Rastreador web de IA autosuficiente
Un raspador web autosuficiente impulsado por IA para recopilar y analizar datos.
Cómo funciona
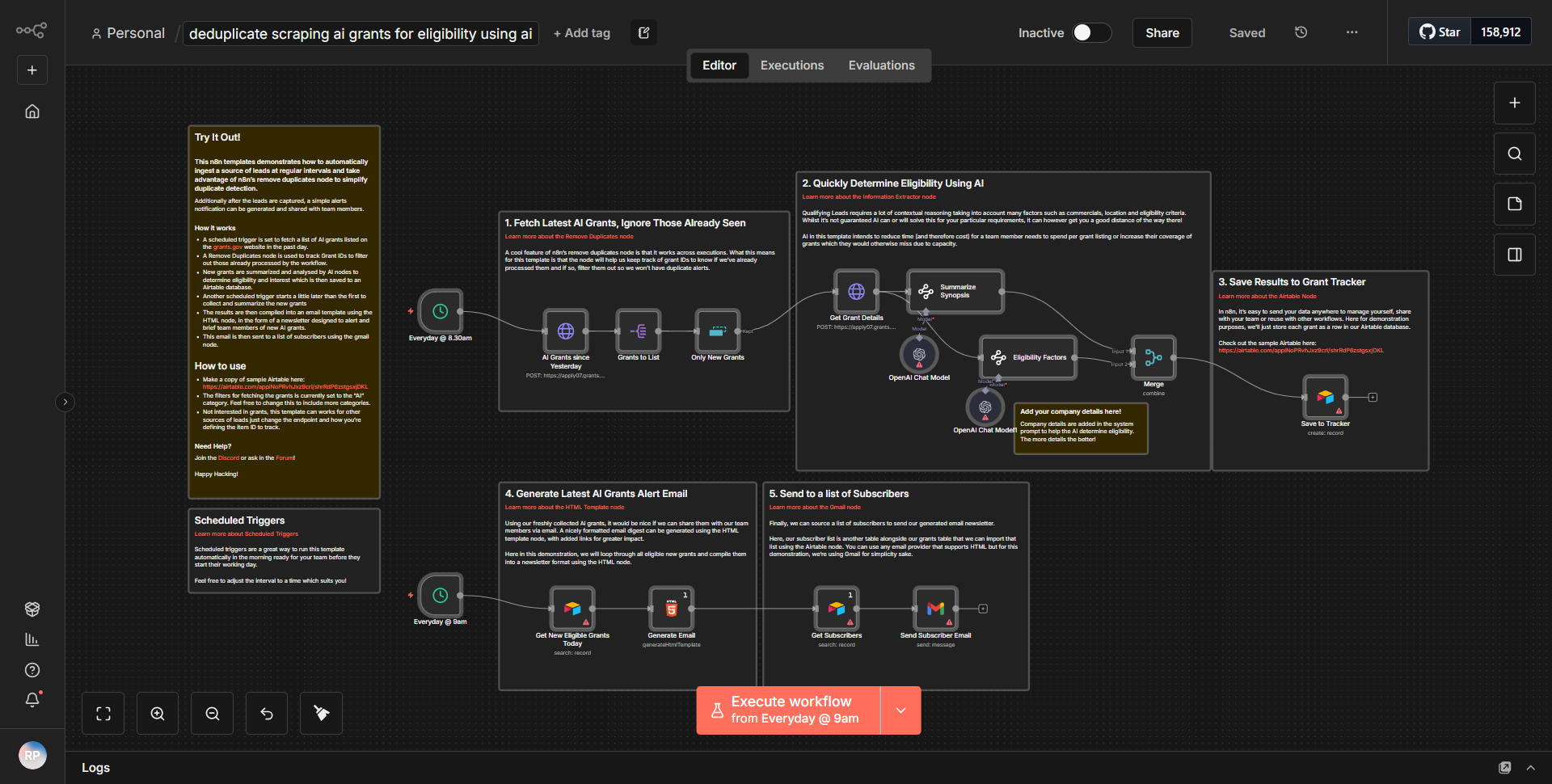
El flujo de trabajo del "rastreador web de IA autosuficiente" funciona como un raspador web autónomo diseñado para recopilar y analizar datos de Internet. El flujo de trabajo comienza con un nodo activador que inicia el proceso de raspado en función de un programa o evento definido. Una vez activado, el flujo de trabajo sigue un flujo sistemático de datos a través de varios nodos.
1. Iniciar nodo:
el flujo de trabajo se inicia según una programación o mediante un webhook, según la configuración.
2. Nodo de solicitud HTTP:
este nodo es responsable de enviar una solicitud al sitio web de destino. Recupera el contenido HTML de la URL especificada.
3. Nodo de extracción HTML:
después de obtener el contenido HTML, este nodo analiza los datos para extraer información relevante como títulos, enlaces o elementos de texto específicos en función de selectores predefinidos.
4. Nodo de función:
este nodo procesa aún más los datos extraídos, aplicando las transformaciones o cálculos necesarios. También puede incluir lógica para filtrar o formatear los datos para una mejor usabilidad.
5. Nodo de almacenamiento de datos:
los datos procesados luego se almacenan en una base de datos o en un servicio en la nube para referencia y análisis futuros. Esto podría involucrar nodos como Google Sheets, Airtable o una integración de base de datos personalizada.
6. Nodo de notificación:
Finalmente, el flujo de trabajo puede incluir un sistema de notificación que alerta al usuario sobre la finalización de la tarea de raspado o cualquier hallazgo importante. Esto podría ser a través de correo electrónico, Slack u otro servicio de mensajería.
Los nodos están interconectados de forma lineal, lo que garantiza que los datos fluyan sin problemas de un paso al siguiente, lo que permite una recopilación y procesamiento de datos eficiente.
Características clave
- Operación autónoma:
el flujo de trabajo está diseñado para ejecutarse sin intervención manual, lo que lo hace adecuado para la recopilación continua de datos.
- Extracción de datos:
capaz de extraer puntos de datos específicos de páginas web mediante selectores personalizables, lo que permite a los usuarios adaptar el proceso de extracción a sus necesidades.
- Procesamiento de datos:
Incluye funcionalidad para procesar y transformar los datos extraídos, asegurando que estén en un formato utilizable para el análisis.
- Integración de almacenamiento:
admite varias soluciones de almacenamiento, lo que permite a los usuarios guardar sus datos en los formatos y ubicaciones preferidos para facilitar el acceso y el análisis.
- Sistema de notificaciones:
Proporciona alertas y notificaciones al completar tareas o cuando se cumplen condiciones específicas, manteniendo a los usuarios informados sobre el estado del flujo de trabajo.
Integración de herramientas
El flujo de trabajo se integra con varias herramientas y servicios para mejorar su funcionalidad:
- Nodo de solicitud HTTP:
se utiliza para recuperar datos de los sitios web de destino.
- Nodo de extracción HTML:
analiza el contenido HTML para extraer datos relevantes.
- Nodo de función:
Realiza transformaciones y procesamiento de datos personalizados.
- Nodos de base de datos:
se integra con servicios como Google Sheets o Airtable para almacenamiento de datos.
- Nodos de notificación:
envía alertas por correo electrónico o plataformas de mensajería como Slack.
Se requieren claves API
No se requieren claves API ni credenciales de autenticación para la funcionalidad básica de este flujo de trabajo. Sin embargo, si el flujo de trabajo se integra con servicios específicos (como Google Sheets o Airtable), los usuarios deberán proporcionar las claves API o tokens de autenticación necesarios para que esos servicios permitan el almacenamiento y la recuperación de datos.