Análisis de clientes utilizando Qdrant, Python y Data Extractor
Reúne información sobre los clientes mediante el uso de Qdrant, Python y un módulo de extracción de datos.
Cómo funciona
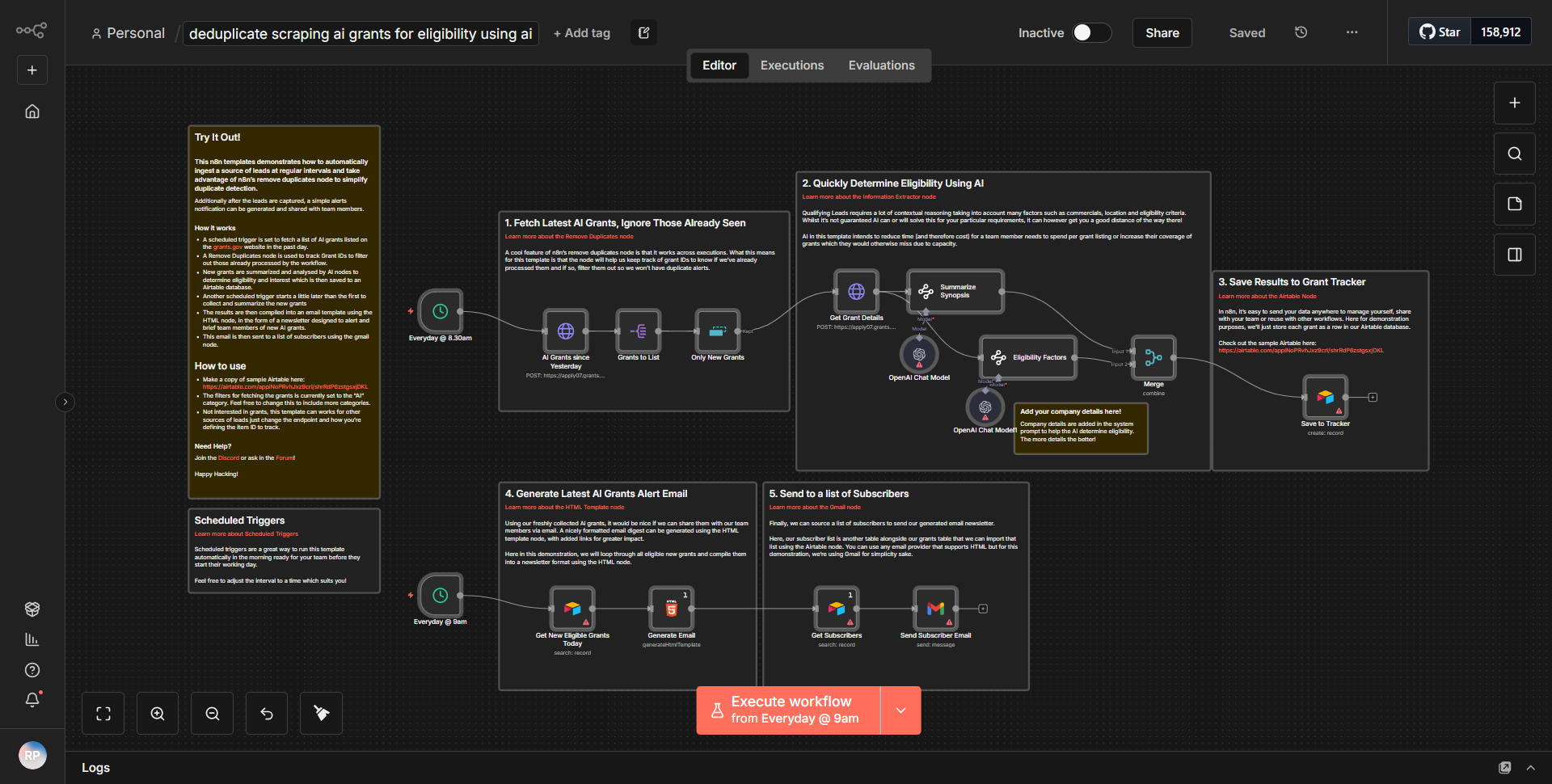
El flujo de trabajo titulado "Análisis de clientes utilizando Qdrant, Python y Data Extractor" está diseñado para recopilar información sobre los clientes aprovechando las capacidades de Qdrant, una base de datos vectorial, junto con Python para el procesamiento de datos y un módulo de extracción de datos. El flujo de trabajo comienza con un nodo desencadenante que inicia el proceso, probablemente en función de un evento o programación específica.
1. Extracción de datos:
el flujo de trabajo comienza con un nodo de extracción de datos que recupera datos del cliente de una fuente específica. Esto podría implicar conectarse a una base de datos o una API para obtener información relevante del cliente.
2. Procesamiento de datos con Python:
una vez que se extraen los datos, se pasan a un nodo de Python. Aquí, se ejecutan scripts de Python personalizados para procesar aún más los datos. Esto puede incluir limpieza de datos, transformación o cualquier cálculo analítico necesario para preparar los datos para el análisis.
3. Integración con Qdrant:
Después del procesamiento, el flujo de trabajo envía los datos preparados a un nodo Qdrant. Qdrant se utiliza para almacenar y gestionar las representaciones vectoriales de los datos del cliente, lo que permite búsquedas eficientes de similitudes y la recuperación de conocimientos basados en incrustaciones de vectores.
4. Generación de información:
el flujo de trabajo puede incluir nodos adicionales que consultan a Qdrant para generar información basada en los datos almacenados. Esto podría implicar realizar búsquedas de similitudes para identificar patrones o tendencias entre los clientes.
5. Salida e informes:
finalmente, el flujo de trabajo concluye con un nodo de salida que formatea los conocimientos en un informe o los envía a otro servicio para realizar acciones adicionales, como notificar a las partes interesadas o almacenar los resultados en una base de datos.
A lo largo de este proceso, los nodos están interconectados para garantizar un flujo fluido de datos desde la extracción hasta la generación de información, lo que permite un análisis integral de los datos del cliente.
Características clave
- Extracción de datos:
el flujo de trabajo puede extraer datos de los clientes de varias fuentes, lo que garantiza que el análisis se base en la información más relevante y actualizada.
- Procesamiento Python personalizado:
la integración de un nodo Python permite la manipulación y el análisis de datos avanzados, lo que permite a los usuarios implementar una lógica personalizada adaptada a sus necesidades específicas.
- Utilización de la base de datos vectorial:
al utilizar Qdrant, el flujo de trabajo se beneficia del almacenamiento y la recuperación eficientes de datos de alta dimensión, lo que facilita información rápida a través de búsquedas de similitudes.
- Generación de conocimientos:
la capacidad de generar conocimientos prácticos a partir de los datos de los clientes ayuda a las empresas a comprender el comportamiento y las preferencias de los clientes, lo que impulsa una mejor toma de decisiones.
- Informes automatizados:
el flujo de trabajo puede formatear y brindar información automáticamente, lo que reduce el esfuerzo manual y garantiza el acceso oportuno a la información crítica.
Integración de herramientas
- Nodo Extractor de Datos:
Este nodo es responsable de recuperar los datos de los clientes de diversas fuentes.
- Nodo Python:
se utiliza para ejecutar scripts personalizados que procesan los datos extraídos.
- Qdrant Node:
se integra con la base de datos vectorial Qdrant para almacenar y consultar datos de clientes.
- Nodo de salida:
formatea y entrega los conocimientos generados a partir del análisis.
Se requieren claves API
El flujo de trabajo no especifica ninguna clave API ni credenciales de autenticación necesarias para la operación. Sin embargo, si la extracción de datos implica acceder a API o bases de datos externas, pueden ser necesarias las credenciales adecuadas, que deben configurarse en los nodos respectivos.