返回列表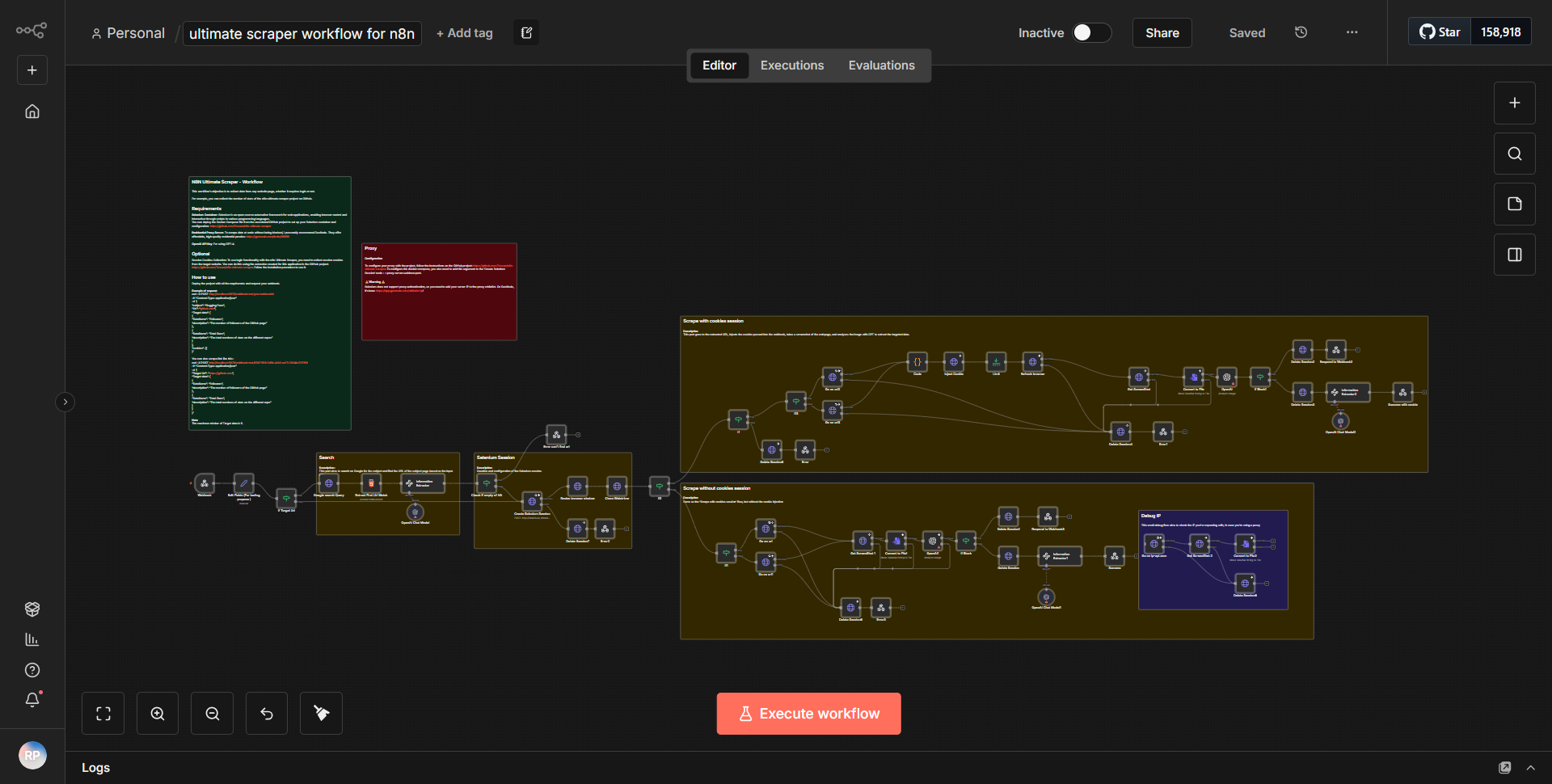
n8n 的综合 Scraper 工作流程旨在以结构化方式从多个来源提取数据。工作流程以
在 Cron 节点之后,工作流利用
提取数据后,它会被发送到
数据转换后,将被发送到
n8n 的综合抓取工作流程
Data Collection, Automation
n8n 的广泛数据提取工作流程旨在从多个来源收集信息。
它是如何运作的
n8n 的综合 Scraper 工作流程旨在以结构化方式从多个来源提取数据。工作流程以
Cron 节点
开始,该节点以指定的时间间隔触发该流程。该节点配置为每天运行工作流,确保定期收集数据。在 Cron 节点之后,工作流利用
HTTP 请求节点
从指定的 URL 获取数据。该节点配置为执行 GET 请求,允许其检索目标网页的 HTML 内容。然后,该节点的输出被传递到HTML Extract 节点
,该节点负责解析 HTML 内容并根据预定义的选择器提取相关数据点。提取数据后,它会被发送到
Set 节点
,在那里数据被格式化并组织成更易于管理的结构。该节点允许根据需要重命名字段并调整数据格式。然后,处理后的数据被定向到函数节点
,该节点可以对数据执行额外的转换或计算,从而增强其可用性。数据转换后,将被发送到
数据库节点
进行存储。该节点被配置为将数据插入到指定的数据库中,确保提取的信息被保存以供将来参考。最后,工作流程以Webhook 节点
结束,该节点可用于通知其他服务或根据数据提取过程的完成情况触发其他操作。主要特点
1. 自动数据提取
:该工作流程自动执行从多个来源提取数据的过程,减少了手动工作并提高了效率。
2. 可定制的调度
:通过Cron节点,用户可以轻松定制数据提取的频率,确保最新信息始终可用。
3. 灵活的数据解析
:HTML Extract 节点允许灵活解析 HTML 内容,使用户能够根据需要准确指定提取哪些数据点。
4. 数据转换功能
:集合和函数节点的包含允许进行广泛的数据操作,确保提取的数据在存储之前采用所需的格式。
5. 与数据库集成
:工作流程与数据库无缝集成,可以轻松存储和检索提取的数据。
6. 通知系统
:Webhook节点提供了通知其他服务或触发额外工作流程的机制,增强系统的整体功能。
工具集成
综合 Scraper 工作流程与多种工具和服务集成,利用 n8n 中的特定节点:
- Cron 节点
:用于安排工作流程执行。
- HTTP 请求节点
:用于从外部 URL 获取数据。
- HTML 提取节点
:用于解析 HTML 内容并提取特定数据点。
- 设置节点
:用于格式化和组织提取的数据。
- 功能节点
:用于执行附加数据转换。
- 数据库节点
:用于将提取的数据存储在数据库中。
- Webhook 节点
:用于发送通知或触发其他工作流程。
需要 API 密钥
此工作流程不需要任何 API 密钥或身份验证凭据即可运行。所有节点都基于可公开访问的数据或本地数据库配置进行操作。









