Извлекайте и сжимайте веб-страницы с помощью искусственного интеллекта.
Извлекает и сжимает информацию с веб-сайтов, используя искусственный интеллект.
Как это работает
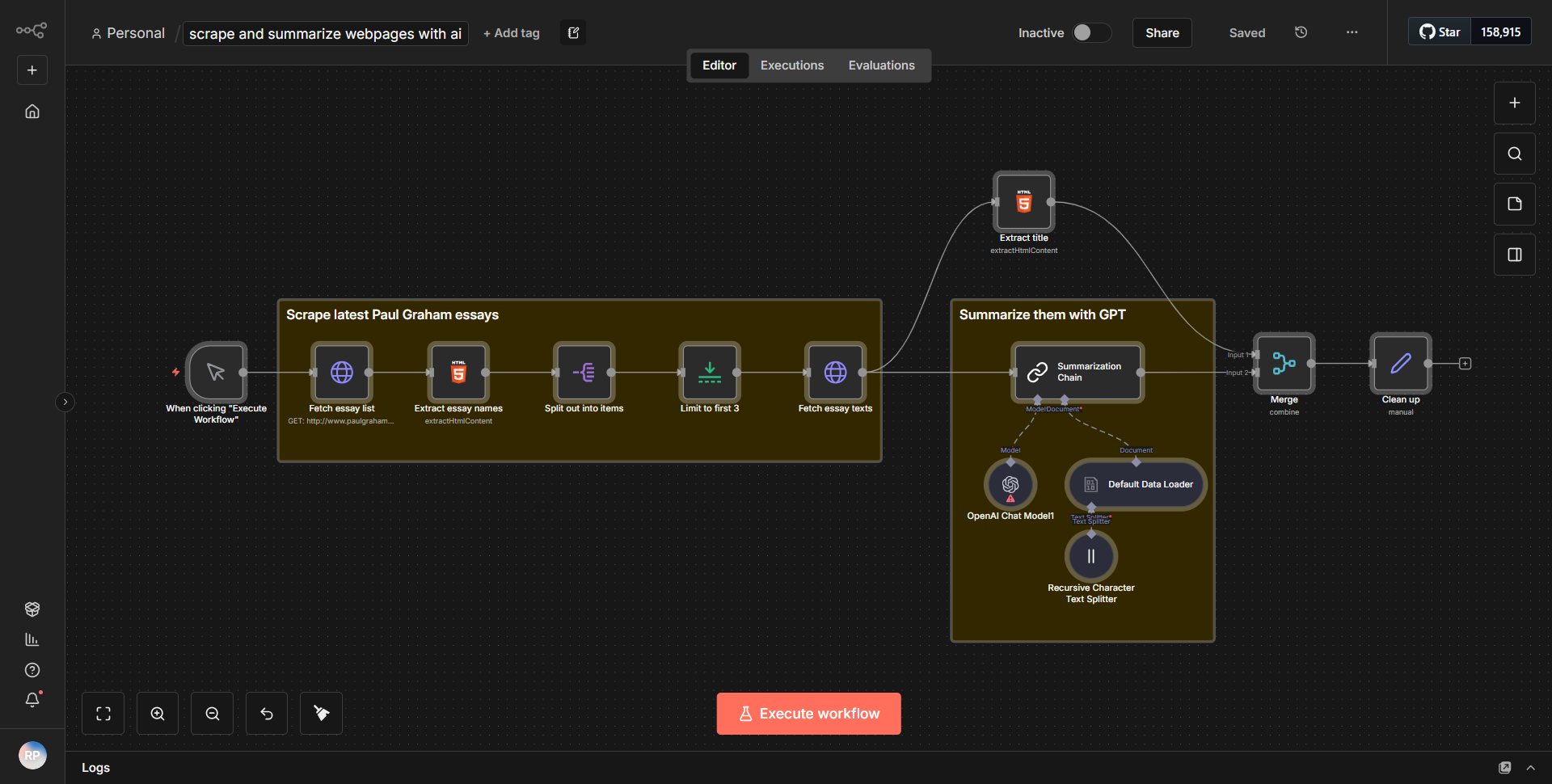
Рабочий процесс под названием «Извлечение и сжатие веб-страниц с использованием искусственного интеллекта» предназначен для сбора информации с определенных веб-страниц и обобщения содержимого с использованием искусственного интеллекта. Рабочий процесс осуществляется через ряд взаимосвязанных узлов, которые облегчают извлечение, обработку и создание выходных данных.
1. Стартовый узел
. Рабочий процесс начинается с триггерного узла, который инициирует процесс. Этот узел можно настроить для запуска по расписанию или для запуска вручную.
2. Узел HTTP-запроса
. Первым рабочим узлом является узел HTTP-запроса, который отвечает за получение содержимого целевой веб-страницы. В этом узле указывается URL-адрес веб-страницы, и он получает содержимое HTML.
3. Узел извлечения HTML:
после HTTP-запроса узел извлечения HTML обрабатывает полученное содержимое HTML. Этот узел настроен для извлечения определенных элементов из HTML, таких как заголовки, абзацы или другие соответствующие точки данных, необходимые для обобщения.
4. Узел суммирования AI:
после извлечения соответствующих данных рабочий процесс использует узел суммирования AI. Этот узел берет извлеченный текст и применяет модель искусственного интеллекта для сжатия информации в краткое изложение. Конфигурация этого узла включает параметры, определяющие длину и стиль сводки.
5. Узел вывода
. Наконец, сводный контент отправляется на узел вывода, который можно настроить для отправки результатов в различные места назначения, например по электронной почте, в базу данных или другой API, в зависимости от требований пользователя.
Поток данных линейный: начинается от триггера, проходит через HTTP-запрос для извлечения контента, обрабатывает этот контент посредством извлечения HTML, суммирует его с помощью ИИ и, наконец, выводит результат.
Основные характеристики
- Извлечение веб-страницы:
рабочий процесс может извлекать контент с любой указанной веб-страницы, что делает его универсальным для различных источников информации.
- Обобщение на основе искусственного интеллекта:
используются передовые алгоритмы искусственного интеллекта для сжатия длинного веб-контента в краткие сводки, что экономит время и усилия пользователей.
- Настраиваемый вывод:
пользователи могут настраивать формат вывода и место назначения, обеспечивая интеграцию с другими приложениями или службами.
- Выполнение по расписанию:
рабочий процесс можно настроить на выполнение по расписанию, что позволяет автоматически извлекать и суммировать данные без ручного вмешательства.
- Дружественный интерфейс:
визуальное представление рабочего процесса в n8n упрощает его понимание и изменение, что удобно как для технических, так и для нетехнических пользователей.
Интеграция инструментов
Рабочий процесс объединяет несколько инструментов и сервисов через определенные узлы n8n:
- Узел HTTP-запроса:
используется для получения содержимого веб-страницы.
- Узел извлечения HTML:
извлекает определенные данные из содержимого HTML.
- Узел суммирования AI:
применяет искусственный интеллект для обобщения извлеченного контента.
- Узел вывода:
можно настроить для отправки сводного контента на различные конечные точки, например по электронной почте или через API.
Требуются ключи API
Для рабочего процесса могут потребоваться ключи API или учетные данные для узла суммирования AI, в зависимости от конкретной используемой службы AI. Пользователи должны убедиться, что у них есть необходимые данные аутентификации для любых внешних служб, интегрированных в рабочий процесс. Если рабочий процесс использует общедоступные модели искусственного интеллекта или не требует аутентификации, ключи API не нужны.









