Ferramenta KB - Repositório de conhecimento do Confluence
Conecta-se ao Confluence para gerenciar recursos da base de conhecimento.
Como funciona
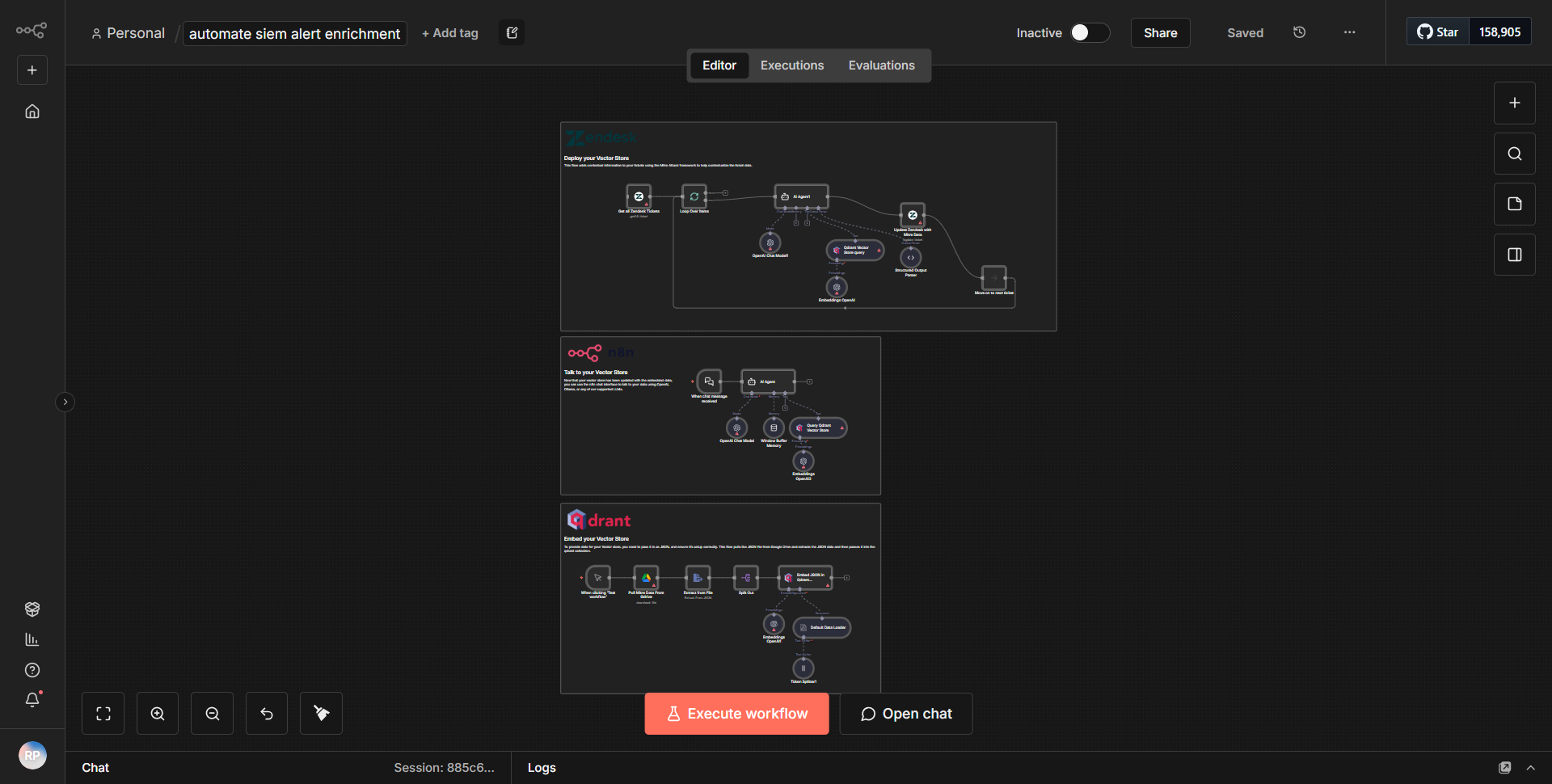
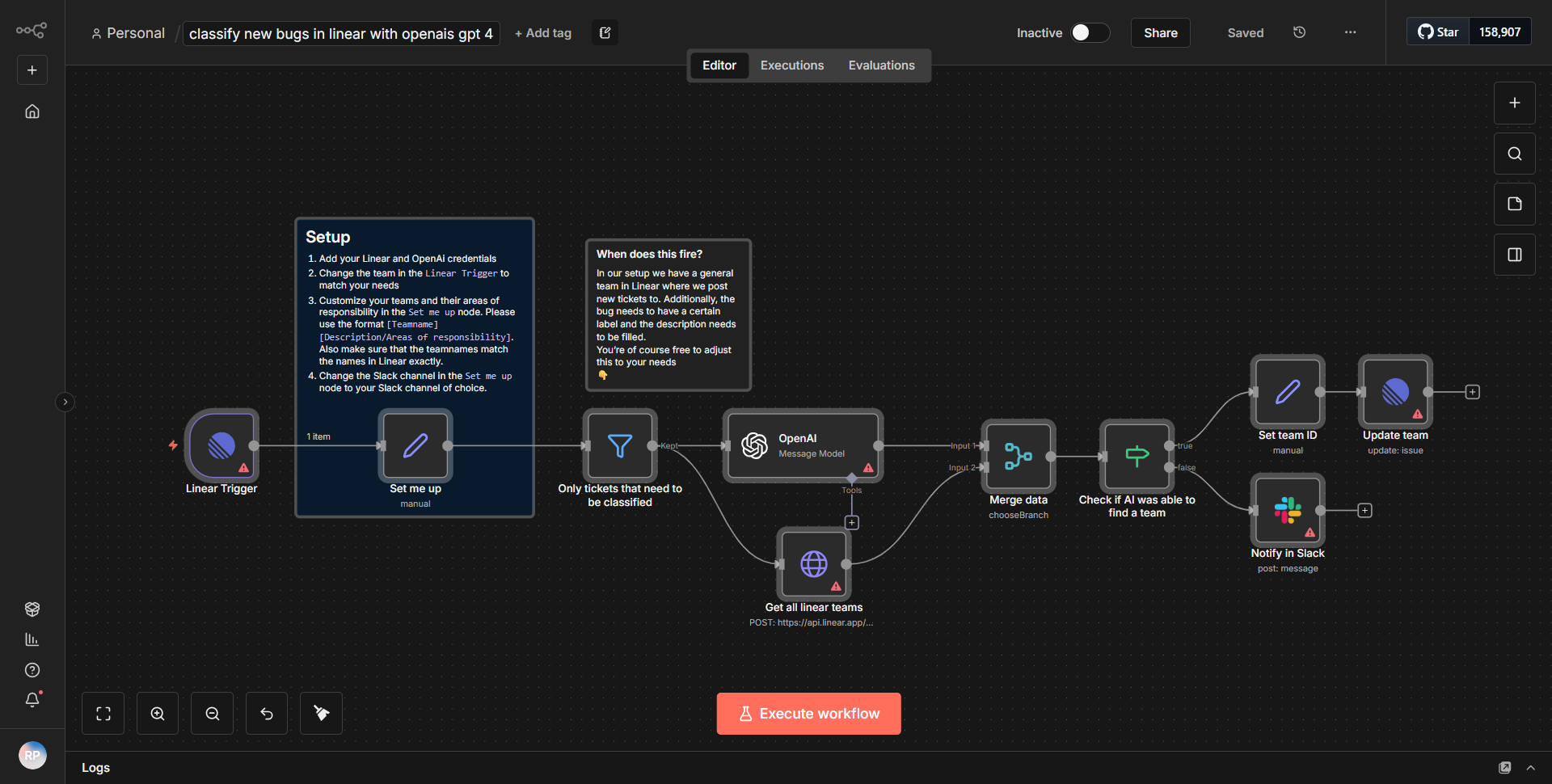
O fluxo de trabalho "Ferramenta KB - Repositório de conhecimento do Confluence" foi projetado para facilitar o gerenciamento de recursos da base de conhecimento no Confluence. O fluxo de trabalho começa com um nó acionador que inicia o processo com base em um evento específico, como uma nova entrada ou atualização na base de conhecimento.
1. Nó acionador:
o fluxo de trabalho começa com um acionador, que escuta alterações ou novas entradas na base de conhecimento.
2. Recuperação de dados:
uma vez acionado, o fluxo de trabalho recupera dados relevantes da API do Confluence. Isso normalmente é feito usando um nó de solicitação HTTP configurado para acessar a API REST do Confluence.
3. Processamento de dados:
após a busca dos dados, o fluxo de trabalho pode incluir nós para transformação ou filtragem de dados. Isso poderia envolver o uso de um nó Function para manipular o formato dos dados ou extrair campos específicos necessários para processamento posterior.
4. Lógica Condicional:
O fluxo de trabalho pode utilizar um nó If para determinar as próximas etapas com base nos dados recuperados. Por exemplo, pode verificar se a entrada já existe ou se atende a determinados critérios para ações futuras.
5. Atualização ou criação de dados:
Dependendo do resultado da lógica condicional, o fluxo de trabalho atualizará uma página existente do Confluence ou criará uma nova usando outro nó de solicitação HTTP configurado para solicitações POST ou PUT.
6. Notificação final:
Finalmente, o fluxo de trabalho pode incluir um nó de notificação para informar os usuários sobre a atualização bem-sucedida ou a criação de uma entrada na base de conhecimento, garantindo que as partes interessadas sejam mantidas informadas.
Esse fluxo estruturado garante que os recursos da base de conhecimento sejam gerenciados de forma eficiente e atualizados em tempo real.
Principais recursos
- Atualizações automatizadas:
o fluxo de trabalho automatiza o processo de atualização e gerenciamento de entradas da base de conhecimento no Confluence, reduzindo o esforço manual e possíveis erros.
- Tratamento de dados em tempo real:
Responde instantaneamente às mudanças na base de conhecimento, garantindo que as informações estejam sempre atualizadas.
- Processamento Condicional:
A inclusão de lógica condicional permite ações personalizadas com base nos dados recuperados, aumentando a flexibilidade e o controle sobre o fluxo de trabalho.
- Integração com o Confluence:
A integração perfeita com o Confluence permite que os usuários aproveitem os recursos avançados da plataforma para gerenciamento de conhecimento sem a necessidade de alternar entre aplicativos.
- Notificações do usuário:
o fluxo de trabalho inclui recursos de notificação para manter os usuários informados sobre as alterações, promovendo uma melhor comunicação entre as equipes.
Integração de ferramentas
- Confluence:
a principal ferramenta integrada a esse fluxo de trabalho, utilizada por meio de sua API REST para recuperação e atualizações de dados.
- Nó de solicitação HTTP:
usado para interagir com a API do Confluence para buscar e enviar dados.
- Nó de função:
empregado para transformação e processamento de dados dentro do fluxo de trabalho.
- If Node:
Utilizado para lógica condicional para determinar o fluxo com base nos dados recebidos.
Chaves de API necessárias
Para executar esse fluxo de trabalho com êxito, são necessárias as seguintes chaves de API e detalhes de autenticação:
- Token da API do Confluence:
necessário para autenticar solicitações à API do Confluence.
- URL base do Confluence:
o endpoint para acessar a instância do Confluence deve ser especificado nos nós de solicitação HTTP.
Nenhuma chave de API ou credencial adicional é necessária além daquelas especificadas para o Confluence.