Самодостаточный веб-сканер с искусственным интеллектом
Самодостаточный веб-скребок на базе искусственного интеллекта для сбора и анализа данных.
Как это работает
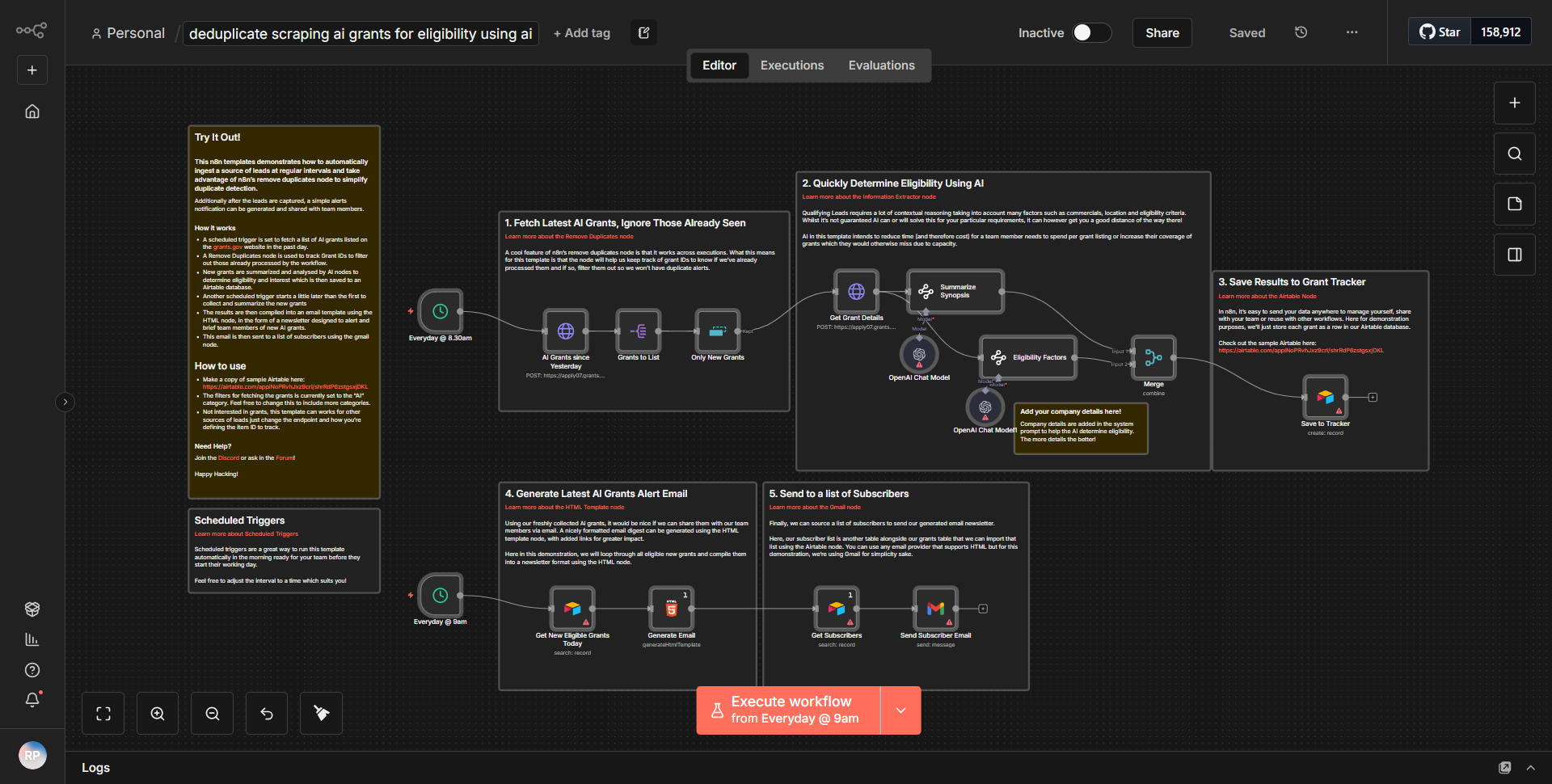
Рабочий процесс «Самостоятельный веб-сканер с искусственным интеллектом» работает как автономный веб-скребок, предназначенный для сбора и анализа данных из Интернета. Рабочий процесс начинается с триггерного узла, который инициирует процесс очистки на основе определенного расписания или события. После запуска рабочий процесс следует за систематическим потоком данных через различные узлы.
1. Запуск узла
. Рабочий процесс запускается либо по расписанию, либо через веб-перехватчик, в зависимости от конфигурации.
2. Узел HTTP-запроса:
этот узел отвечает за отправку запроса на целевой веб-сайт. Он извлекает HTML-содержимое указанного URL-адреса.
3. Узел извлечения HTML:
после получения содержимого HTML этот узел анализирует данные для извлечения соответствующей информации, такой как заголовки, ссылки или определенные текстовые элементы, на основе предопределенных селекторов.
4. Функциональный узел:
этот узел дополнительно обрабатывает извлеченные данные, применяя все необходимые преобразования или вычисления. Он также может включать логику для фильтрации или форматирования данных для повышения удобства использования.
5. Узел хранения данных:
обработанные данные затем сохраняются в базе данных или облачной службе для дальнейшего использования и анализа. Это может включать в себя такие узлы, как Google Sheets, Airtable или интеграцию пользовательской базы данных.
6. Узел уведомлений
. Наконец, рабочий процесс может включать систему уведомлений, которая предупреждает пользователя о завершении задачи очистки или любых важных результатах. Это может быть электронная почта, Slack или другая служба обмена сообщениями.
Узлы соединены между собой линейным образом, что обеспечивает беспрепятственный переход данных от одного этапа к другому, что позволяет эффективно собирать и обрабатывать данные.
Основные характеристики
- Автономная работа:
рабочий процесс разработан таким образом, чтобы работать без ручного вмешательства, что делает его пригодным для непрерывного сбора данных.
- Извлечение данных:
возможность извлекать определенные точки данных с веб-страниц с помощью настраиваемых селекторов, что позволяет пользователям адаптировать процесс очистки к своим потребностям.
- Обработка данных:
включает функции обработки и преобразования извлеченных данных, обеспечивая их формат, пригодный для анализа.
- Интеграция хранилища:
поддерживает различные решения для хранения данных, позволяя пользователям сохранять свои данные в предпочитаемых форматах и местах для быстрого доступа и анализа.
- Система уведомлений:
предоставляет оповещения и уведомления после завершения задач или при выполнении определенных условий, информируя пользователей о состоянии рабочего процесса.
Интеграция инструментов
Рабочий процесс интегрируется с несколькими инструментами и сервисами для расширения его функциональности:
- Узел HTTP-запроса:
используется для получения данных с целевых веб-сайтов.
- Узел извлечения HTML:
анализирует содержимое HTML для извлечения соответствующих данных.
- Функциональный узел:
выполняет пользовательскую обработку и преобразование данных.
- Узлы базы данных:
интегрируются с такими сервисами, как Google Sheets или Airtable, для хранения данных.
- Узлы уведомлений:
отправляет оповещения по электронной почте или через платформы обмена сообщениями, такие как Slack.
Требуются ключи API
Для основных функций этого рабочего процесса не требуются ключи API или учетные данные аутентификации. Однако если рабочий процесс интегрируется с определенными сервисами (например, Google Sheets или Airtable), пользователям необходимо будет предоставить необходимые ключи API или токены аутентификации для этих сервисов, чтобы обеспечить хранение и извлечение данных.