Analyse client à l'aide de Qdrant, Python et Data Extractor
Recueille des informations sur les clients grâce à l'utilisation de Qdrant, Python et d'un module d'extraction de données.
Comment ça marche
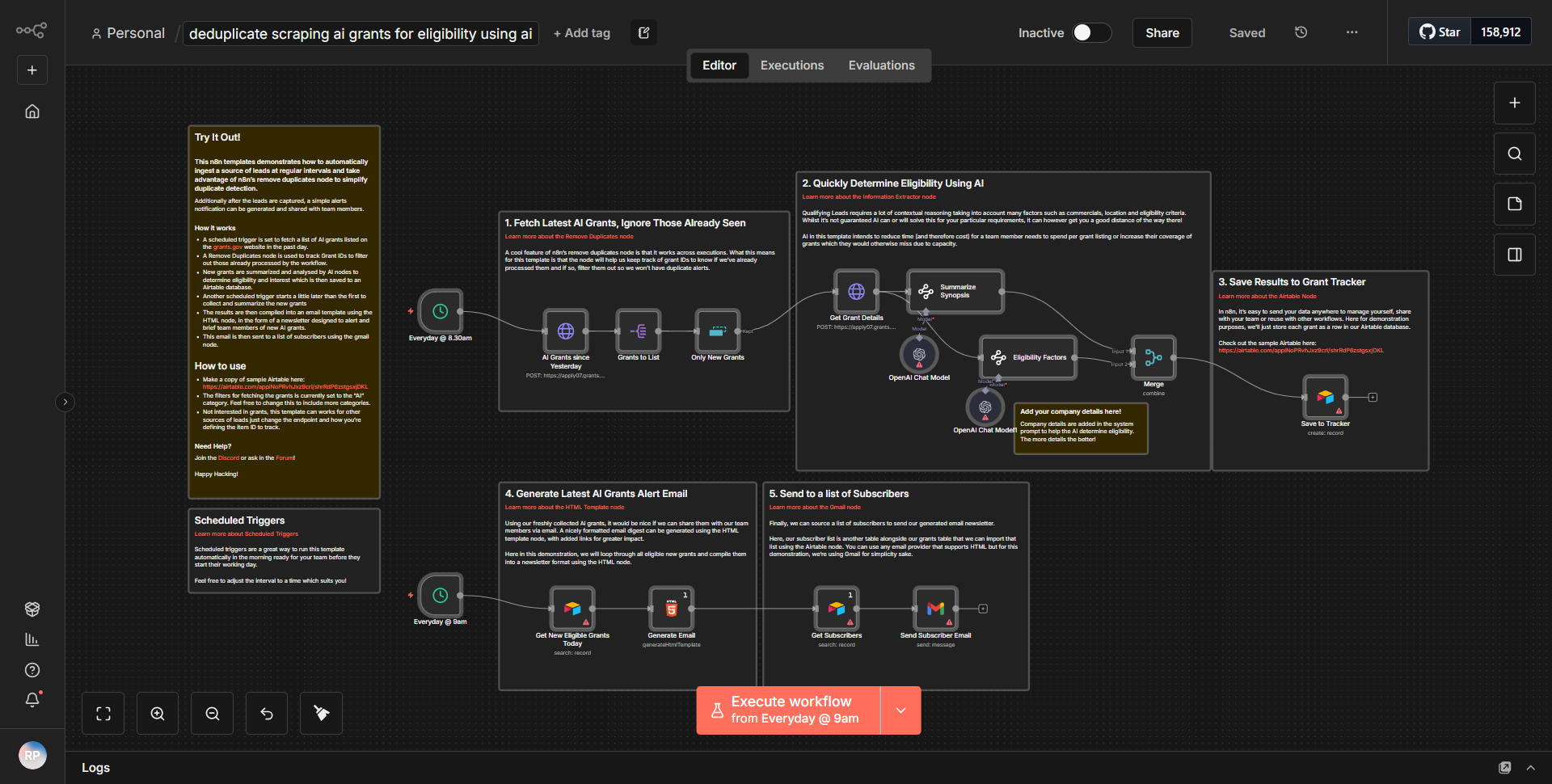
Le flux de travail intitulé « Analyse client utilisant Qdrant, Python et Data Extractor » est conçu pour recueillir des informations sur les clients en tirant parti des capacités de Qdrant, une base de données vectorielle, aux côtés de Python pour le traitement des données et d'un module d'extraction de données. Le flux de travail commence par un nœud déclencheur qui lance le processus, probablement en fonction d'un événement ou d'un calendrier spécifique.
1. Extraction de données :
le workflow commence par un nœud d'extraction de données qui récupère les données client à partir d'une source spécifiée. Cela pourrait impliquer la connexion à une base de données ou à une API pour extraire des informations client pertinentes.
2. Traitement des données avec Python :
une fois les données extraites, elles sont transmises à un nœud Python. Ici, des scripts Python personnalisés sont exécutés pour traiter davantage les données. Cela peut inclure le nettoyage des données, la transformation ou tout calcul analytique nécessaire pour préparer les données à l'analyse.
3. Intégration avec Qdrant :
Après le traitement, le workflow envoie les données préparées à un nœud Qdrant. Qdrant est utilisé pour stocker et gérer les représentations vectorielles des données client, permettant des recherches de similarité efficaces et la récupération d'informations basées sur des intégrations vectorielles.
4. Génération d'informations :
le flux de travail peut inclure des nœuds supplémentaires qui interrogent Qdrant pour générer des informations basées sur les données stockées. Cela pourrait impliquer d'effectuer des recherches de similarité pour identifier des modèles ou des tendances parmi les clients.
5. Sortie et reporting :
Enfin, le flux de travail se termine par un nœud de sortie qui formate les informations dans un rapport ou les envoie à un autre service pour une action ultérieure, comme notifier les parties prenantes ou stocker les résultats dans une base de données.
Tout au long de ce processus, les nœuds sont interconnectés pour garantir un flux transparent de données depuis l'extraction jusqu'à la génération d'informations, permettant une analyse complète des données client.
Principales fonctionnalités
- Extraction de données :
le flux de travail peut extraire les données client de diverses sources, garantissant que l'analyse est basée sur les informations les plus pertinentes et les plus à jour.
- Traitement Python personnalisé :
l'intégration d'un nœud Python permet une manipulation et une analyse avancées des données, permettant aux utilisateurs de mettre en œuvre une logique personnalisée adaptée à leurs besoins spécifiques.
- Utilisation de la base de données vectorielles :
en utilisant Qdrant, le flux de travail bénéficie d'un stockage et d'une récupération efficaces de données de grande dimension, facilitant des informations rapides grâce à des recherches de similarité.
- Génération d'informations :
la capacité à générer des informations exploitables à partir des données clients aide les entreprises à comprendre le comportement et les préférences des clients, ce qui permet de prendre de meilleures décisions.
- Rapports automatisés :
le flux de travail peut formater et fournir automatiquement des informations, réduisant ainsi les efforts manuels et garantissant un accès rapide aux informations critiques.
Intégration d'outils
- Nœud d'extraction de données :
ce nœud est chargé de récupérer les données client à partir de diverses sources.
- Python Node :
utilisé pour exécuter des scripts personnalisés qui traitent les données extraites.
- Qdrant Node :
s'intègre à la base de données vectorielle Qdrant pour stocker et interroger les données client.
- Nœud de sortie :
formate et fournit les informations générées à partir de l'analyse.
Clés API requises
Le flux de travail ne spécifie aucune clé API ni identifiant d'authentification requis pour le fonctionnement. Toutefois, si l'extraction de données implique l'accès à des API ou à des bases de données externes, des informations d'identification appropriées peuvent être nécessaires, qui doivent être configurées dans les nœuds respectifs.