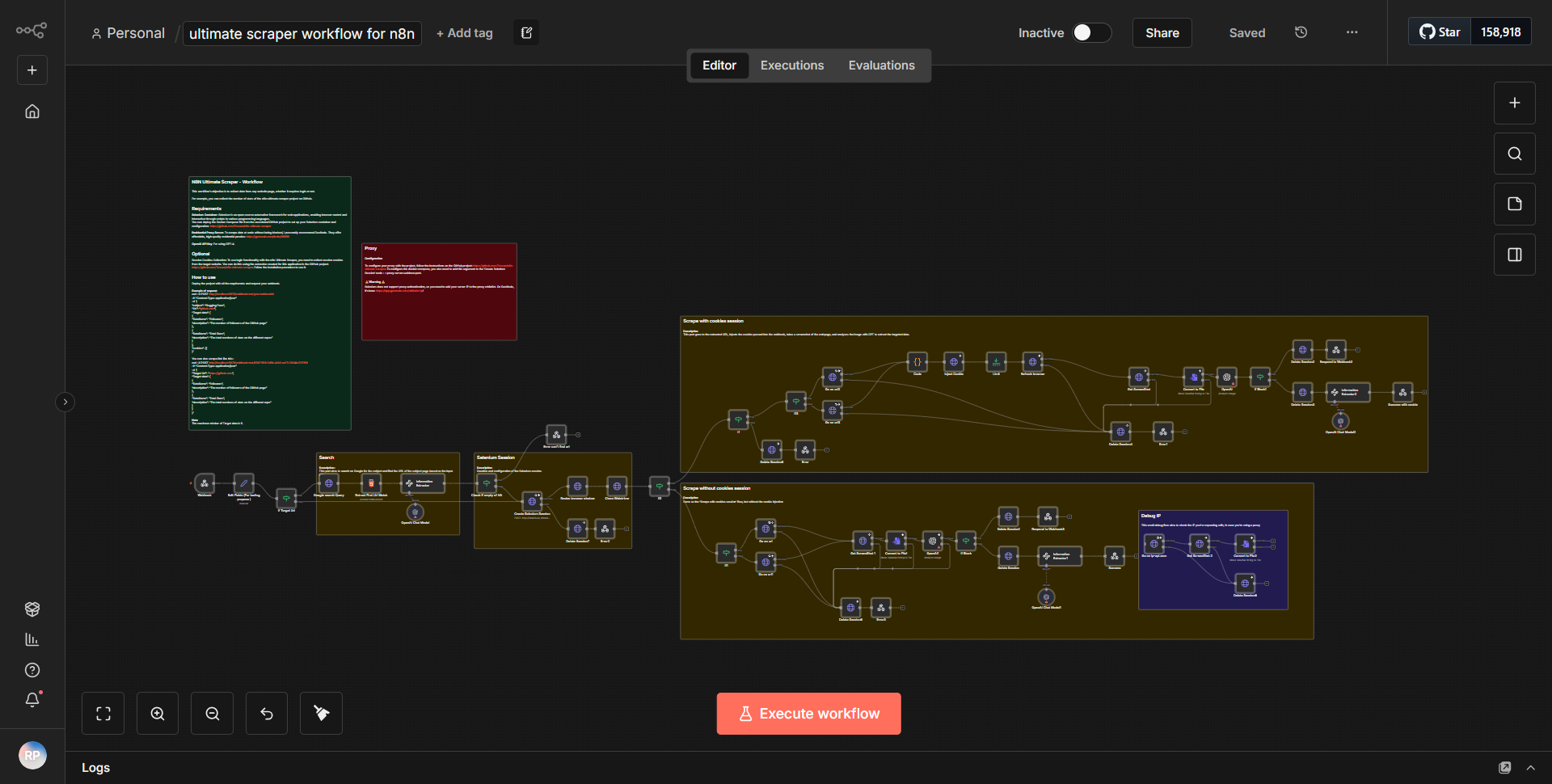
Flujo de trabajo completo de Scraper para n8n
Un extenso flujo de trabajo de extracción de datos para n8n diseñado para recopilar información de múltiples fuentes.
Cómo funciona
El flujo de trabajo integral de Scraper para n8n está diseñado para extraer datos de múltiples fuentes de manera estructurada. El flujo de trabajo comienza con un
nodo Cron
, que desencadena el proceso en intervalos específicos. Este nodo está configurado para ejecutar el flujo de trabajo diariamente, asegurando que los datos se recopilen regularmente.Después del nodo Cron, el flujo de trabajo utiliza un
nodo de solicitud HTTP
para recuperar datos de una URL específica. Este nodo está configurado para realizar una solicitud GET, lo que le permite recuperar el contenido HTML de la página web de destino. Luego, la salida de este nodo se pasa a unnodo de extracción HTML
, que es responsable de analizar el contenido HTML y extraer puntos de datos relevantes en función de selectores predefinidos.Una vez que se extraen los datos, se envían a un
nodo Establecer
donde se formatean y organizan en una estructura más manejable. Este nodo permite cambiar el nombre de los campos y ajustar el formato de los datos según sea necesario. Luego, los datos procesados se dirigen a unnodo de función
, que puede realizar transformaciones o cálculos adicionales en los datos, mejorando su usabilidad.Una vez transformados los datos, se envían a un
nodo de base de datos
para su almacenamiento. Este nodo está configurado para insertar los datos en una base de datos específica, asegurando que la información extraída se guarde para referencia futura. Finalmente, el flujo de trabajo concluye con unnodo Webhook
, que se puede utilizar para notificar a otros servicios o activar acciones adicionales según la finalización del proceso de extracción de datos.Características clave
1. Extracción de datos automatizada:
el flujo de trabajo automatiza el proceso de extracción de datos de múltiples fuentes, lo que reduce el esfuerzo manual y aumenta la eficiencia.
2. Programación personalizable:
con el nodo Cron, los usuarios pueden personalizar fácilmente la frecuencia de extracción de datos, asegurando que la información más reciente esté siempre disponible.
3. Análisis de datos flexible:
el nodo Extracción HTML permite un análisis flexible del contenido HTML, lo que permite a los usuarios especificar exactamente qué puntos de datos extraer según sus necesidades.
4. Capacidades de transformación de datos:
la inclusión de los nodos Conjunto y Función permite una manipulación exhaustiva de los datos, lo que garantiza que los datos extraídos estén en el formato deseado antes del almacenamiento.
5. Integración con bases de datos:
el flujo de trabajo se integra perfectamente con las bases de datos, lo que permite un fácil almacenamiento y recuperación de los datos extraídos.
6. Sistema de notificación:
el nodo Webhook proporciona un mecanismo para notificar a otros servicios o activar flujos de trabajo adicionales, mejorando la funcionalidad general del sistema.
Integración de herramientas
El flujo de trabajo integral de Scraper se integra con varias herramientas y servicios, utilizando nodos específicos dentro de n8n:
- Nodo Cron:
Para programar la ejecución del flujo de trabajo.
- Nodo de solicitud HTTP:
para obtener datos de URL externas.
- Nodo de extracción HTML:
para analizar contenido HTML y extraer puntos de datos específicos.
- Establecer nodo:
Para formatear y organizar los datos extraídos.
- Nodo de función:
Para realizar transformaciones de datos adicionales.
- Nodo de base de datos:
Para almacenar los datos extraídos en una base de datos.
- Nodo webhook:
para enviar notificaciones o activar otros flujos de trabajo.
Se requieren claves API
Este flujo de trabajo no requiere claves API ni credenciales de autenticación para funcionar. Todos los nodos operan basándose en datos de acceso público o configuraciones de bases de datos locales.









