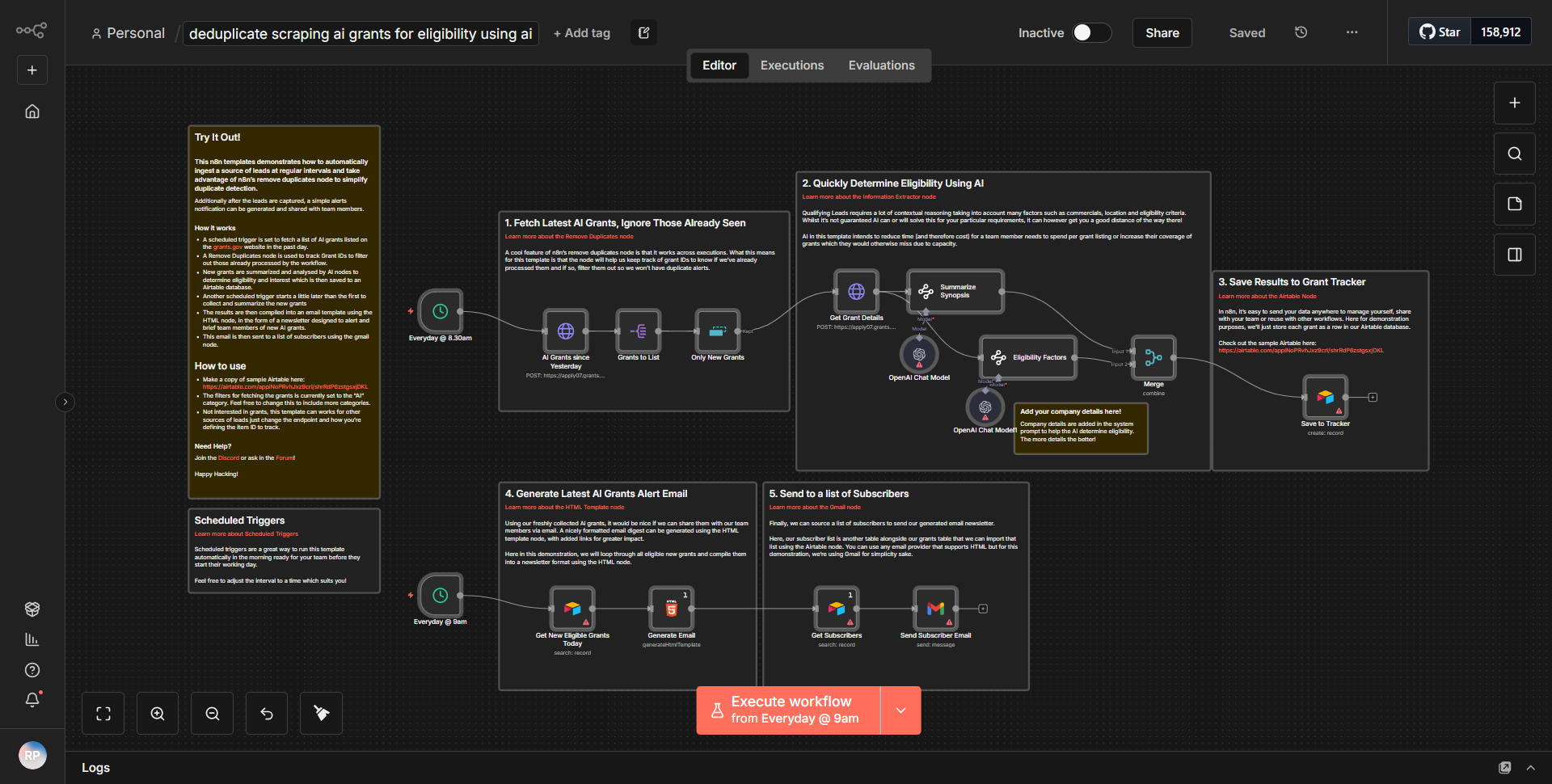
Automated Workflow for Retrieving and Categorizing Hugging Face Paper Summaries
Streamlines the retrieval, summarization, and classification of research papers from Hugging Face.
How it works
The workflow titled "Automated Workflow for Retrieving and Categorizing Hugging Face Paper Summaries" is designed to streamline the process of fetching, summarizing, and categorizing research papers from Hugging Face. The workflow operates through a series of interconnected nodes that facilitate data flow and processing.
1. Trigger Node:
The workflow begins with a trigger node that initiates the process. This could be a scheduled trigger or an event-based trigger, depending on the specific configuration.
2. HTTP Request Node:
The first operational node is an HTTP Request node, which sends a request to the Hugging Face API to retrieve a list of research papers. This node is configured with the appropriate endpoint and parameters to ensure it fetches the desired data.
3. Function Node:
After retrieving the data, the workflow utilizes a Function node to process the response. This node extracts relevant information from the API response, such as paper titles, abstracts, and URLs, preparing it for summarization.
4. Summarization Node:
The next step involves another HTTP Request node that sends the extracted abstracts to a summarization API. This node is responsible for generating concise summaries of the research papers.
5. Categorization Node:
Following the summarization, the workflow employs a categorization node, which likely uses a machine learning model or a predefined set of categories to classify the summarized papers based on their content.
6. Output Node:
Finally, the workflow concludes with an output node that formats the results for presentation or storage. This could involve sending the categorized summaries to a database, an email, or another service for further use.
Throughout the workflow, data flows sequentially from one node to the next, with each node performing a specific function that contributes to the overall goal of summarizing and categorizing research papers.
Key Features
1. Automated Data Retrieval:
The workflow automates the process of fetching research papers from Hugging Face, eliminating the need for manual data collection.
2. Summarization Capability:
It includes a summarization feature that condenses lengthy abstracts into concise summaries, making it easier for users to grasp the key points of each paper quickly.
3. Categorization:
The workflow categorizes the summarized papers, allowing users to filter and organize research based on specific topics or themes.
4. Integration with APIs:
The workflow seamlessly integrates with external APIs, leveraging their capabilities to enhance data processing and analysis.
5. Customizable Triggers:
Users can configure triggers to run the workflow on a schedule or in response to specific events, providing flexibility in how and when the workflow operates.
Tools Integration
The workflow utilizes several tools and integrations, including:
- Hugging Face API:
For retrieving research papers and possibly for summarization.
- HTTP Request Nodes:
Used to interact with external APIs for both fetching papers and sending data for summarization.
- Function Node:
For processing and transforming data between nodes.
- Categorization Model:
This could be a machine learning model integrated into the workflow for classifying the papers.
API Keys Required
To operate this workflow, the following API keys and credentials are necessary:
1. Hugging Face API Key:
Required for authenticating requests to the Hugging Face API to fetch research papers and possibly for the summarization service.
2. Summarization API Key:
If a separate summarization service is used, an API key for that service will also be needed.
If there are no additional services requiring authentication, this will be the complete list of API keys required for the workflow to function correctly.