HTML URL をマークダウン形式に変換し、ページリンクを取得する
このワークフローは、指定された URL から取得した HTML データをマークダウン形式に変換すると同時に、ページ上に存在するすべてのリンクを取得するため、コンテンツのスクレイピングと分析に役立ちます。
仕組み
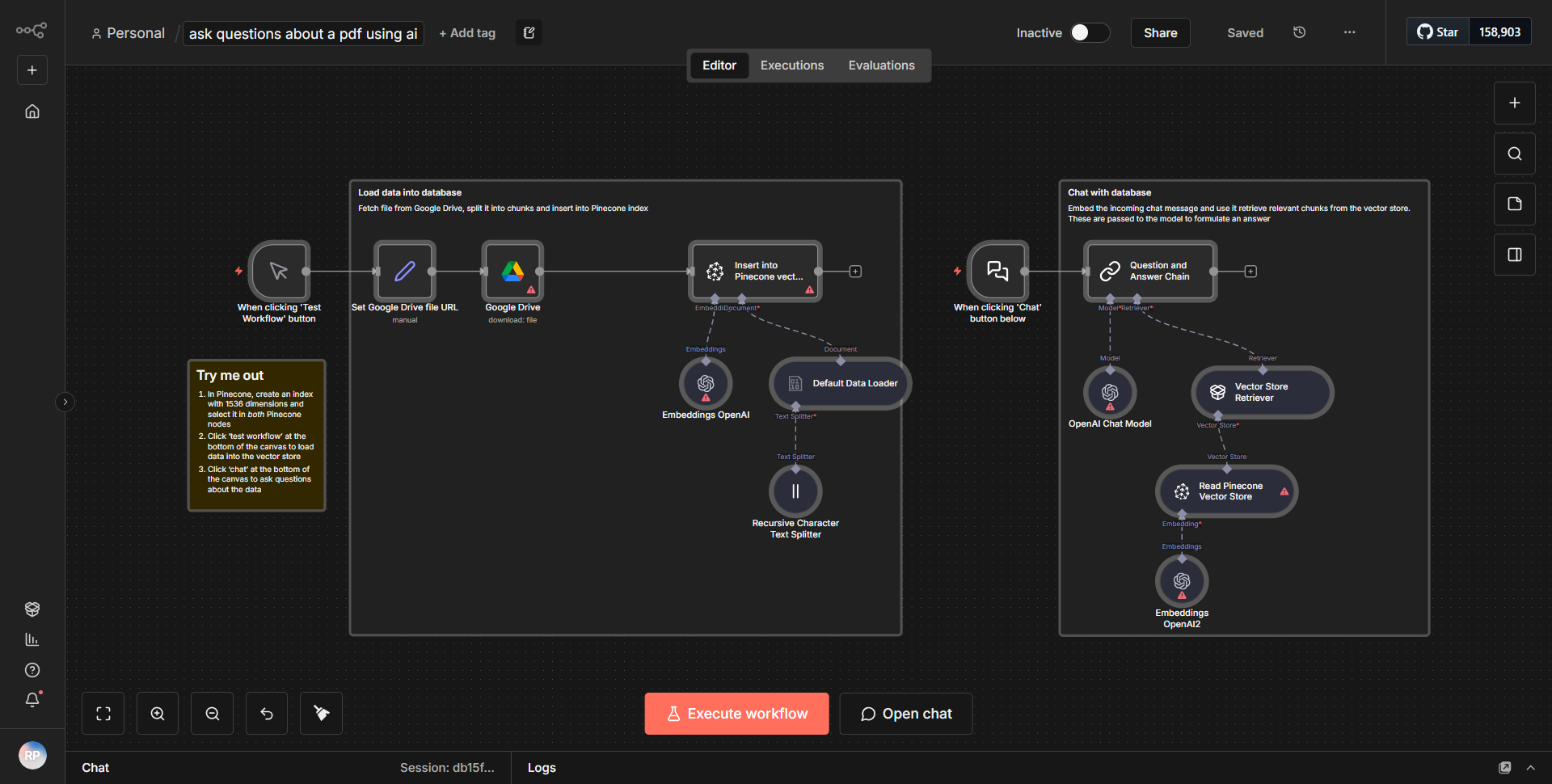
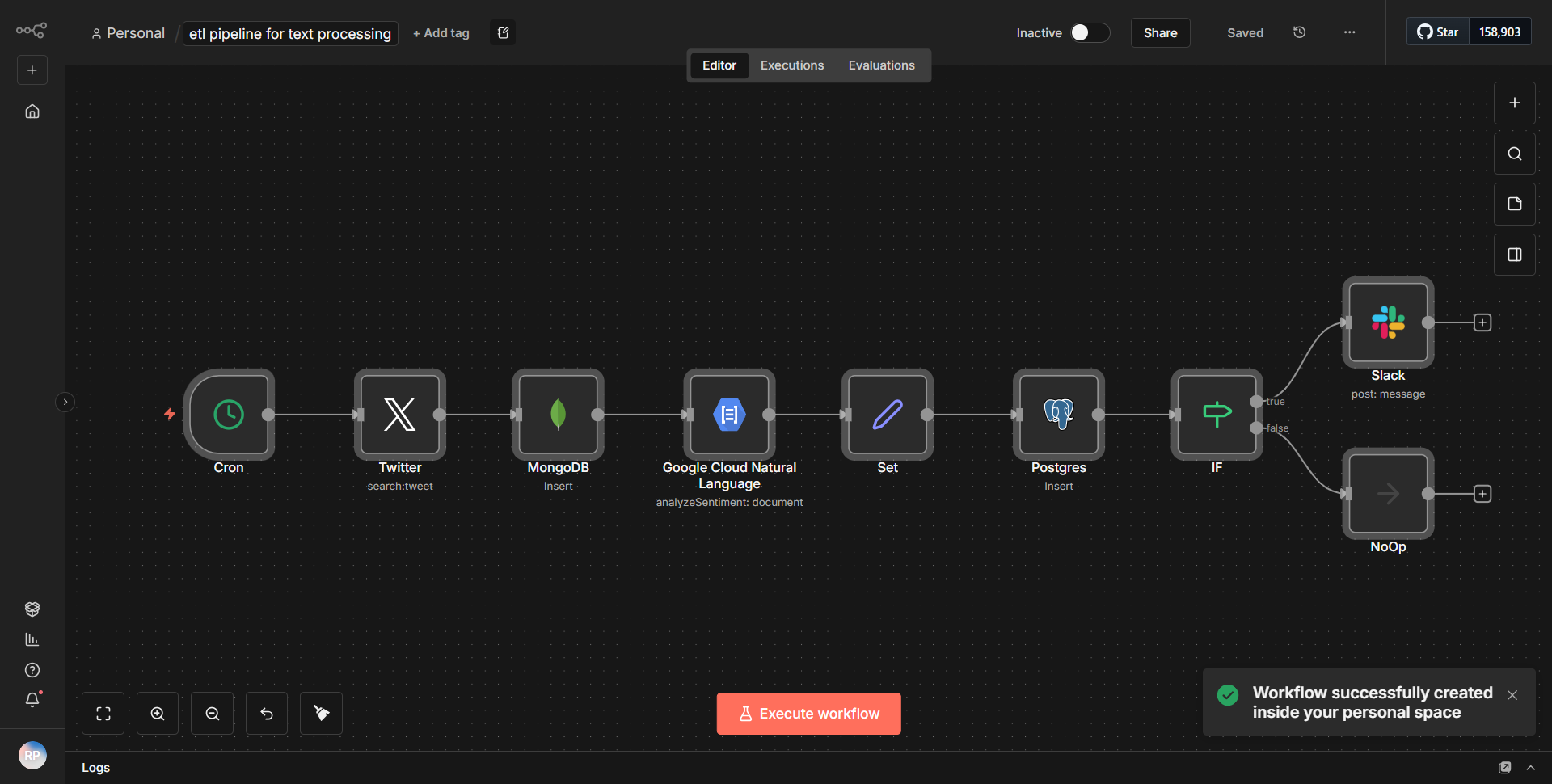
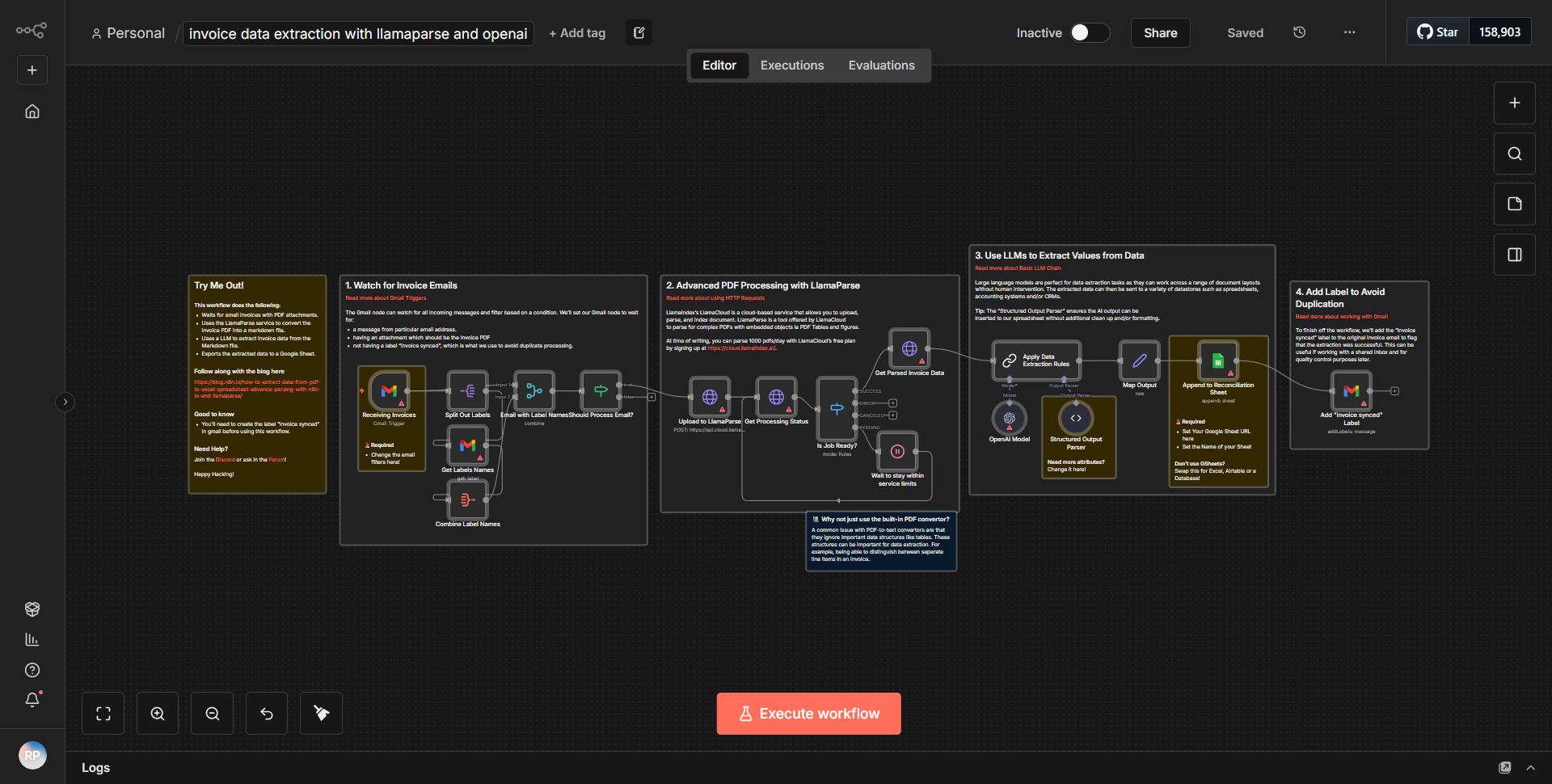
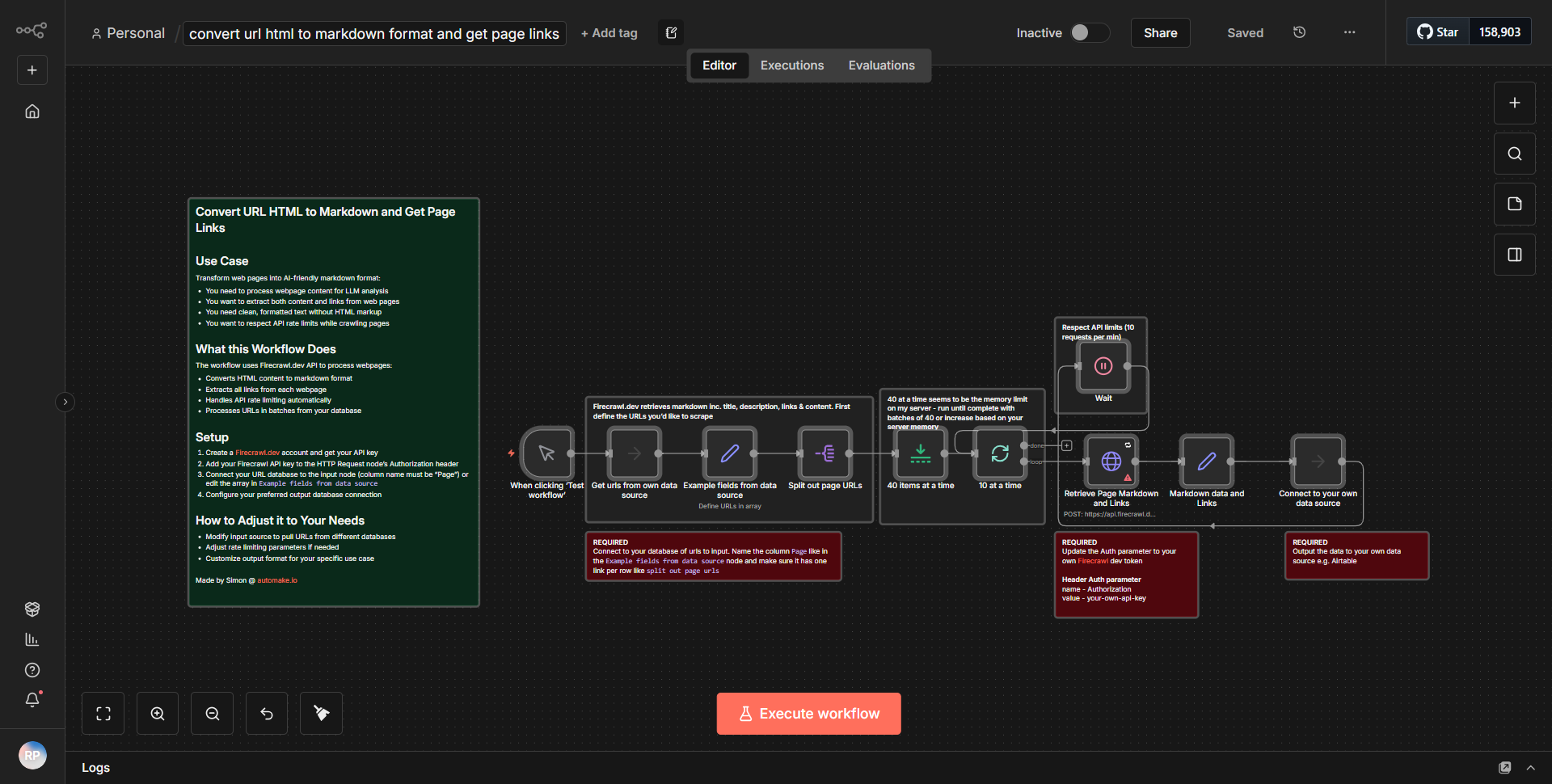
このワークフローは、指定された URL から HTML コンテンツをフェッチするように構成された「HTTP リクエスト」ノードから始まります。応答を受信すると、HTML データが「HTML Extract」ノードに渡されます。このノードは、HTML を解析し、ページ上に存在するすべてのハイパーリンク (アンカー タグ) を抽出します。抽出されたリンクは、データを処理して URL を Markdown 構文に変換する「Function」ノードを使用して、Markdown に適した形式にフォーマットされます。最後に、ワークフローは変換された Markdown コンテンツをリンクのリストとともに出力するため、コンテンツのスクレイピングと分析に適しています。ノードは順番に接続され、あるプロセスから次のプロセスへのデータの流れがスムーズになります。
主な機能
1. HTML からマークダウンへの変換:
このワークフローは、HTML コンテンツをドキュメントやコンテンツ管理に広く使用されているマークダウン形式に効果的に変換します。
2. リンク抽出:
提供された HTML ページからすべてのハイパーリンクを取得し、ユーザーがコンテンツの構造や外部参照に関する貴重な情報を収集できるようにします。
3. 自動化されたプロセス:
ワークフロー全体が自動化されているため、ユーザーは手動介入なしでデータを迅速に変換および抽出できます。
4. カスタマイズ可能な入力:
ユーザーは任意の URL を指定して HTML コンテンツを取得できるため、さまざまな Web ページにワークフローを柔軟に適用できます。
5. データ出力:
最終出力には、Markdown コンテンツと抽出されたリンクのリストの両方が含まれており、さらなる分析のための包括的なデータが提供されます。
ツールの統合
ワークフローには、次のツールとサービスが統合されています。
- HTTP リクエスト ノード:
HTTP 呼び出しを実行して、指定された URL から HTML コンテンツを取得するために使用されます。
- HTML 抽出ノード:
HTML 応答を解析し、ハイパーリンクを抽出するために使用されます。
- 関数ノード:
抽出されたリンクを Markdown 構文にフォーマットするために使用されます。
API キーが必要です
このワークフローが機能するには、API キー、資格情報、または認証構成は必要ありません。これは、指定された URL への HTTP リクエストにのみ基づいて動作するため、追加の設定なしで一般的に使用できます。