifying other services or triggering additional workflows, enhancing the overall functionality of the system.
Tools Integration
The Comprehensive Scraper Workflow integrates with several tools and services, utilizing specific nodes within n8n:
- Cron node:
For scheduling the workflow execution.
- HTTP Request node:
For fetching data from external URLs.
- HTML Extract node:
For parsing HTML content and extracting specific data points.
- Set node:
For formatting and organizing the extracted data.
- Function node:
For performing additional data transformations.
- Database node:
For storing the extracted data in a database.
- Webhook node:
For sending notifications or triggering other workflows.
API Keys Required
This workflow does not require any API keys or authentication credentials to function. All nodes operate based on publicly accessible data or local database configurations.









