Flux de travail automatisé pour récupérer et catégoriser les résumés papier des câlins
Rationalise la récupération, le résumé et la classification des documents de recherche de Hugging Face.
Comment ça marche
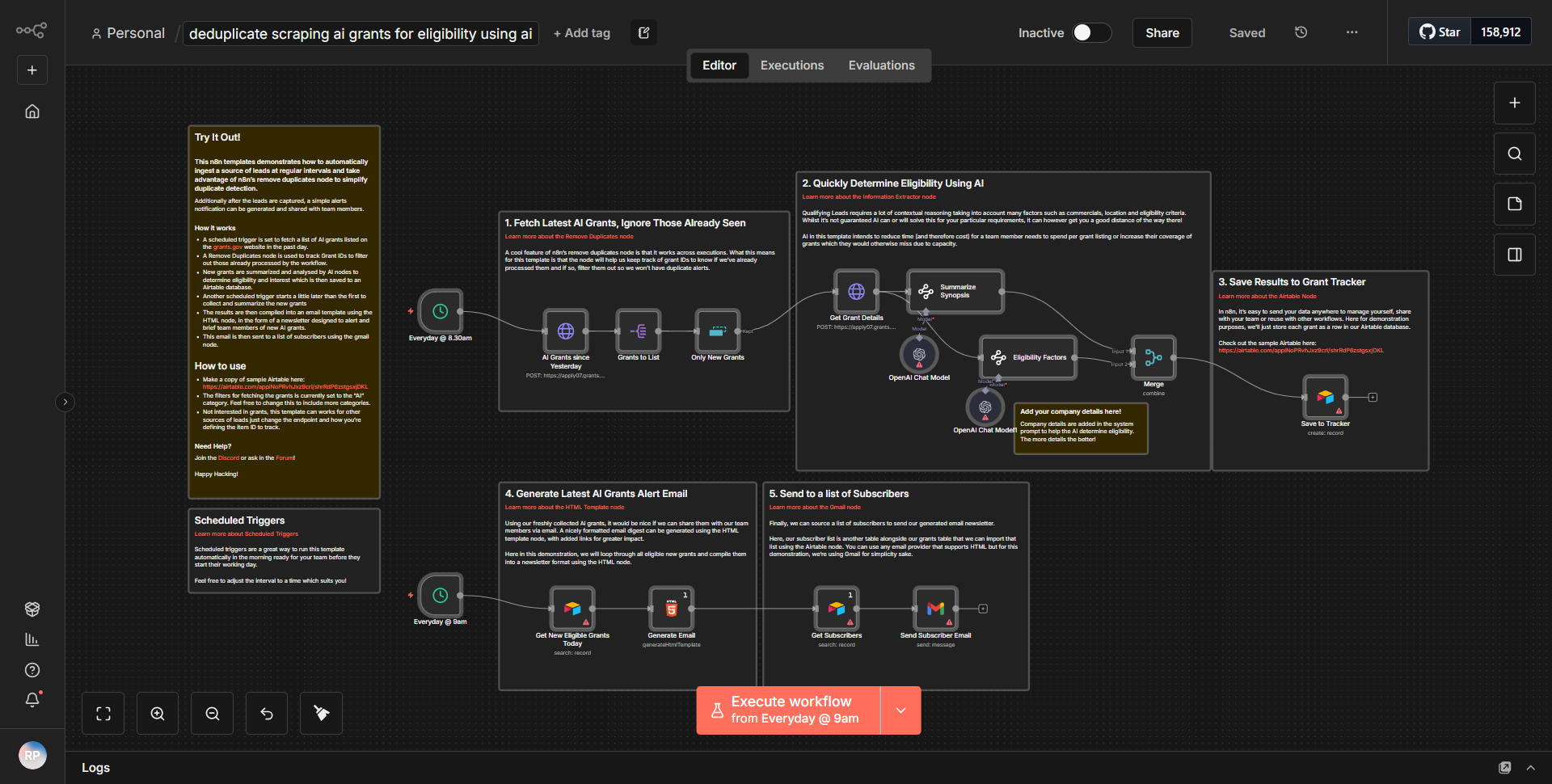
Le flux de travail intitulé « Flux de travail automatisé pour la récupération et la catégorisation des résumés papier de Hugging Face » est conçu pour rationaliser le processus de récupération, de synthèse et de catégorisation des documents de recherche de Hugging Face. Le flux de travail fonctionne via une série de nœuds interconnectés qui facilitent le flux et le traitement des données.
1. Nœud déclencheur :
le flux de travail commence par un nœud déclencheur qui lance le processus. Il peut s'agir d'un déclencheur planifié ou d'un déclencheur basé sur un événement, selon la configuration spécifique.
2. Nœud de requête HTTP :
le premier nœud opérationnel est un nœud de requête HTTP, qui envoie une requête à l'API Hugging Face pour récupérer une liste d'articles de recherche. Ce nœud est configuré avec le point de terminaison et les paramètres appropriés pour garantir qu'il récupère les données souhaitées.
3. Nœud de fonction :
après avoir récupéré les données, le flux de travail utilise un nœud de fonction pour traiter la réponse. Ce nœud extrait les informations pertinentes de la réponse de l'API, telles que les titres des articles, les résumés et les URL, et les prépare au résumé.
4. Nœud de résumé :
l'étape suivante implique un autre nœud de requête HTTP qui envoie les résumés extraits à une API de résumé. Ce nœud est chargé de générer des résumés concis des articles de recherche.
5. Nœud de catégorisation :
après le résumé, le flux de travail utilise un nœud de catégorisation, qui utilise probablement un modèle d'apprentissage automatique ou un ensemble prédéfini de catégories pour classer les articles résumés en fonction de leur contenu.
6. Nœud de sortie :
Enfin, le flux de travail se termine par un nœud de sortie qui formate les résultats pour la présentation ou le stockage. Cela pourrait impliquer l'envoi des résumés catégorisés vers une base de données, un courrier électronique ou un autre service pour une utilisation ultérieure.
Tout au long du flux de travail, les données circulent séquentiellement d'un nœud au suivant, chaque nœud remplissant une fonction spécifique qui contribue à l'objectif global de résumer et de catégoriser les articles de recherche.
Principales fonctionnalités
1. Récupération automatisée des données :
le flux de travail automatise le processus de récupération des documents de recherche à partir de Hugging Face, éliminant ainsi le besoin de collecte manuelle de données.
2. Capacité de résumé :
il comprend une fonction de résumé qui condense les longs résumés en résumés concis, permettant aux utilisateurs de saisir rapidement les points clés de chaque article.
3. Catégorisation :
le flux de travail catégorise les articles résumés, permettant aux utilisateurs de filtrer et d'organiser la recherche en fonction de sujets ou de thèmes spécifiques.
4. Intégration avec les API :
le flux de travail s'intègre de manière transparente aux API externes, tirant parti de leurs capacités pour améliorer le traitement et l'analyse des données.
5. Déclencheurs personnalisables :
les utilisateurs peuvent configurer des déclencheurs pour exécuter le flux de travail selon un calendrier ou en réponse à des événements spécifiques, offrant ainsi une flexibilité quant à la manière et au moment où le flux de travail fonctionne.
Intégration d'outils
Le flux de travail utilise plusieurs outils et intégrations, notamment :
- API Hugging Face :
pour récupérer des documents de recherche et éventuellement pour les résumer.
- Nœuds de requête HTTP :
utilisés pour interagir avec des API externes pour récupérer des documents et envoyer des données à des fins de résumé.
- Function Node :
Pour le traitement et la transformation des données entre les nœuds.
- Modèle de catégorisation :
il pourrait s'agir d'un modèle d'apprentissage automatique intégré au flux de travail pour classer les articles.
Clés API requises
Pour faire fonctionner ce workflow, les clés API et informations d'identification suivantes sont nécessaires :
1. Clé API Hugging Face :
requise pour authentifier les demandes adressées à l'API Hugging Face afin de récupérer des articles de recherche et éventuellement pour le service de synthèse.
2. Clé API de synthèse :
si un service de synthèse distinct est utilisé, une clé API pour ce service sera également nécessaire.
S'il n'y a pas de services supplémentaires nécessitant une authentification, il s'agira de la liste complète des clés API requises pour que le flux de travail fonctionne correctement.