Extraiga y condense artículos de un sitio web de noticias que carece de un canal RSS utilizando IA y almacene los resultados en NocoDB.
Extrae y condensa artículos de noticias que carecen de canales RSS mediante la utilización de IA, y los resultados se almacenan en NocoDB.
Cómo funciona
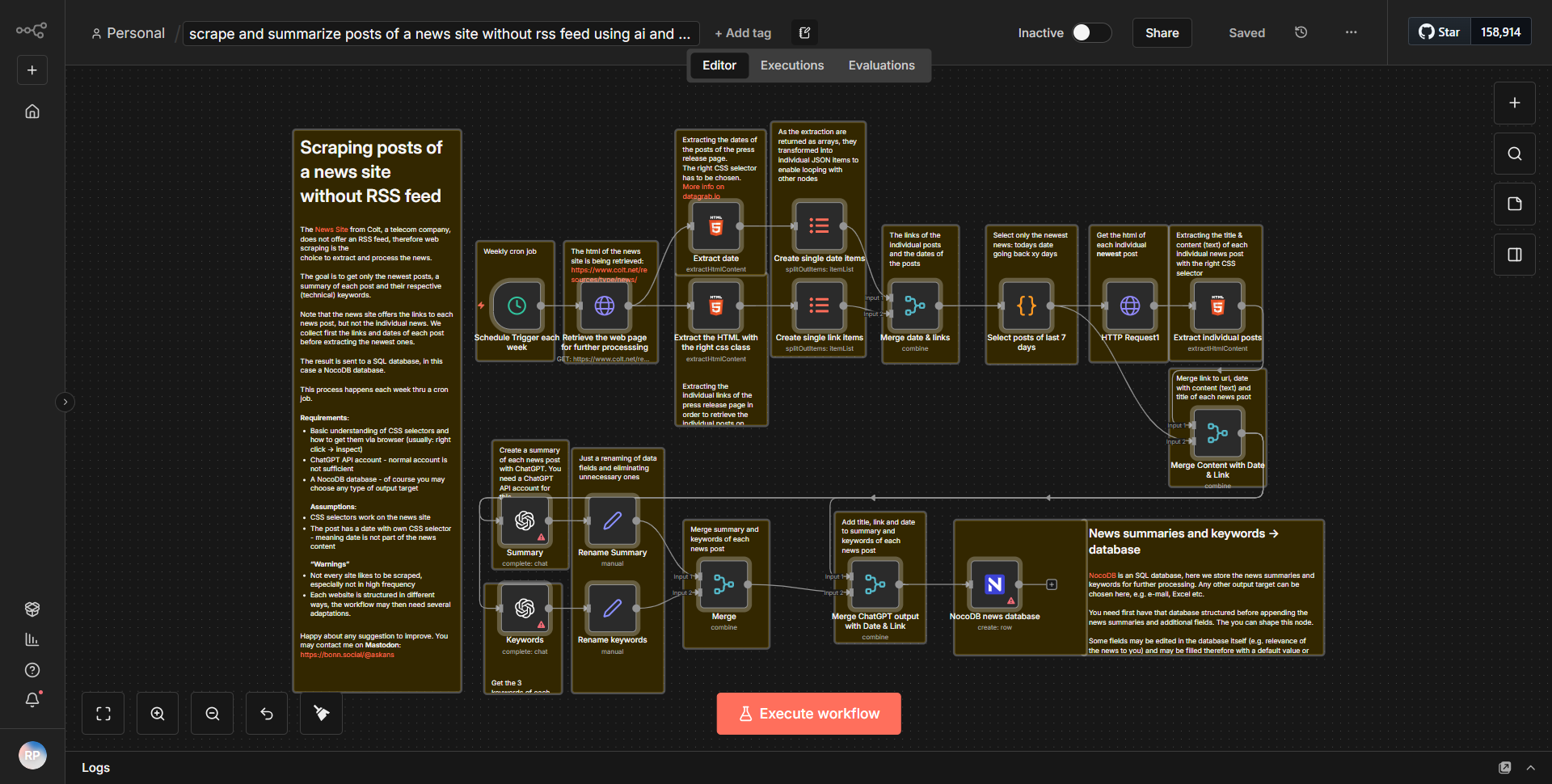
El flujo de trabajo comienza con un nodo
Solicitud HTTP
que está configurado para recuperar el contenido HTML de un sitio web de noticias específico que no proporciona una fuente RSS. Este nodo está configurado para realizar una solicitud GET a la URL de destino, recuperando todo el contenido de la página. La salida de este nodo es el HTML sin formato, que luego se pasa al siguiente nodo para su procesamiento.Después del nodo Solicitud HTTP, hay un nodo
Extracción HTML
. Este nodo es responsable de analizar el contenido HTML recuperado del paso anterior. Utiliza selectores de CSS para identificar y extraer elementos específicos del HTML, como títulos de artículos, fechas de publicación y el cuerpo principal de los artículos. Los datos extraídos se estructuran en un formato más manejable, normalmente como JSON.A continuación, el flujo de trabajo incluye un nodo
Función
que procesa aún más los datos extraídos. En este nodo los artículos se condensan mediante técnicas de IA. Esto podría implicar resumir el contenido o extraer puntos clave, dependiendo de la implementación específica. La salida de este nodo es una versión resumida de los artículos, lista para su almacenamiento.El último paso del flujo de trabajo es un nodo
NocoDB
, que se utiliza para almacenar los artículos resumidos en una base de datos NocoDB. Este nodo está configurado para crear nuevos registros en una tabla específica, donde cada registro corresponde a un artículo resumido. Los datos enviados a NocoDB incluyen el título, el resumen y cualquier otro metadato relevante extraído anteriormente.A lo largo del flujo de trabajo, los datos fluyen secuencialmente de un nodo al siguiente, transformando HTML sin formato en contenido estructurado y resumido que se almacena en una base de datos para facilitar el acceso y la administración.
Características clave
1. Resumen impulsado por IA:
el flujo de trabajo utiliza técnicas de IA para condensar artículos extensos en resúmenes concisos, lo que facilita a los usuarios comprender rápidamente la información esencial.
2. Extracción de contenido HTML:
al extraer contenido HTML directamente de sitios web que carecen de canales RSS, el flujo de trabajo puede recopilar artículos de noticias de una variedad de fuentes que de otro modo serían inaccesibles.
3. Integración con NocoDB:
la capacidad de almacenar artículos resumidos en NocoDB permite una gestión organizada de datos y una fácil recuperación, lo que facilita análisis o informes adicionales.
4. Extracción de datos personalizable:
el uso de selectores CSS en el nodo Extracto HTML permite a los usuarios personalizar qué elementos de los artículos desean extraer, brindando flexibilidad basada en diferentes estructuras del sitio web.
5. Flujo de trabajo automatizado:
todo el proceso está automatizado, lo que reduce la necesidad de recopilación y resumen de datos manualmente, lo que ahorra tiempo y esfuerzo a los usuarios.
Integración de herramientas
- Nodo de solicitud HTTP:
se utiliza para recuperar contenido HTML del sitio web de noticias especificado.
- Nodo de extracción HTML:
analiza el HTML y extrae datos relevantes del artículo utilizando selectores CSS.
- Nodo de función:
procesa los datos extraídos y utiliza IA para el resumen.
- Nodo NocoDB:
Almacena los artículos resumidos en una base de datos NocoDB para la gestión de datos estructurados.
Se requieren claves API
No se requieren claves API ni credenciales de autenticación para que este flujo de trabajo funcione. Los nodos utilizados operan sin necesidad de acceso API externo, confiando únicamente en la solicitud HTTP al sitio web de noticias y la integración con NocoDB para el almacenamiento de datos.









