Flux de travail complet de Scraper pour n8n
Un workflow d'extraction de données complet pour n8n conçu pour collecter des informations provenant de plusieurs sources.
Comment ça marche
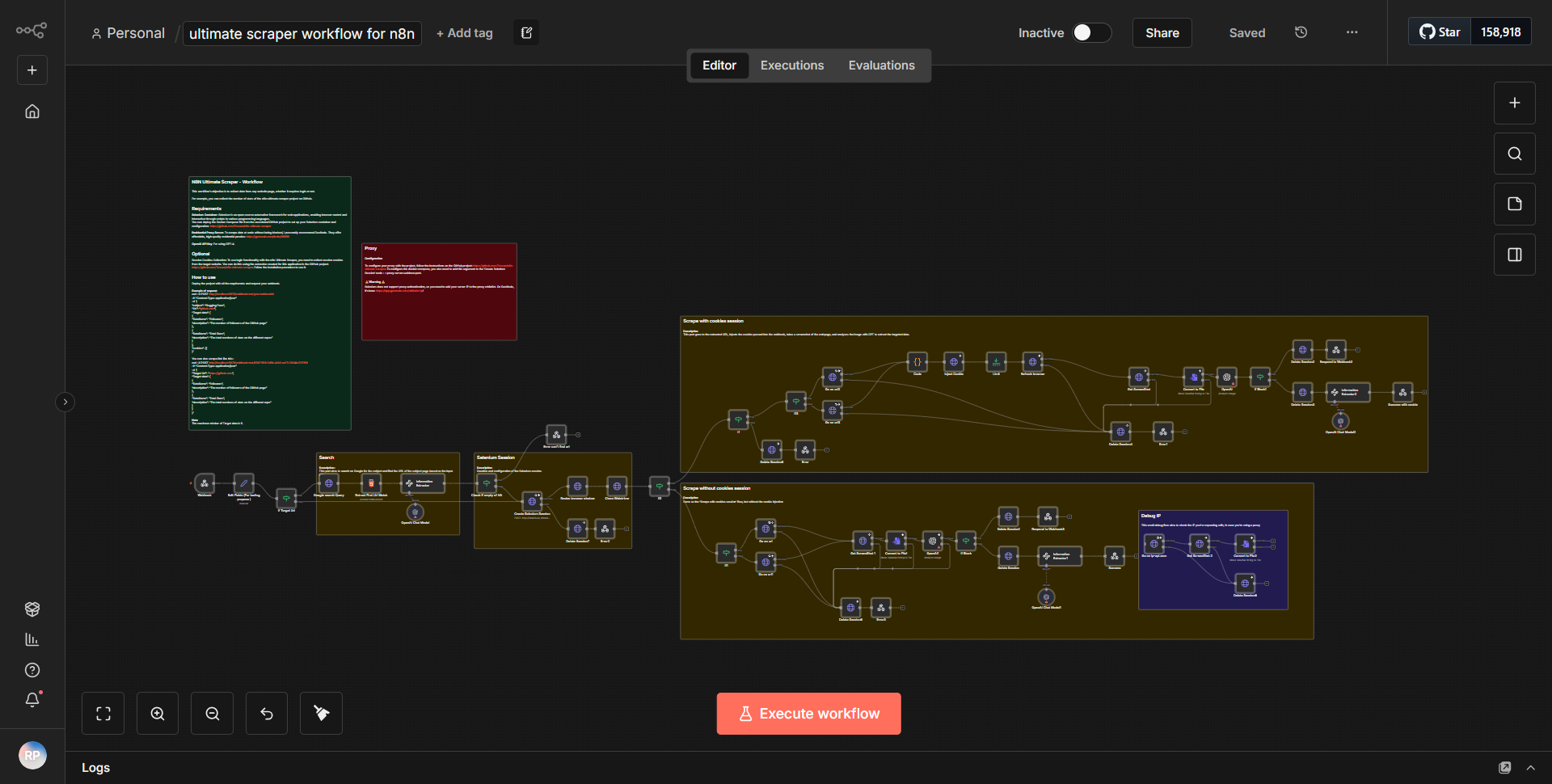
Le workflow complet de Scraper pour n8n est conçu pour extraire des données de plusieurs sources de manière structurée. Le workflow commence par un
nœud Cron
, qui déclenche le processus à des intervalles spécifiés. Ce nœud est configuré pour exécuter le flux de travail quotidiennement, garantissant que les données sont collectées régulièrement.Après le nœud Cron, le flux de travail utilise un
nœud de requête HTTP
pour récupérer les données à partir d'une URL spécifiée. Ce nœud est configuré pour effectuer une requête GET, lui permettant de récupérer le contenu HTML de la page Web cible. La sortie de ce nœud est ensuite transmise à unnœud d'extraction HTML
, qui est chargé d'analyser le contenu HTML et d'extraire les points de données pertinents en fonction de sélecteurs prédéfinis.Une fois les données extraites, elles sont envoyées à un
nœud Set
où elles sont formatées et organisées dans une structure plus gérable. Ce nœud permet de renommer les champs et d'ajuster le format des données si nécessaire. Les données traitées sont ensuite dirigées vers unnœud de fonction
, qui peut effectuer des transformations ou des calculs supplémentaires sur les données, améliorant ainsi leur convivialité.Une fois les données transformées, elles sont envoyées à un
nœud de base de données
pour stockage. Ce nœud est configuré pour insérer les données dans une base de données spécifiée, garantissant que les informations extraites sont enregistrées pour référence future. Enfin, le workflow se termine par unnœud Webhook
, qui peut être utilisé pour notifier d'autres services ou déclencher des actions supplémentaires en fonction de l'achèvement du processus d'extraction de données.Principales fonctionnalités
1. Extraction automatisée des données :
le flux de travail automatise le processus d'extraction des données à partir de plusieurs sources, réduisant ainsi les efforts manuels et augmentant l'efficacité.
2. Planification personnalisable :
Avec le nœud Cron, les utilisateurs peuvent facilement personnaliser la fréquence d'extraction des données, garantissant ainsi que les dernières informations sont toujours disponibles.
3. Analyse flexible des données :
le nœud HTML Extract permet une analyse flexible du contenu HTML, permettant aux utilisateurs de spécifier exactement les points de données à extraire en fonction de leurs besoins.
4. Capacités de transformation des données :
L'inclusion des nœuds Ensemble et Fonction permet une manipulation approfondie des données, garantissant que les données extraites sont dans le format souhaité avant le stockage.
5. Intégration avec les bases de données :
le flux de travail s'intègre de manière transparente aux bases de données, permettant un stockage et une récupération faciles des données extraites.
6. Système de notification :
le nœud Webhook fournit un mécanisme permettant de notifier d'autres services ou de déclencher des flux de travail supplémentaires, améliorant ainsi la fonctionnalité globale du système.
Intégration d'outils
Le workflow complet de Scraper s'intègre à plusieurs outils et services, en utilisant des nœuds spécifiques au sein de n8n :
- Nœud Cron :
pour planifier l'exécution du workflow.
- Nœud de requête HTTP :
pour récupérer des données à partir d'URL externes.
- Nœud d'extraction HTML :
pour analyser le contenu HTML et extraire des points de données spécifiques.
- Définir le nœud :
pour formater et organiser les données extraites.
- Nœud de fonction :
pour effectuer des transformations de données supplémentaires.
- Nœud de base de données :
Pour stocker les données extraites dans une base de données.
- Nœud Webhook :
pour envoyer des notifications ou déclencher d'autres workflows.
Clés API requises
Ce flux de travail ne nécessite aucune clé API ni identifiant d'authentification pour fonctionner. Tous les nœuds fonctionnent sur la base de données accessibles au public ou de configurations de bases de données locales.









