返回列表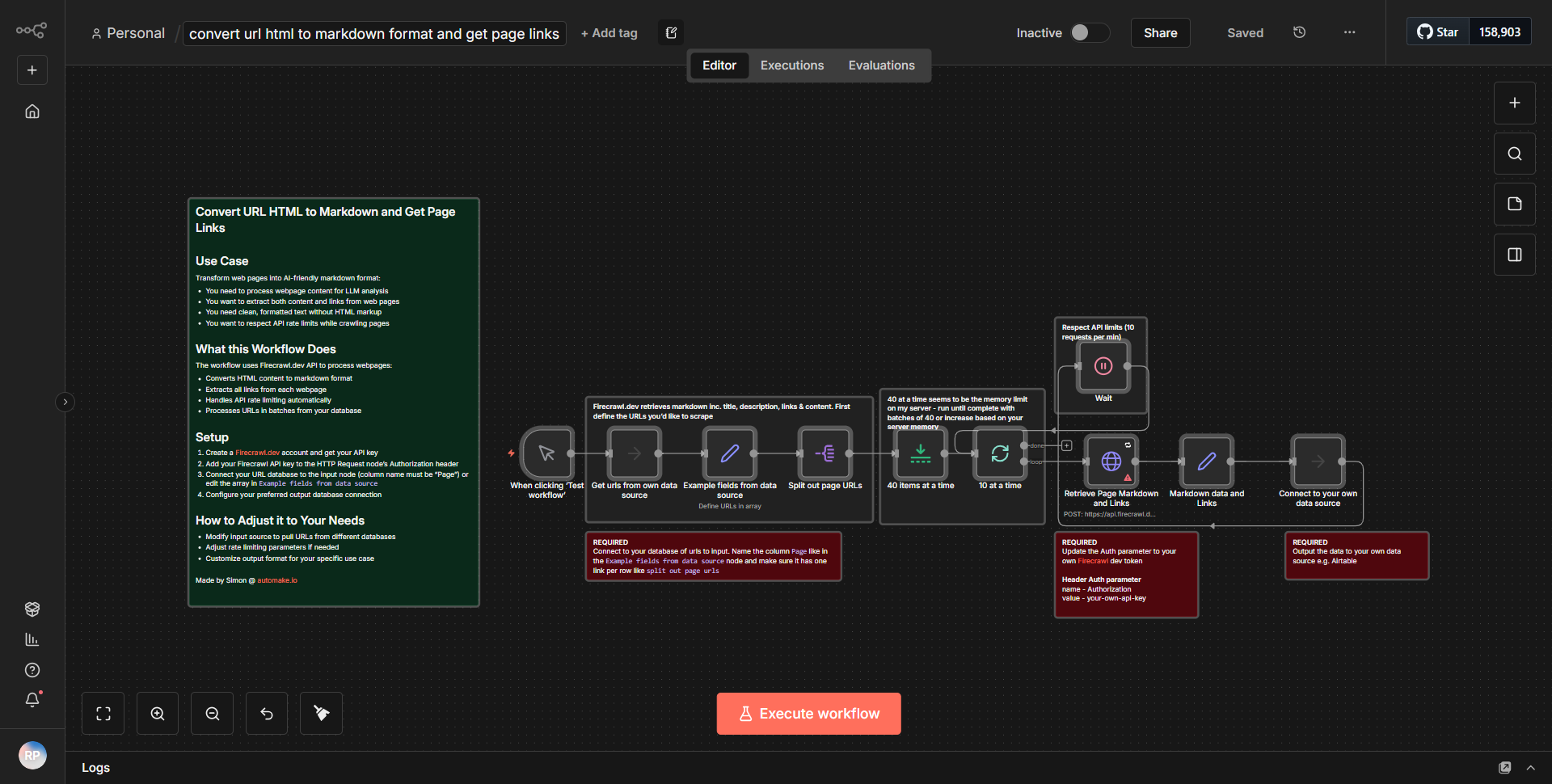
将 HTML URL 转换为 Markdown 格式并检索页面链接
Marketing/Content
此工作流程将从指定 URL 获取的 HTML 数据转换为 Markdown 格式,同时检索页面上存在的所有链接,这对于内容抓取和分析很有价值。
它是如何运作的
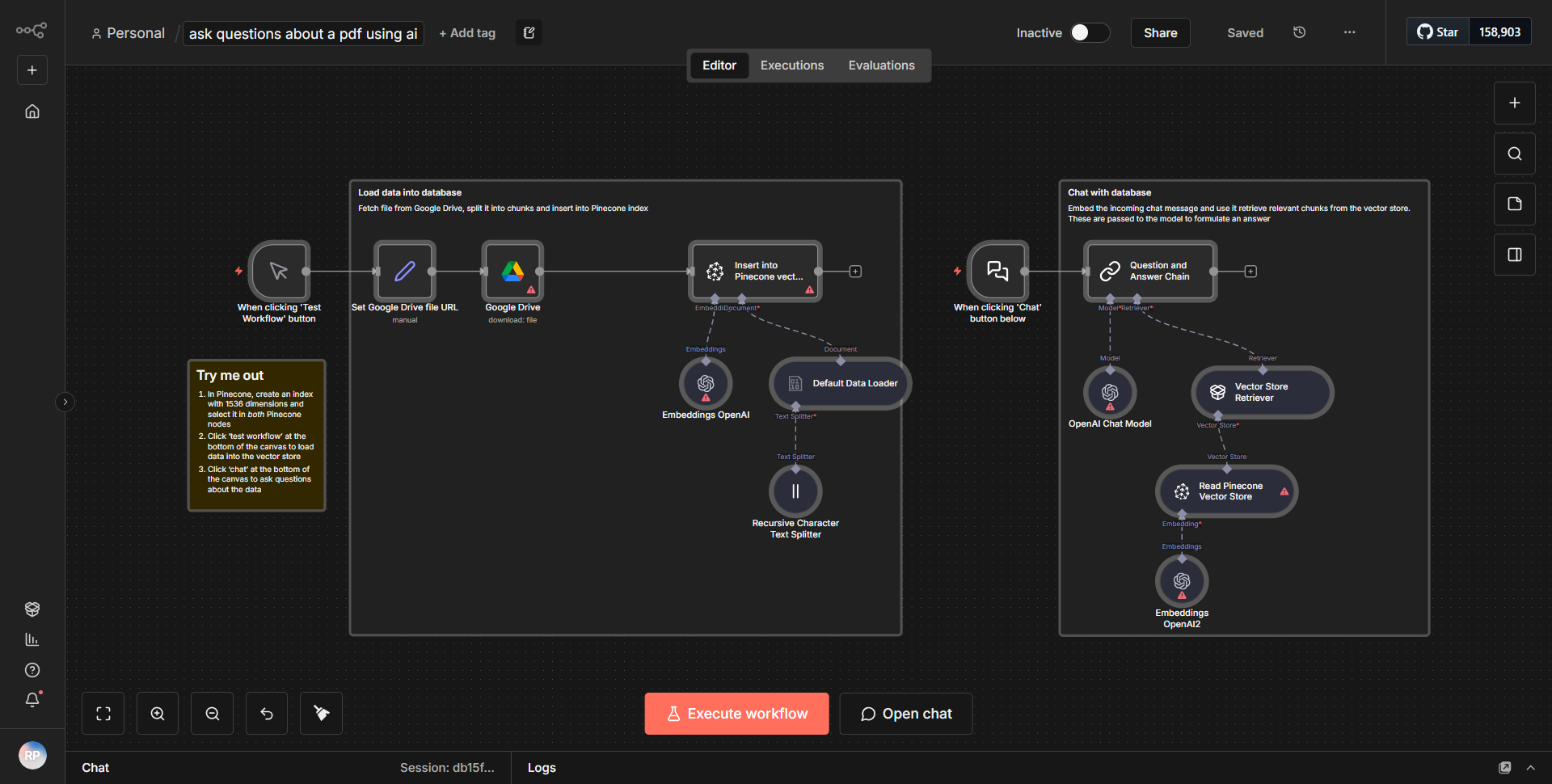
此工作流程从“HTTP 请求”节点开始,该节点配置为从指定 URL 获取 HTML 内容。收到响应后,HTML 数据被传递到“HTML Extract”节点。该节点负责解析 HTML 并提取页面上存在的所有超链接(锚标记)。然后使用“Function”节点将提取的链接格式化为 Markdown 友好格式,该节点处理数据以将 URL 转换为 Markdown 语法。最后,工作流程输出转换后的 Markdown 内容以及链接列表,使其适合内容抓取和分析。节点按顺序连接,确保数据从一个进程顺利流向下一进程。
主要特点
1. HTML 到 Markdown 转换
:该工作流程有效地将 HTML 内容转换为 Markdown 格式,广泛用于文档和内容管理。
2. 链接提取
:它从提供的 HTML 页面中检索所有超链接,允许用户收集有关内容结构和外部引用的有价值的信息。
3. 自动化流程
:整个工作流程自动化,使用户无需人工干预即可快速转换和提取数据。
4. 可自定义输入
:用户可以指定任何 URL 来获取 HTML 内容,使工作流程适用于不同的网页。
5. 数据输出
:最终输出包括Markdown内容和提取的链接列表,为进一步分析提供全面的数据。
工具集成
该工作流程集成了以下工具和服务:
- HTTP 请求节点
:用于进行 HTTP 调用以从指定 URL 检索 HTML 内容。
- HTML 提取节点
:用于解析 HTML 响应并提取超链接。
- 功能节点
:用于将提取的链接格式化为 Markdown 语法。
需要 API 密钥
此工作流程无需 API 密钥、凭据或身份验证配置即可运行。它仅基于对指定 URL 的 HTTP 请求进行操作,无需额外设置即可用于一般用途。