自给自足的AI网络爬虫
一个自给自足的人工智能驱动的网络爬虫,用于收集和分析数据。
它是如何运作的
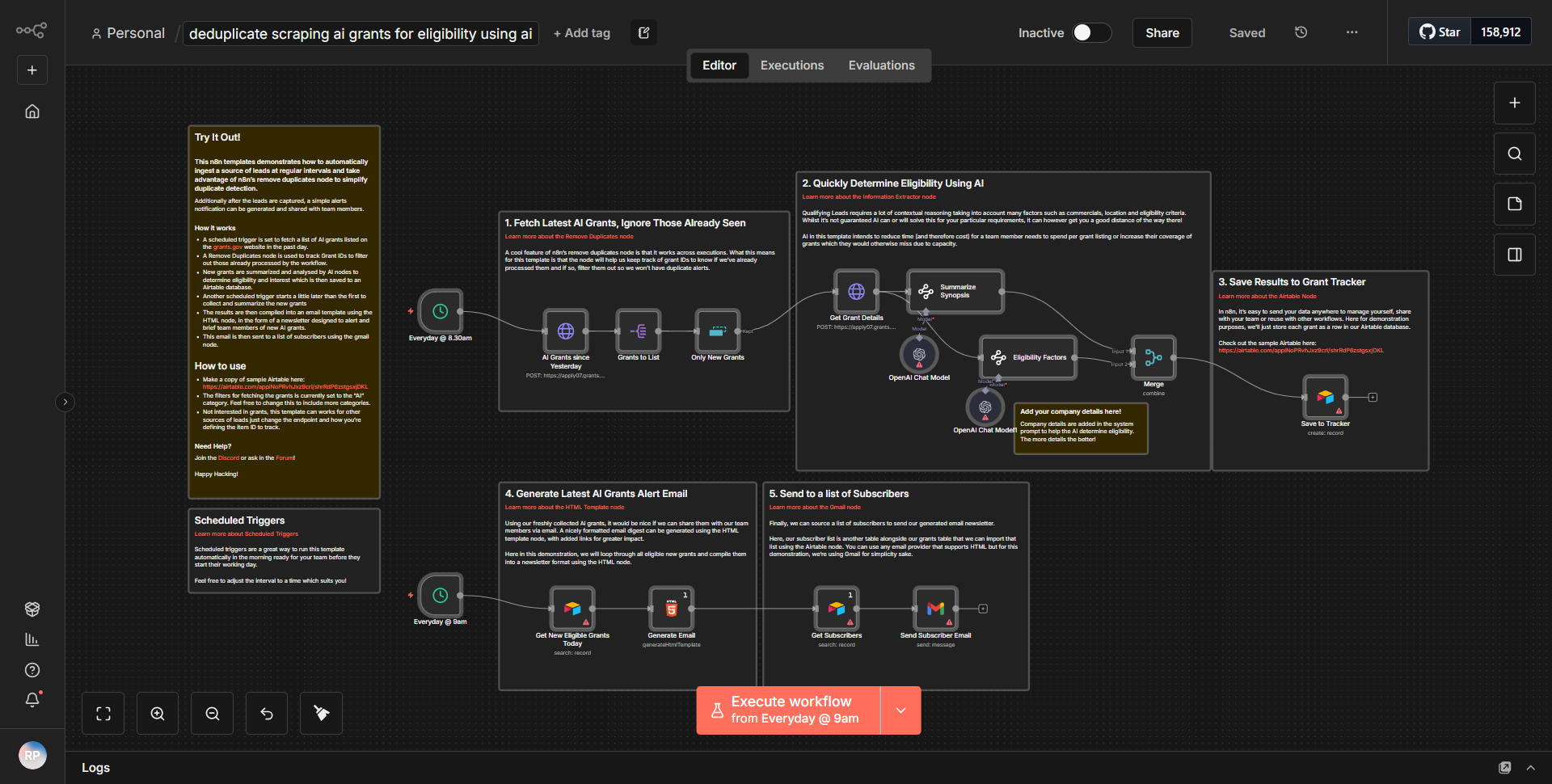
“自给自足的人工智能网络爬虫”工作流程作为一个自主的网络爬虫运行,旨在收集和分析来自互联网的数据。工作流程从触发器节点开始,该节点根据定义的计划或事件启动抓取过程。一旦触发,工作流程就会遵循通过各个节点的系统数据流。
1. 启动节点
:工作流按照计划或通过 Webhook 启动,具体取决于配置。
2. HTTP请求节点
:该节点负责向目标网站发送请求。它检索指定 URL 的 HTML 内容。
3. HTML提取节点
:获取HTML内容后,该节点解析数据,根据预定义的选择器提取相关信息,例如标题、链接或特定文本元素。
4. 函数节点
:该节点进一步处理提取的数据,应用任何必要的转换或计算。它还可能包括过滤或格式化数据的逻辑,以获得更好的可用性。
5. 数据存储节点
:处理后的数据将存储在数据库或云服务中,以供将来参考和分析。这可能涉及 Google Sheets、Airtable 或自定义数据库集成等节点。
6. 通知节点
:最后,工作流程可能包括一个通知系统,用于提醒用户抓取任务的完成或任何重要的发现。这可以通过电子邮件、Slack 或其他消息服务进行。
节点以线性方式互连,确保数据从一个步骤无缝流向下一步,从而实现高效的数据收集和处理。
主要特点
- 自主操作
:工作流程设计为无需人工干预即可运行,使其适合连续数据收集。
- 数据提取
:能够使用可自定义的选择器从网页中提取特定的数据点,允许用户根据自己的需求定制抓取过程。
- 数据处理
:包括处理和转换提取的数据的功能,确保其采用可用于分析的格式。
- 存储集成
:支持各种存储解决方案,使用户能够以首选格式和位置保存数据,以便于访问和分析。
- 通知系统
:在完成任务或满足特定条件时提供警报和通知,让用户了解工作流程的状态。
工具集成
该工作流程与多种工具和服务集成以增强其功能:
- HTTP请求节点
:用于从目标网站获取数据。
- HTML 提取节点
:解析 HTML 内容以提取相关数据。
- 功能节点
:执行自定义数据处理和转换。
- 数据库节点
:与 Google Sheets 或 Airtable 等服务集成以进行数据存储。
- 通知节点
:通过电子邮件或 Slack 等消息平台发送警报。
需要 API 密钥
此工作流程的基本功能不需要 API 密钥或身份验证凭据。但是,如果工作流程与特定服务(例如 Google Sheets 或 Airtable)集成,则用户将需要为这些服务提供必要的 API 密钥或身份验证令牌,以实现数据存储和检索。