AIを活用したPDFに関するお問い合わせ
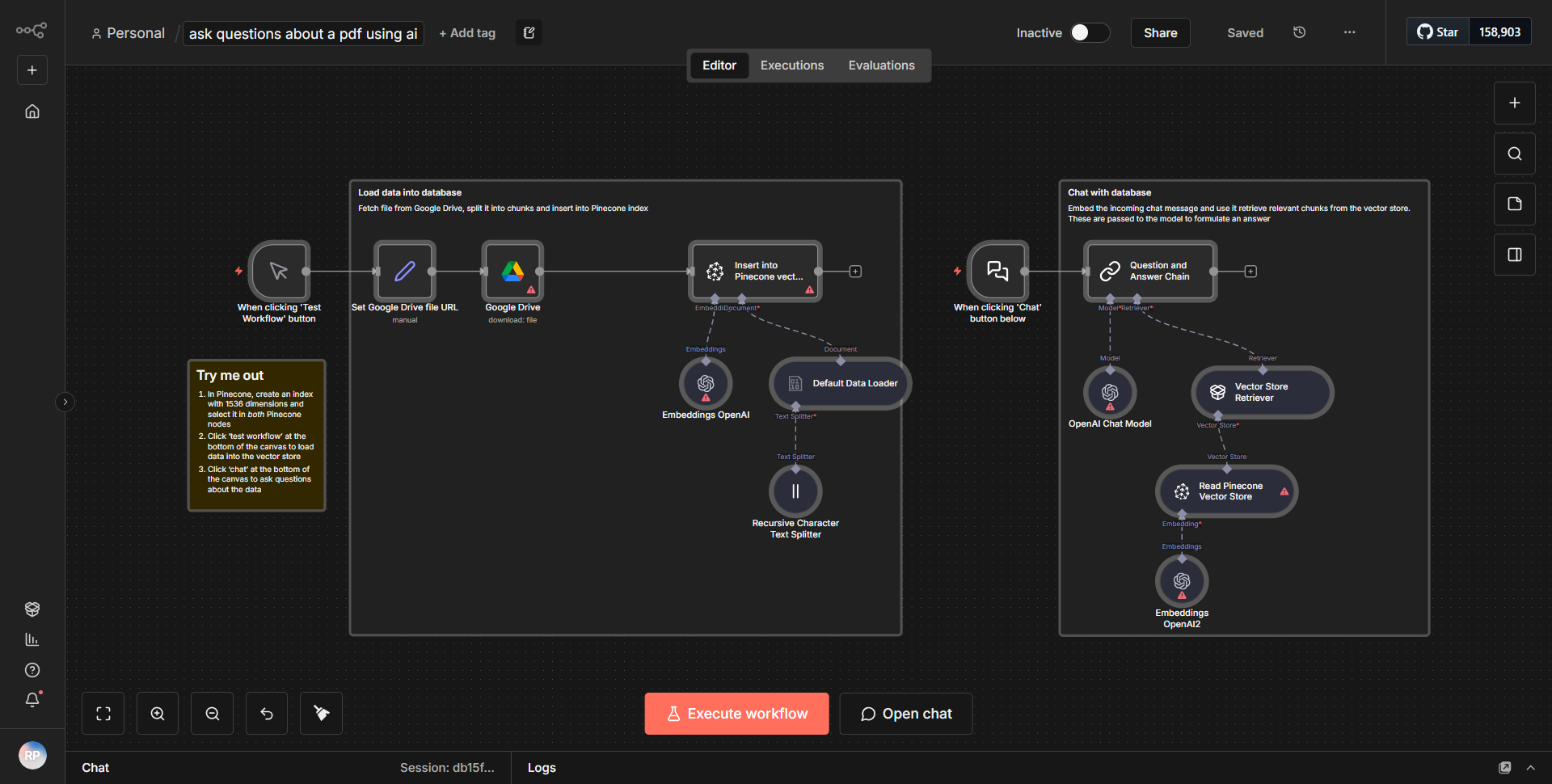
このワークフローは、Google ドライブから PDF ファイルを取得し、セグメントに分割し、OpenAI 埋め込みを使用してセグメントを処理し、ドキュメントのコンテンツとの会話による対話を容易にします。
仕組み
このワークフローは、Google ドライブ ノードを使用して Google ドライブから PDF ファイルを取得することから始まります。このノードは、名前または ID に基づいて特定のファイルを検索するように構成されており、正しいドキュメントにアクセスできるようになります。 PDF が取得されると、ワークフローは「PDF 抽出」ノードに進み、PDF ファイルからテキスト コンテンツを抽出します。この抽出されたテキストは、処理を容易にするために小さな部分に分割されます。
抽出とセグメンテーションに続いて、ワークフローは OpenAI ノードを利用してテキストの各セグメントの埋め込みを生成します。このステップは、テキスト データを AI アルゴリズムが理解して処理できる形式に変換するため、非常に重要です。埋め込みにより、ドキュメントのコンテンツに対するより効率的なクエリと対話が可能になります。
埋め込みが作成された後、ワークフローには会話型インターフェイスが組み込まれ、ユーザーは PDF のコンテンツについて質問できるようになります。これは、ユーザー入力を処理し、クエリを処理し、以前に生成された埋め込みに基づいて関連する応答を返す一連のノードを通じて実現されます。このワークフローは、ユーザーの問い合わせを継続的に処理できるループを効果的に作成し、PDF コンテンツのインタラクティブなエクスペリエンスを可能にします。
主な機能
1. PDF 取得:
ワークフローは Google ドライブとシームレスに統合して PDF ドキュメントを取得し、クラウドに保存されているファイルに簡単にアクセスできるようにします。
2. テキスト抽出:
専用ノードを使用して PDF ファイルからテキストを抽出し、すべての関連情報が処理に利用できるようにします。
3. コンテンツのセグメント化:
抽出されたテキストは管理可能なセグメントに分割されるため、AI 処理の効率が向上し、ユーザーのクエリに対するより正確な応答が可能になります。
4. AI 埋め込み:
OpenAI 埋め込みを利用することで、ワークフローはテキストをベクター形式に変換し、高度な AI 機能を使用してユーザーの問い合わせを理解して応答できるようにします。
5. 会話型インターフェイス:
ワークフローは動的な質問と回答の形式をサポートしており、ユーザーは PDF のコンテンツを対話的に操作できるため、PDF は情報の検索と学習のための強力なツールになります。
ツールの統合
- Google ドライブ:
PDF ファイルを取得するために使用されます。 Google ドライブ ノードは、ユーザー定義のパラメータに基づいて特定のファイルにアクセスするように構成されています。
- PDF 抽出:
このノードは PDF ドキュメントからテキストを抽出し、そのコンテンツがさらなる処理に利用できるようにします。
- OpenAI:
OpenAI ノードを利用して、抽出されたテキスト セグメントから埋め込みを生成し、高度な AI インタラクションを可能にします。
- Webhook:
このノードによりユーザー クエリの受信が可能になり、ワークフローの会話的な側面が容易になります。
API キーが必要です
このワークフローを操作するには、次の API キーと認証情報が必要です。
- Google ドライブ API キー:
Google ドライブに保存されているファイルの認証とアクセスに必要です。
- OpenAI API キー:
OpenAI サービスを利用して埋め込みを生成し、ユーザー クエリを処理するために必要です。
上記以外に追加の API キーや認証資格情報は必要ありません。