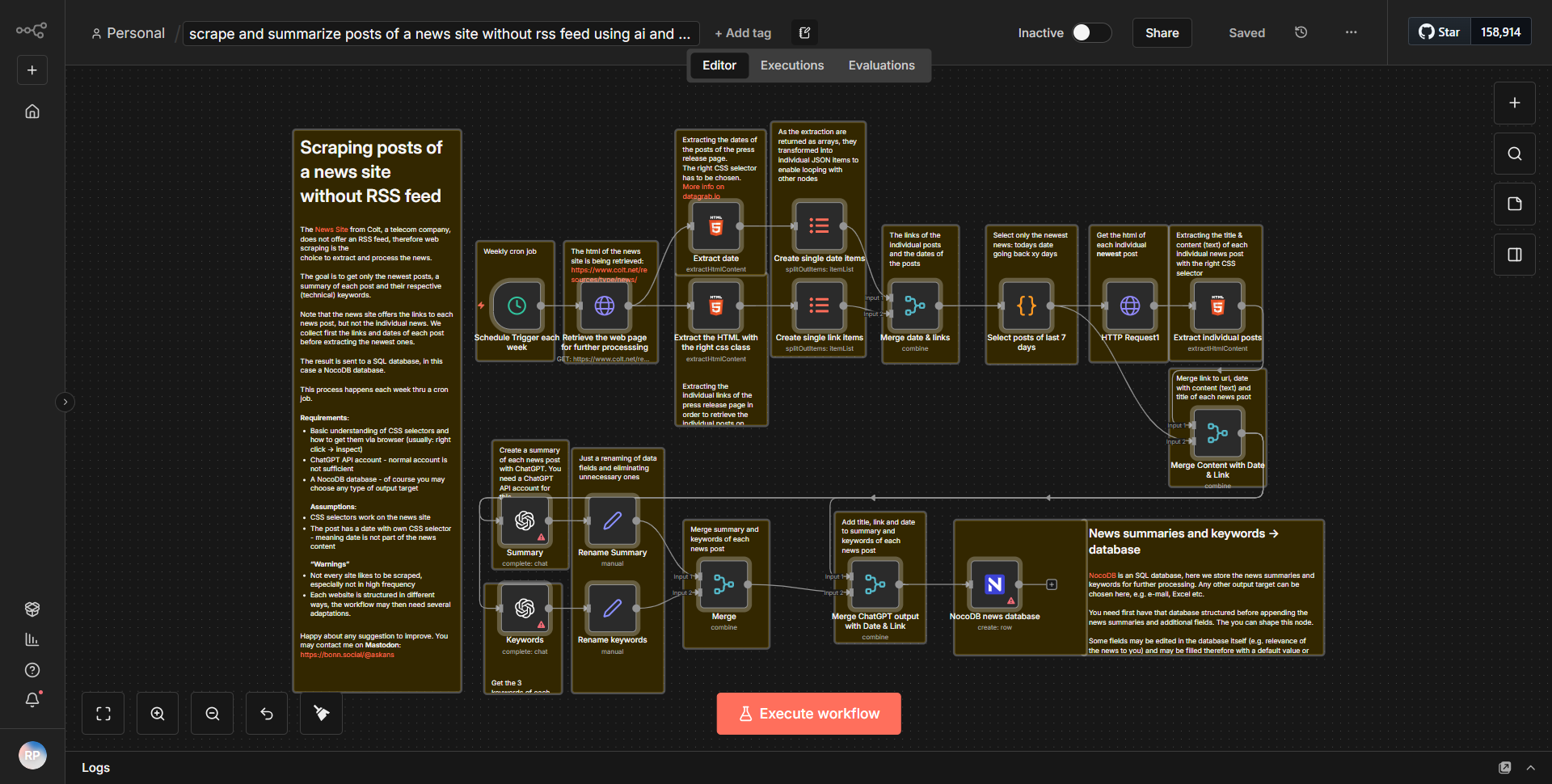
Извлекайте и сокращайте статьи с новостного веб-сайта, на котором отсутствует канал RSS, с использованием искусственного интеллекта, и сохраняйте результаты в NocoDB.
Извлекает и сжимает новостные статьи, в которых отсутствуют RSS-каналы, с помощью искусственного интеллекта, а результаты сохраняются в NocoDB.
Как это работает
Рабочий процесс начинается с узла
HTTP-запрос
, который настроен для получения HTML-контента указанного новостного веб-сайта, который не предоставляет RSS-канал. Этот узел настроен на выполнение запроса GET к целевому URL-адресу, получая все содержимое страницы. Выходными данными этого узла является необработанный HTML-код, который затем передается следующему узлу для обработки.После узла HTTP-запроса идет узел
Извлечение HTML
. Этот узел отвечает за анализ содержимого HTML, полученного на предыдущем шаге. Он использует селекторы CSS для идентификации и извлечения определенных элементов из HTML, таких как заголовки статей, даты публикации и основная часть статей. Извлеченные данные структурированы в более удобном формате, обычно в формате JSON.Далее рабочий процесс включает узел
Функция
, который далее обрабатывает извлеченные данные. В этом узле статьи сжаты с использованием методов искусственного интеллекта. Это может включать в себя обобщение содержания или извлечение ключевых моментов, в зависимости от конкретной реализации. Результатом работы этого узла является обобщенная версия статей, готовая к хранению.Последним шагом рабочего процесса является узел
NocoDB
, который используется для хранения сводных статей в базе данных NocoDB. Этот узел настроен на создание новых записей в указанной таблице, где каждая запись соответствует сводной статье. Данные, отправляемые в NocoDB, включают заголовок, краткое описание и любые другие соответствующие метаданные, извлеченные ранее.На протяжении всего рабочего процесса данные последовательно передаются от одного узла к другому, преобразуя необработанный HTML-код в структурированный, обобщенный контент, который хранится в базе данных для облегчения доступа и управления.
Основные характеристики
1. Обобщение на основе искусственного интеллекта
. В рабочем процессе используются методы искусственного интеллекта для сжатия длинных статей в краткие изложения, что упрощает пользователям быстрое понимание важной информации.
2. Извлечение HTML-контента
. Собирая HTML-контент непосредственно с веб-сайтов, не имеющих RSS-каналов, рабочий процесс позволяет собирать новостные статьи из различных источников, которые в противном случае были бы недоступны.
3. Интеграция с NocoDB
. Возможность хранения сводных статей в NocoDB позволяет организовать управление данными и их легкий поиск, что облегчает дальнейший анализ или составление отчетов.
4. Настраиваемое извлечение данных
. Использование селекторов CSS в узле «Извлечение HTML» позволяет пользователям настраивать элементы статей, которые они хотят извлечь, обеспечивая гибкость, основанную на различных структурах веб-сайта.
5. Автоматизированный рабочий процесс
. Весь процесс автоматизирован, что снижает необходимость ручного сбора и обобщения данных, что экономит время и усилия пользователей.
Интеграция инструментов
- Узел HTTP-запроса:
используется для получения HTML-контента с указанного новостного веб-сайта.
- Узел извлечения HTML:
анализирует HTML и извлекает соответствующие данные статьи с помощью селекторов CSS.
- Функциональный узел:
обрабатывает извлеченные данные и использует искусственный интеллект для обобщения.
- Узел NocoDB:
сохраняет сводные статьи в базе данных NocoDB для управления структурированными данными.
Требуются ключи API
Для работы этого рабочего процесса не требуются ключи API или учетные данные аутентификации. Используемые узлы работают без необходимости доступа к внешнему API, полагаясь исключительно на HTTP-запрос к новостному сайту и интеграцию с NocoDB для хранения данных.









