使用多模态视觉 AI 进行简历 PDF 分析
该工作流程将候选人简历 PDF 转换为图像,采用视觉语言模型来评估候选人的适合性,并结合逻辑来规避简历中隐藏的人工智能提示。
它是如何运作的
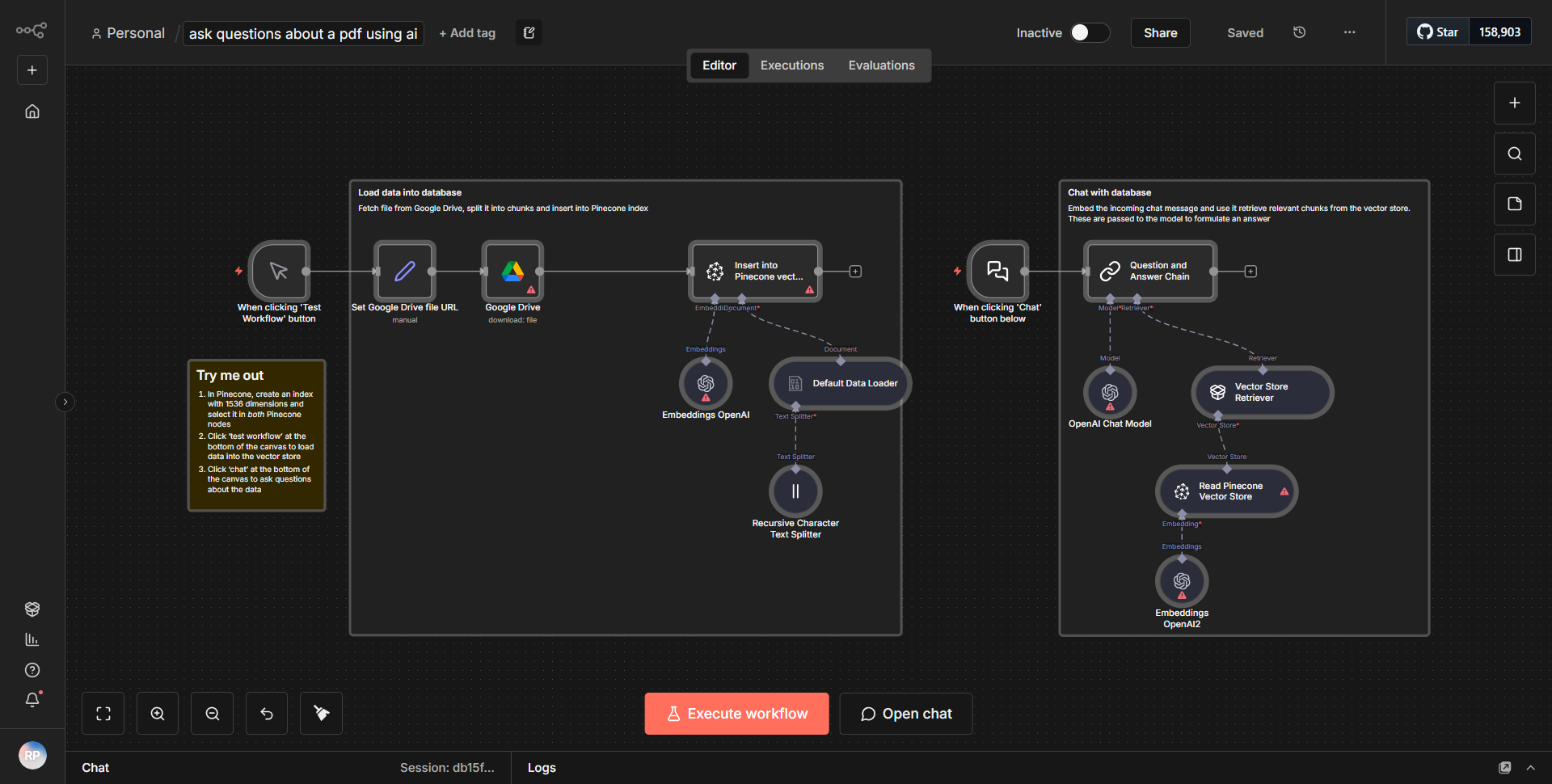
名为“使用多模态视觉 AI 进行简历 PDF 分析”的工作流程通过系统地将候选简历 PDF 转换为图像,使用视觉语言模型分析这些图像,并实现逻辑来检测和规避简历中隐藏的 AI 提示。
1. PDF 输入
:工作流程从一个触发节点开始,该节点侦听上传到指定目录的新 PDF 文件。每当检测到新的恢复时,该节点就会启动该过程。
2. PDF 到图像转换
:收到 PDF 后,工作流程将利用一个节点将 PDF 页面转换为图像。此步骤至关重要,因为它为可视化分析准备内容。
3. 视觉语言模型分析
:从 PDF 生成的图像随后被传递到视觉语言模型节点。该节点评估图像,以根据预定义的标准评估候选者的适用性。该模型分析视觉内容并提取相关信息。
4. AI提示检测逻辑
:分析后,工作流程包括一个逻辑节点,用于检查简历中隐藏的AI提示。此步骤旨在识别任何操纵人工智能评估过程的尝试。
5. 输出生成
:最后,分析结果(包括候选适合性分数和任何检测到的提示)被编译并发送到指定的输出节点。这可能涉及将结果存储在数据库中或通过电子邮件将其发送给招聘经理。
主要特点
- 自动 PDF 处理
:工作流程自动将简历 PDF 转换为图像,消除手动干预并加快分析过程。
- 多模态分析
:通过利用视觉语言模型,工作流程不仅可以基于文本,还可以基于视觉元素评估简历,从而对候选人进行更全面的评估。
- 人工智能提示检测
:包含识别隐藏人工智能提示的逻辑,增强了评估过程的完整性,确保根据候选人的实际资格对其进行公平评估。
- 可定制的输出
:工作流程允许灵活的输出选项,使组织能够定制他们接收和利用分析结果的方式。
工具集成
该工作流程通过特定的 n8n 节点集成了多种工具和服务:
- PDF 输入节点
:监视新 PDF 文件的目录。
- PDF 到图像节点
:将 PDF 页面转换为图像以进行分析。
- 视觉语言模型节点
:分析图像以评估候选者的适用性。
- 逻辑节点
:实现对简历中隐藏的人工智能提示的检查。
- 输出节点
:编译分析结果并将其发送到所需的目的地。
需要 API 密钥
此工作流程无需 API 密钥、凭据或身份验证配置即可运行。所有操作均使用 n8n 及其节点的内置功能执行。