返回列表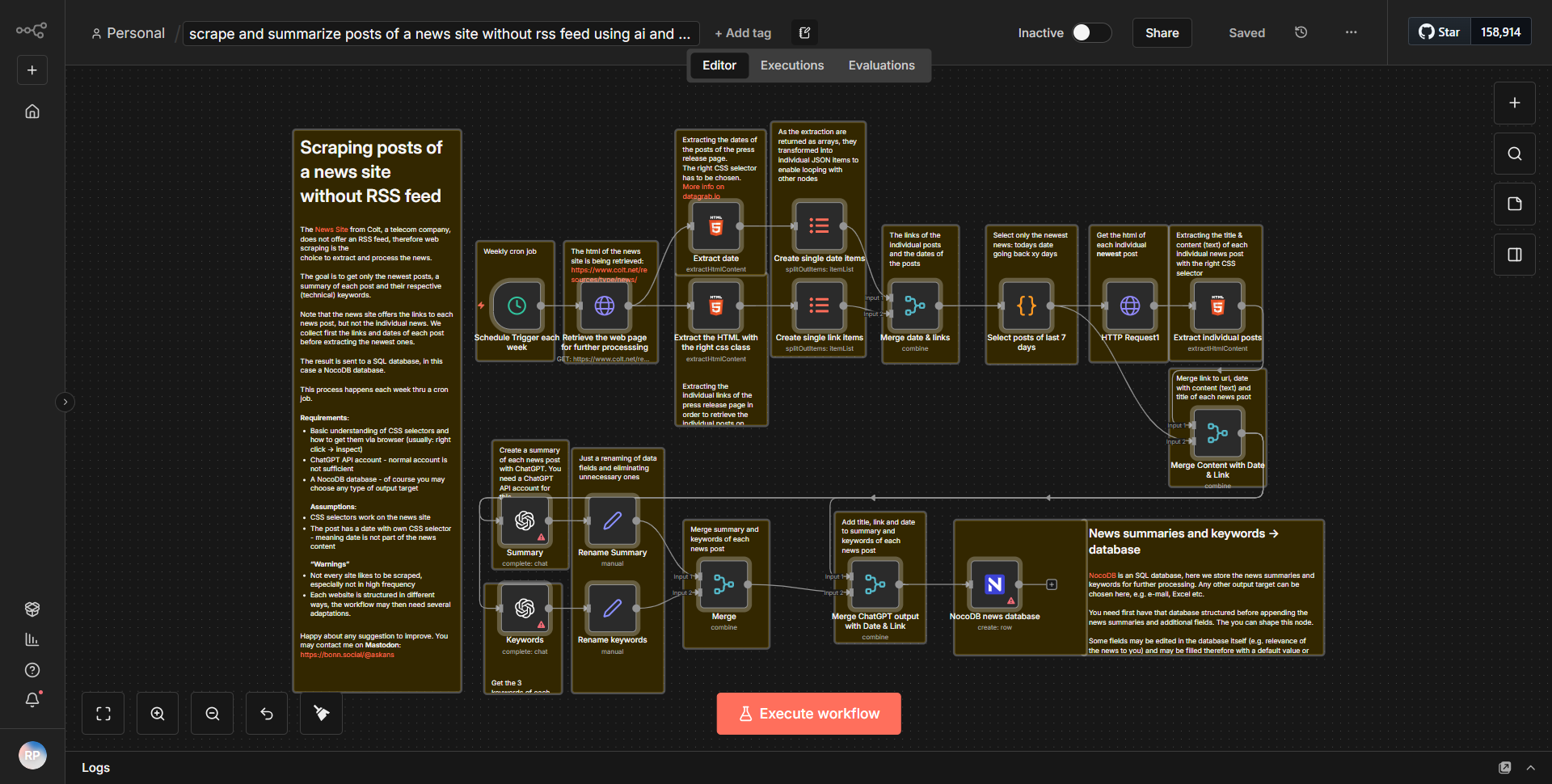
该工作流从
在 HTTP 请求节点之后,有一个
接下来,工作流包括一个
工作流程的最后一步是
利用 AI 从缺乏 RSS 提要的新闻网站中提取并压缩文章,并将结果存储在 NocoDB 中。
Content Curation, Data Management
利用AI提取并压缩缺少RSS源的新闻文章,并将结果存储在NocoDB中。
它是如何运作的
该工作流从
HTTP 请求
节点开始,该节点配置为获取不提供 RSS 源的指定新闻网站的 HTML 内容。该节点设置为对目标 URL 执行 GET 请求,检索整个页面内容。该节点的输出是原始 HTML,然后传递到下一个节点进行处理。在 HTTP 请求节点之后,有一个
HTML Extract
节点。该节点负责解析上一步检索到的 HTML 内容。它利用 CSS 选择器从 HTML 中识别和提取特定元素,例如文章标题、发布日期和文章正文。提取的数据以更易于管理的格式构建,通常为 JSON。接下来,工作流包括一个
Function
节点,用于进一步处理提取的数据。在这个节点中,文章是利用AI技术进行浓缩的。这可能涉及总结内容或提取要点,具体取决于具体实现。该节点的输出是文章的摘要版本,可供存储。工作流程的最后一步是
NocoDB
节点,用于将摘要文章存储在 NocoDB 数据库中。该节点被配置为在指定表中创建新记录,其中每条记录对应于一篇摘要文章。发送到 NocoDB 的数据包括标题、摘要以及之前提取的任何其他相关元数据。在整个工作流程中,数据按顺序从一个节点流向下一个节点,将原始 HTML 转换为存储在数据库中的结构化汇总内容,以便于访问和管理。
主要特点
1. 人工智能摘要
:工作流程利用人工智能技术将冗长的文章浓缩为简洁的摘要,使用户更容易快速掌握基本信息。
2. HTML 内容提取
:通过直接从缺乏 RSS 源的网站中抓取 HTML 内容,工作流程可以从各种来源收集新闻文章,否则这些来源将无法访问。
3. 与NocoDB集成
:在NocoDB中存储摘要文章的能力可以实现有组织的数据管理和轻松检索,从而促进进一步的分析或报告。
4. 可自定义的数据提取
:在 HTML Extract 节点中使用 CSS 选择器使用户能够自定义他们希望提取的文章中的哪些元素,从而根据不同的网站结构提供灵活性。
5. 自动化工作流程
:整个过程自动化,减少了手动数据收集和汇总的需要,从而为用户节省了时间和精力。
工具集成
- HTTP请求节点
:用于从指定的新闻网站获取HTML内容。
- HTML 提取节点
:解析 HTML 并使用 CSS 选择器提取相关文章数据。
- 功能节点
:处理提取的数据并利用AI进行汇总。
- NocoDB节点
:将摘要文章存储在NocoDB数据库中以进行结构化数据管理。
需要 API 密钥
此工作流程无需 API 密钥或身份验证凭据即可运行。所使用的节点无需外部API访问即可运行,仅依靠对新闻网站的HTTP请求以及与NocoDB的集成进行数据存储。









