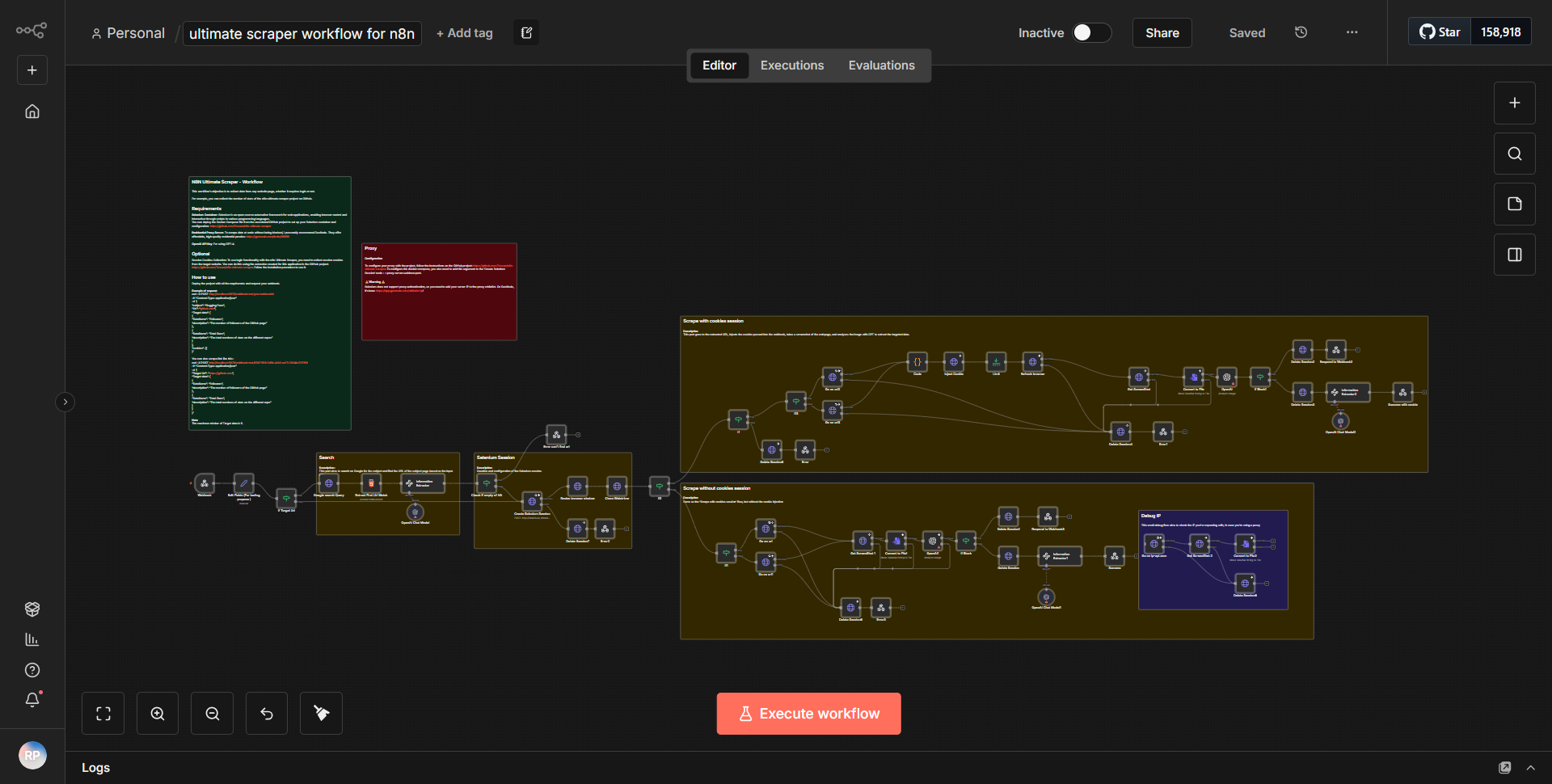
Комплексный рабочий процесс парсера для n8n
Обширный рабочий процесс извлечения данных для n8n, предназначенный для сбора информации из нескольких источников.
Как это работает
Комплексный рабочий процесс парсера для n8n предназначен для структурированного извлечения данных из нескольких источников. Рабочий процесс начинается с
узла Cron
, который запускает процесс через определенные промежутки времени. Этот узел настроен на ежедневное выполнение рабочего процесса, обеспечивая регулярный сбор данных.После узла Cron рабочий процесс использует
узел HTTP-запроса
для получения данных с указанного URL-адреса. Этот узел настроен на выполнение запроса GET, позволяющего получать HTML-содержимое целевой веб-страницы. Выходные данные этого узла затем передаются в узелИзвлечение HTML
, который отвечает за анализ содержимого HTML и извлечение соответствующих точек данных на основе предопределенных селекторов.После извлечения данных они отправляются в
Узел установки
, где форматируются и организуются в более управляемую структуру. Этот узел позволяет переименовывать поля и при необходимости корректировать формат данных. Обработанные данные затем направляются вФункциональный узел
, который может выполнять дополнительные преобразования или вычисления с данными, повышая их удобство использования.После преобразования данных они отправляются в
узел базы данных
для хранения. Этот узел настроен на вставку данных в указанную базу данных, гарантируя сохранение извлеченной информации для дальнейшего использования. Наконец, рабочий процесс завершаетсяузлом веб-перехватчика
, который можно использовать для уведомления других служб или запуска дополнительных действий в зависимости от завершения процесса извлечения данных.Основные характеристики
1. Автоматическое извлечение данных
. Рабочий процесс автоматизирует процесс извлечения данных из нескольких источников, сокращая ручные усилия и повышая эффективность.
2. Настраиваемое расписание
. С помощью узла Cron пользователи могут легко настроить частоту извлечения данных, гарантируя, что самая свежая информация всегда будет доступна.
3. Гибкий анализ данных
. Узел извлечения HTML обеспечивает гибкий анализ содержимого HTML, позволяя пользователям точно указывать, какие точки данных следует извлечь в зависимости от их потребностей.
4. Возможности преобразования данных:
включение узлов «Набор» и «Функция» позволяет выполнять обширные манипуляции с данными, гарантируя, что извлеченные данные будут в нужном формате перед сохранением.
5. Интеграция с базами данных
. Рабочий процесс легко интегрируется с базами данных, что позволяет легко хранить и извлекать извлеченные данные.
6. Система уведомлений
. Узел Webhook предоставляет механизм уведомления других служб или запуска дополнительных рабочих процессов, улучшая общую функциональность системы.
Интеграция инструментов
Комплексный рабочий процесс Scraper интегрируется с несколькими инструментами и сервисами, используя определенные узлы внутри n8n:
- Узел Cron:
для планирования выполнения рабочего процесса.
- Узел HTTP-запроса:
для получения данных с внешних URL-адресов.
- Узел извлечения HTML:
для анализа содержимого HTML и извлечения определенных точек данных.
- Установить узел:
для форматирования и организации извлеченных данных.
- Функциональный узел:
для выполнения дополнительных преобразований данных.
- Узел базы данных:
для хранения извлеченных данных в базе данных.
- Узел веб-перехватчика:
для отправки уведомлений или запуска других рабочих процессов.
Требуются ключи API
Для работы этого рабочего процесса не требуются ключи API или учетные данные аутентификации. Все узлы работают на основе общедоступных данных или конфигураций локальной базы данных.









