Gotenberg を使用して履歴書から情報を取得し、PDF を生成します。
このワークフローでは、AI を利用して履歴書から整理された情報を抽出し、それを HTML 形式に変換し、その後、Gotenberg を使用して適切な形式の PDF を作成します。
仕組み
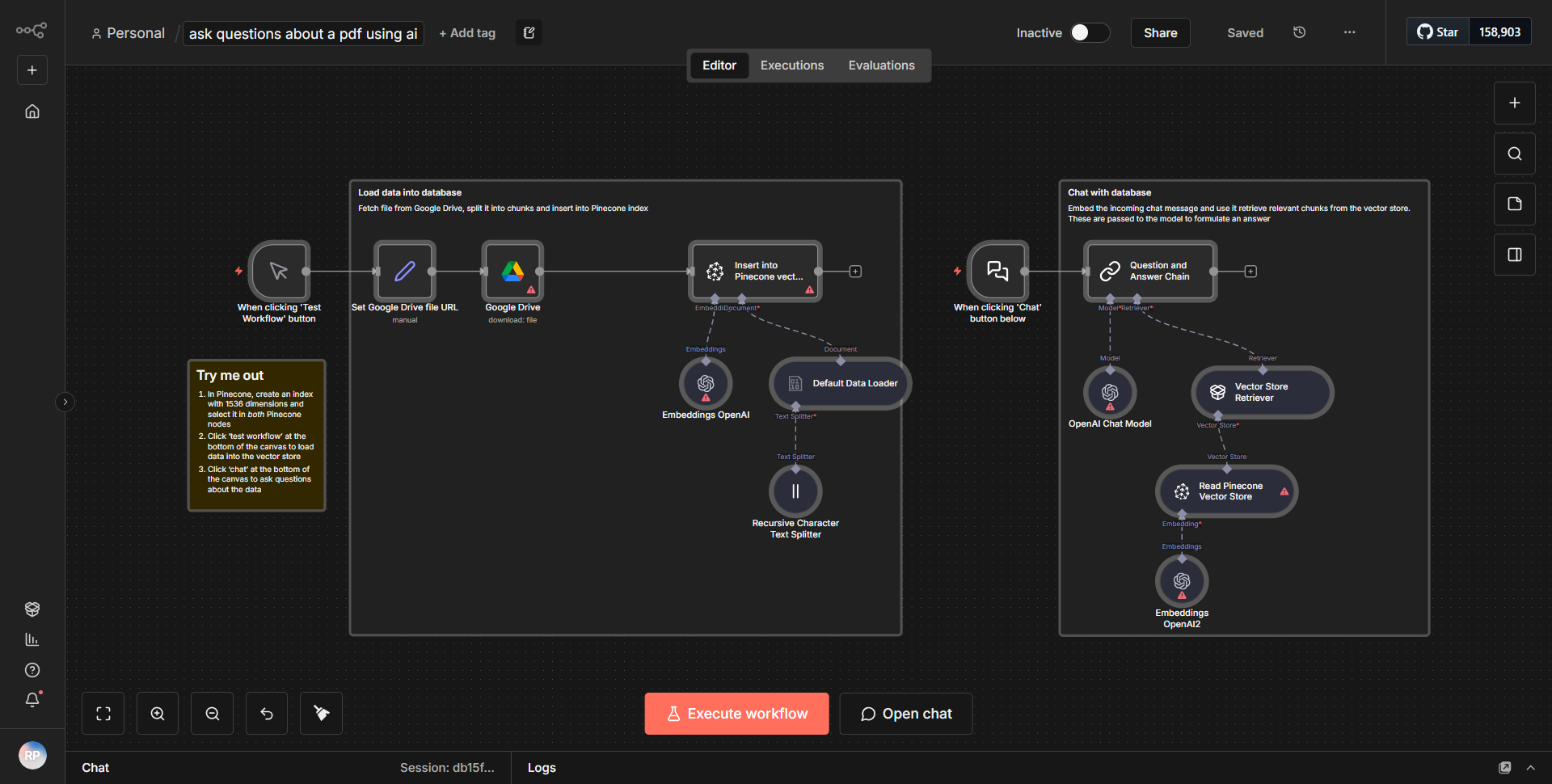
このワークフローは、履歴書から構造化情報を抽出し、Gotenberg を使用して適切にフォーマットされた PDF に変換するように設計されています。このプロセスは、通常は文書形式の履歴書の入力から始まります。ワークフローは、新しい履歴書の送信をリッスンするトリガー ノードによって開始されます。履歴書を受信すると、ワークフローはいくつかの主要なノードを通過して進みます。
1. バイナリ ファイル読み取りノード:
このノードは、アップロードされた履歴書ファイルを読み取る役割を果たします。ドキュメントのバイナリ データをキャプチャします。これは、さらなる処理に不可欠です。
2. 関数ノード:
ファイルを読み取った後、ワークフローは関数ノードを利用してバイナリ データを処理します。このノードは、個人の詳細、職歴、学歴などの関連情報を履歴書から抽出します。抽出されたデータは、構造化された形式 (通常は JSON) に編成されます。
3. HTML ノード:
構造化データは HTML ノードに渡され、そこで HTML 形式に変換されます。このステップは、PDF 生成用のコンテンツを準備し、レイアウトとスタイルが最終ドキュメントに適切であることを確認するため、非常に重要です。
4. Gotenberg ノード:
HTML 出力は Gotenberg ノードに送信され、HTML コンテンツを PDF に変換します。 Gotenberg は、HTML のレンダリングを処理し、HTML で指定された書式設定とデザインを保持した PDF ドキュメントを生成する強力なツールです。
5. 電子メール送信ノード (オプション):
最後に、生成された PDF は、電子メール送信ノードを使用して電子メールで送信できます。この手順により、対象の受信者に履歴書を PDF 形式で簡単に配布できるようになります。
このワークフロー全体を通じて、データは 1 つのノードから次のノードにシームレスに流れ、各段階で情報が正確に処理および変換されることが保証されます。
主な機能
- AI を活用したデータ抽出:
ワークフローは AI 技術を活用して履歴書から関連情報をインテリジェントに抽出し、重要な詳細が正確に取得されるようにします。
- HTML から PDF への変換:
PDF を生成する前に構造化データを HTML に変換することにより、ワークフローでレイアウトとスタイルをカスタマイズできるため、プロフェッショナルな外観のドキュメントが得られます。
- Gotenberg とのシームレスな統合:
PDF 生成に Gotenberg を使用すると、高品質の出力が保証され、さまざまな HTML 機能がサポートされるため、ドキュメント作成のための堅牢なソリューションになります。
- 電子メール配布:
オプションの電子メール機能を使用すると、ユーザーは生成された PDF 履歴書を簡単に共有でき、求職者の応募プロセスを効率化できます。
- モジュラー設計:
ワークフローのモジュラー構造により、簡単な変更と拡張が可能になり、ユーザーが特定のニーズに適応できるようになります。
ツールの統合
ワークフローには、次のツールとサービスが統合されています。
- n8n:
ワークフローを調整するために使用される主要な自動化プラットフォーム。
- Gotenberg:
HTML コンテンツを PDF 形式に変換するドキュメント変換ツール。
- 関数ノード:
カスタム JavaScript コードを実行してデータを操作できるようにする組み込みの n8n ノード。
- バイナリ ファイル読み取りノード:
アップロードされたファイルのバイナリ データを読み取るために使用されるノード。
- HTML ノード:
PDF 生成用にデータを HTML にフォーマットするノード。
- 電子メール送信ノード:
生成された PDF を添付して電子メールを送信するためのオプションのノード。
API キーが必要です
このワークフローが機能するには、API キーや認証資格情報は必要ありません。使用されるすべてのノードは組み込みの n8n ノードであるか、追加の認証を必要とせずに Gotenberg と統合されます。