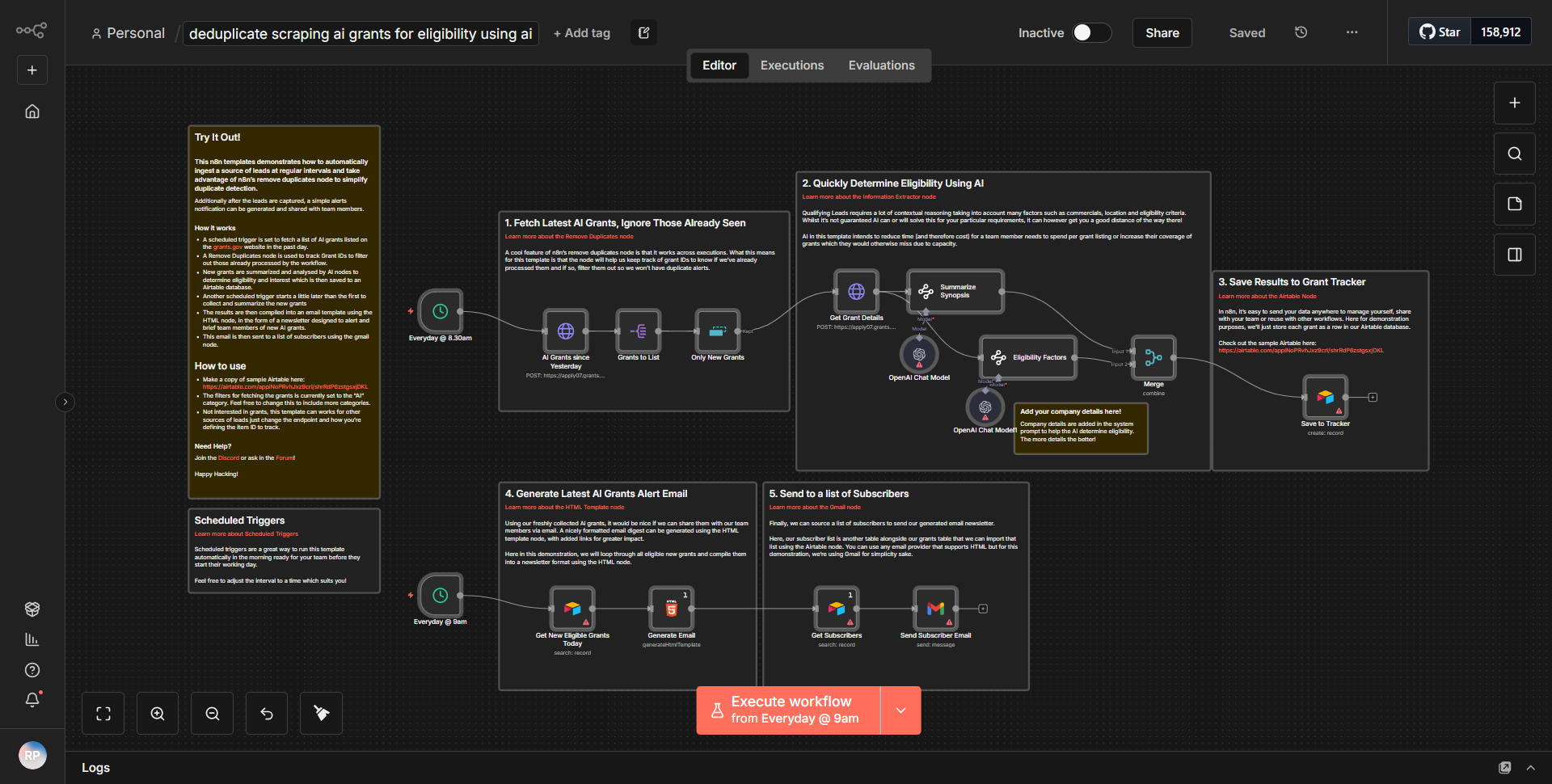
Flujo de trabajo automatizado para recuperar y categorizar resúmenes de papel frontal abrazado
Agiliza la recuperación, el resumen y la clasificación de trabajos de investigación de Hugging Face.
Cómo funciona
El flujo de trabajo titulado "Flujo de trabajo automatizado para recuperar y categorizar resúmenes de documentos de Hugging Face" está diseñado para agilizar el proceso de buscar, resumir y categorizar artículos de investigación de Hugging Face. El flujo de trabajo opera a través de una serie de nodos interconectados que facilitan el flujo y el procesamiento de datos.
1. Nodo desencadenante:
el flujo de trabajo comienza con un nodo desencadenante que inicia el proceso. Podría ser un desencadenador programado o un desencadenador basado en eventos, según la configuración específica.
2. Nodo de solicitud HTTP:
el primer nodo operativo es un nodo de solicitud HTTP, que envía una solicitud a la API de Hugging Face para recuperar una lista de artículos de investigación. Este nodo está configurado con el punto final y los parámetros adecuados para garantizar que obtenga los datos deseados.
3. Nodo de función:
después de recuperar los datos, el flujo de trabajo utiliza un nodo de función para procesar la respuesta. Este nodo extrae información relevante de la respuesta de la API, como títulos de artículos, resúmenes y URL, y la prepara para el resumen.
4. Nodo de resumen:
el siguiente paso implica otro nodo de solicitud HTTP que envía los resúmenes extraídos a una API de resumen. Este nodo es responsable de generar resúmenes concisos de los trabajos de investigación.
5. Nodo de categorización:
después del resumen, el flujo de trabajo emplea un nodo de categorización, que probablemente utiliza un modelo de aprendizaje automático o un conjunto predefinido de categorías para clasificar los artículos resumidos según su contenido.
6. Nodo de salida:
Finalmente, el flujo de trabajo concluye con un nodo de salida que formatea los resultados para su presentación o almacenamiento. Esto podría implicar enviar los resúmenes categorizados a una base de datos, un correo electrónico u otro servicio para su uso posterior.
A lo largo del flujo de trabajo, los datos fluyen secuencialmente de un nodo al siguiente, y cada nodo realiza una función específica que contribuye al objetivo general de resumir y categorizar los artículos de investigación.
Características clave
1. Recuperación automatizada de datos:
el flujo de trabajo automatiza el proceso de obtención de artículos de investigación de Hugging Face, eliminando la necesidad de recopilar datos manualmente.
2. Capacidad de resumen:
Incluye una función de resumen que condensa resúmenes extensos en resúmenes concisos, lo que facilita a los usuarios comprender rápidamente los puntos clave de cada artículo.
3. Categorización:
el flujo de trabajo clasifica los artículos resumidos, lo que permite a los usuarios filtrar y organizar la investigación en función de temas o temas específicos.
4. Integración con API:
el flujo de trabajo se integra perfectamente con API externas, aprovechando sus capacidades para mejorar el procesamiento y análisis de datos.
5. Disparadores personalizables:
los usuarios pueden configurar desencadenadores para ejecutar el flujo de trabajo según un cronograma o en respuesta a eventos específicos, lo que brinda flexibilidad sobre cómo y cuándo opera el flujo de trabajo.
Integración de herramientas
El flujo de trabajo utiliza varias herramientas e integraciones, que incluyen:
- Hugging Face API:
para recuperar trabajos de investigación y posiblemente para resumir.
- Nodos de solicitud HTTP:
se utilizan para interactuar con API externas tanto para recuperar documentos como para enviar datos para resumir.
- Nodo de Función:
Para procesar y transformar datos entre nodos.
- Modelo de categorización:
podría ser un modelo de aprendizaje automático integrado en el flujo de trabajo para clasificar los artículos.
Se requieren claves API
Para operar este flujo de trabajo, se necesitan las siguientes claves API y credenciales:
1. Clave de API de Hugging Face:
necesaria para autenticar solicitudes a la API de Hugging Face para recuperar trabajos de investigación y posiblemente para el servicio de resumen.
2. Clave API de resumen:
si se utiliza un servicio de resumen independiente, también se necesitará una clave API para ese servicio.
Si no hay servicios adicionales que requieran autenticación, esta será la lista completa de claves API necesarias para que el flujo de trabajo funcione correctamente.