Robot d'exploration Web IA autonome
Un grattoir Web autonome basé sur l'IA pour la collecte et l'analyse de données.
Comment ça marche
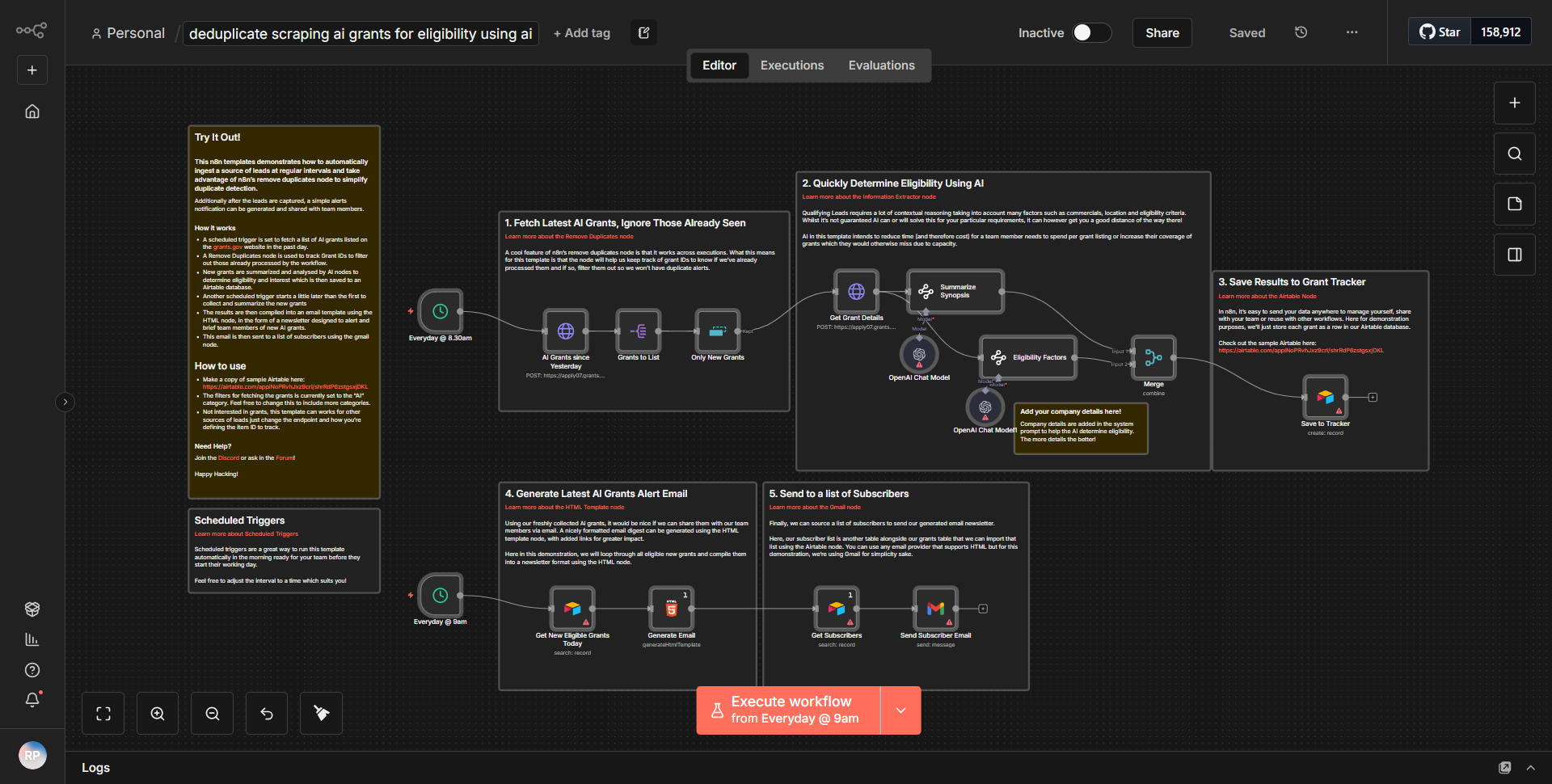
Le flux de travail « Auto-suffisant AI Web Crawler » fonctionne comme un grattoir Web autonome conçu pour collecter et analyser des données sur Internet. Le flux de travail commence par un nœud déclencheur qui lance le processus de scraping en fonction d'un calendrier ou d'un événement défini. Une fois déclenché, le workflow suit un flux systématique de données via différents nœuds.
1. Démarrer le nœud :
le flux de travail est lancé soit selon un planning, soit via un webhook, selon la configuration.
2. Nœud de requête HTTP :
ce nœud est responsable de l'envoi d'une requête au site Web cible. Il récupère le contenu HTML de l'URL spécifiée.
3. Nœud d'extraction HTML :
après avoir obtenu le contenu HTML, ce nœud analyse les données pour extraire des informations pertinentes telles que des titres, des liens ou des éléments de texte spécifiques en fonction de sélecteurs prédéfinis.
4. Nœud de fonction :
ce nœud traite davantage les données extraites, en appliquant toutes les transformations ou calculs nécessaires. Il peut également inclure une logique pour filtrer ou formater les données pour une meilleure convivialité.
5. Nœud de stockage de données :
les données traitées sont ensuite stockées dans une base de données ou un service cloud pour référence et analyse futures. Cela peut impliquer des nœuds tels que Google Sheets, Airtable ou une intégration de base de données personnalisée.
6. Nœud de notification :
Enfin, le flux de travail peut inclure un système de notification qui alerte l'utilisateur de l'achèvement de la tâche de scraping ou de toute découverte importante. Cela peut se faire par e-mail, Slack ou un autre service de messagerie.
Les nœuds sont interconnectés de manière linéaire, garantissant que les données circulent de manière transparente d'une étape à la suivante, permettant ainsi une collecte et un traitement efficaces des données.
Principales fonctionnalités
- Fonctionnement autonome :
le flux de travail est conçu pour s'exécuter sans intervention manuelle, ce qui le rend adapté à la collecte continue de données.
- Extraction de données :
capable d'extraire des points de données spécifiques à partir de pages Web à l'aide de sélecteurs personnalisables, permettant aux utilisateurs d'adapter le processus de scraping à leurs besoins.
- Traitement des données :
inclut des fonctionnalités de traitement et de transformation des données extraites, garantissant qu'elles sont dans un format utilisable pour l'analyse.
- Intégration du stockage :
prend en charge diverses solutions de stockage, permettant aux utilisateurs de sauvegarder leurs données dans des formats et emplacements préférés pour un accès et une analyse faciles.
- Système de notification :
fournit des alertes et des notifications à la fin des tâches ou lorsque des conditions spécifiques sont remplies, tenant les utilisateurs informés de l'état du flux de travail.
Intégration d'outils
Le workflow s'intègre à plusieurs outils et services pour améliorer ses fonctionnalités :
- Nœud de requête HTTP :
utilisé pour récupérer des données à partir de sites Web cibles.
- Nœud d'extraction HTML :
analyse le contenu HTML pour extraire les données pertinentes.
- Nœud de fonction :
effectue un traitement et des transformations de données personnalisées.
- Nœuds de base de données :
s'intègre à des services tels que Google Sheets ou Airtable pour le stockage de données.
- Nœuds de notification :
envoie des alertes par e-mail ou sur des plateformes de messagerie comme Slack.
Clés API requises
Aucune clé API ou identifiant d'authentification n'est requis pour les fonctionnalités de base de ce flux de travail. Cependant, si le flux de travail s'intègre à des services spécifiques (comme Google Sheets ou Airtable), les utilisateurs devront fournir les clés API ou les jetons d'authentification nécessaires pour ces services afin de permettre le stockage et la récupération des données.