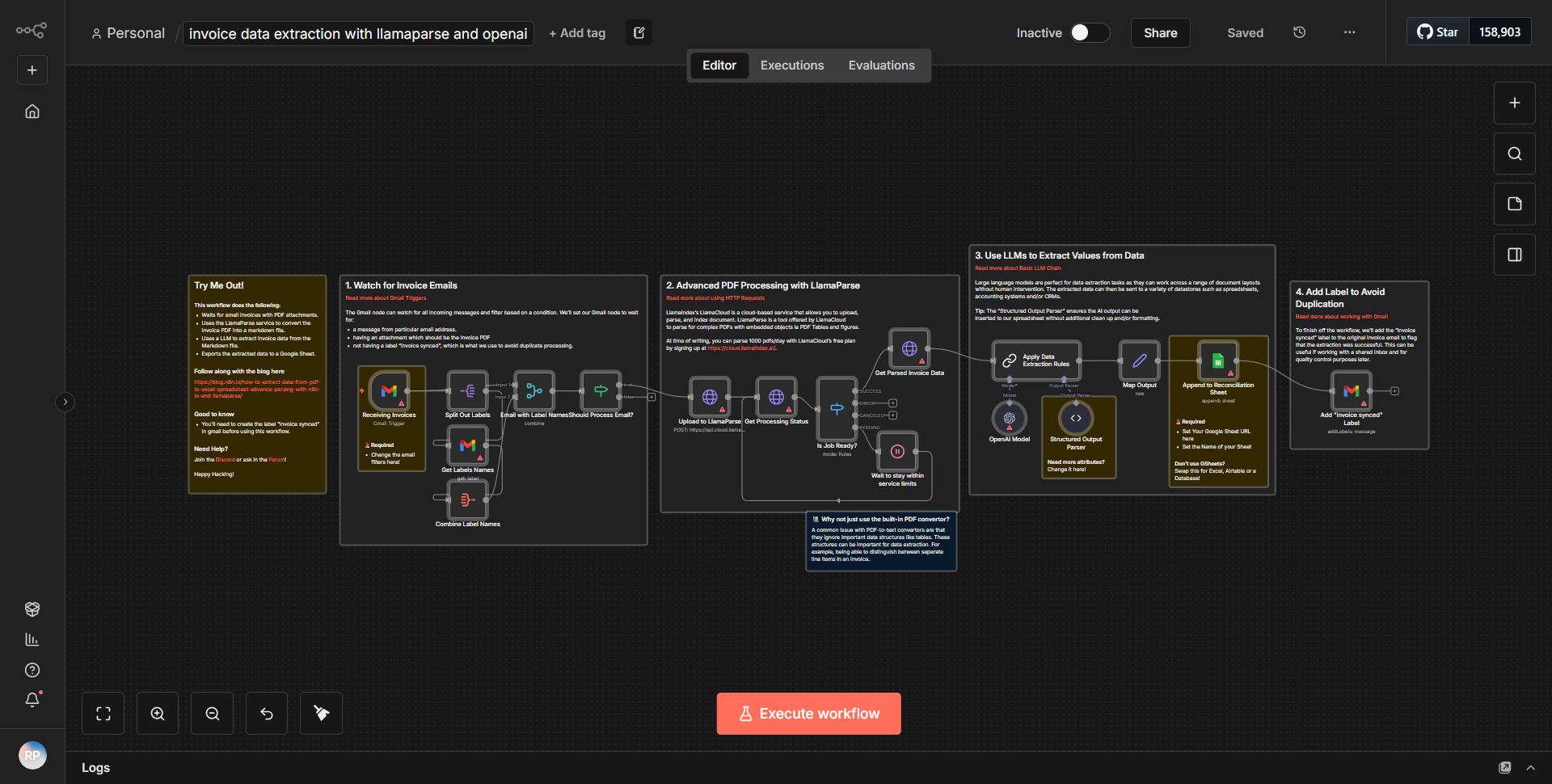
LlamaParse と OpenAI を使用した請求書情報の抽出
このワークフローは、LlamaParse と OpenAI を利用して請求書から組織化されたデータを抽出し、続いて構造化出力パーサーを使用して請求書から包括的な詳細を取得します。
仕組み
このワークフローは、LlamaParse と OpenAI を使用して請求書から構造化データを抽出するように設計されています。このプロセスは請求書ドキュメントの入力から始まり、その後一連のノードを通じて処理されて関連情報が抽出されます。
1. 開始ノード:
ワークフローは、受信請求書データをリッスンするトリガー ノードから開始されます。これは、アップロードされたファイルまたは請求書ドキュメントへのリンクの形式で行うことができます。
2. LlamaParse ノード:
最初の処理ステップには、請求書の内容を解析する役割を担う LlamaParse ノードが含まれます。請求書番号、日付、金額、ベンダー情報などの重要な要素を抽出します。このノードからの出力は、請求書から抽出されたデータの構造化表現です。
3. OpenAI ノード:
解析に続いて、ワークフローは OpenAI ノードを利用して、抽出されたデータをさらに分析および調整します。このノードは自然言語処理機能を採用して、情報の正確性と完全性を高めます。また、解析されたデータに基づいて追加のコンテキストや洞察が生成される場合もあります。
4. 構造化出力パーサー ノード:
ワークフローの最後のステップは、データを包括的な形式に編成する構造化出力パーサー ノードです。このノードにより、抽出された情報が明確かつ使用可能な方法で表示され、ユーザーがデータに簡単にアクセスして利用できるようになります。
5. 終了ノード:
ワークフローは、データ抽出プロセスの完了を示す終了ノードで終了します。整理されたデータは、データベース、電子メール、または別のアプリケーションに送信してさらに使用できます。
主な機能
- 自動データ抽出:
ワークフローにより、請求書からデータを抽出するプロセスが自動化され、手作業が軽減され、エラーが最小限に抑えられます。
- LlamaParse および OpenAI との統合:
解析には LlamaParse の機能、自然言語処理には OpenAI の機能を活用することで、ワークフローは請求書データの高精度で状況に応じた理解を保証します。
- 構造化出力:
構造化出力パーサーを使用すると、抽出されたデータを読みやすく他のシステムに統合できる方法で編成できます。
- 拡張性:
このワークフローは複数の請求書を同時に処理できるため、大量の請求書処理を行う企業に適しています。
- カスタマイズ可能:
ユーザーは、特定の請求書の形式や追加のデータ抽出ニーズに合わせてワークフローを調整できます。
ツールの統合
- LlamaParse ノード:
請求書の内容を解析して主要なデータ ポイントを抽出するために使用されます。
- OpenAI ノード:
抽出されたデータを自然言語処理によって強化するために採用されます。
- 構造化出力パーサー ノード:
抽出された情報を構造化出力にフォーマットするために使用されます。
- トリガー ノード:
受信した請求書データに基づいてワークフローを開始します。
API キーが必要です
- OpenAI API キー:
データ拡張のための OpenAI サービスへのリクエストを認証するために必要です。
- LlamaParse API キー:
該当する場合、LlamaParse 機能にアクセスするために API キーが必要になる場合があります。
ワークフローでは他の API キーや認証資格情報が指定されていないため、主な依存関係が LlamaParse および OpenAI との統合を中心に展開していることがわかります。