Recupere datos de Perplexity AI dentro de sus flujos de trabajo n8n.
Incorpora Perplexity AI en los flujos de trabajo n8n para mejorar las funcionalidades de consulta.
Cómo funciona
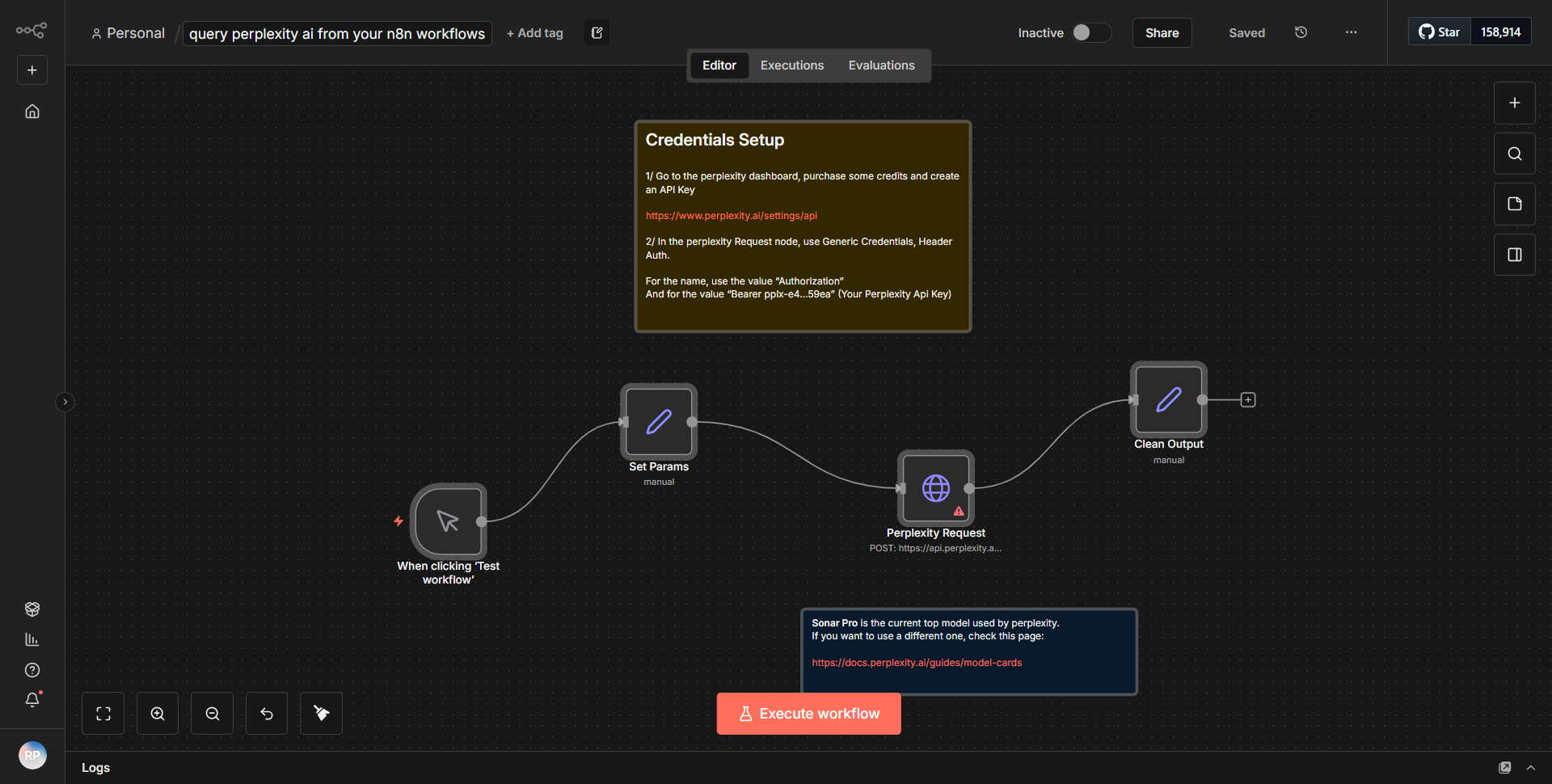
El flujo de trabajo titulado "Recuperar datos de Perplexity AI dentro de sus flujos de trabajo n8n" está diseñado para integrar Perplexity AI en n8n, lo que permite a los usuarios mejorar sus capacidades de consulta. El flujo de trabajo comienza con un nodo Trigger, que inicia el proceso en función de un evento específico. Esto podría ser un activador manual o uno automatizado basado en los datos entrantes.
Una vez activado, el flujo de trabajo pasa al nodo de solicitud HTTP, que está configurado para enviar una solicitud a la API de Perplexity AI. Este nodo es crucial ya que facilita la comunicación con el servicio de IA, permitiendo al usuario enviar consultas y recibir respuestas. La configuración de este nodo incluye la URL del punto final necesaria, el método HTTP (normalmente POST) y los encabezados necesarios, como el tipo de contenido y los tokens de autorización.
Después de que el nodo de solicitud HTTP procesa la consulta, se captura la respuesta de la API de Perplexity AI. Luego, esta respuesta se pasa a un nodo posterior, que probablemente sea un nodo Función o un nodo Conjunto, donde los datos se pueden manipular o formatear según sea necesario. Este paso es esencial para preparar los datos para su uso posterior, como enviarlos a otro servicio o mostrarlos en un formato fácil de usar.
Finalmente, el flujo de trabajo puede incluir nodos adicionales para la salida, como enviar los datos procesados a un correo electrónico, una base de datos u otro servicio externo. Cada nodo está conectado de forma lineal, lo que garantiza que la salida de un nodo se convierta sin problemas en la entrada del siguiente, creando un flujo cohesivo de datos.
Características clave
1. Integración con Perplexity AI:
este flujo de trabajo permite a los usuarios aprovechar las capacidades de Perplexity AI directamente dentro de su entorno n8n, mejorando la capacidad de consultar conjuntos de datos complejos y recuperar respuestas inteligentes.
2. Consultas personalizables:
los usuarios pueden personalizar las consultas enviadas a la API de Perplexity AI, adaptando las solicitudes para satisfacer necesidades o casos de uso específicos, lo que aumenta la flexibilidad del flujo de trabajo.
3. Manipulación de datos:
la inclusión de nodos para la manipulación de datos permite a los usuarios formatear y procesar las respuestas de IA, lo que facilita la integración de la salida en otras aplicaciones o servicios.
4. Disparadores automáticos:
el flujo de trabajo se puede configurar para que se active automáticamente en función de varios eventos, lo que permite la recuperación y el procesamiento de datos en tiempo real sin intervención manual.
5. Flujo de datos fluido:
la conexión estructurada entre nodos garantiza un flujo de datos fluido, minimizando el riesgo de errores y mejorando la eficiencia general del flujo de trabajo.
Integración de herramientas
El flujo de trabajo integra las siguientes herramientas y servicios:
- Perplexity AI:
el servicio principal utilizado para consultar y recuperar datos.
- Nodo de solicitud HTTP n8n:
este nodo es responsable de realizar llamadas API al servicio Perplexity AI.
- Nodo de función/Nodo de configuración:
Estos nodos se utilizan para procesar y manipular los datos recibidos de la API antes de enviarlos a la salida final.
Se requieren claves API
Para operar con éxito este flujo de trabajo, se requiere una clave API para Perplexity AI. Esta clave debe incluirse en la configuración del nodo de solicitud HTTP para autenticar solicitudes. Los usuarios deben asegurarse de tener las credenciales correctas y cualquier configuración adicional según lo especificado en la documentación de Perplexity AI. Si no se requieren claves API para otros nodos, cabe señalar que solo la integración de Perplexity AI requiere autenticación.









