文本处理 ETL 工作流程
该工作流程建立了一个用于文本分析的 ETL 管道,从 Twitter 检索信息,将其保存在 MongoDB 和 PostgreSQL 中,并根据情绪评估向 Slack 发送警报。
它是如何运作的
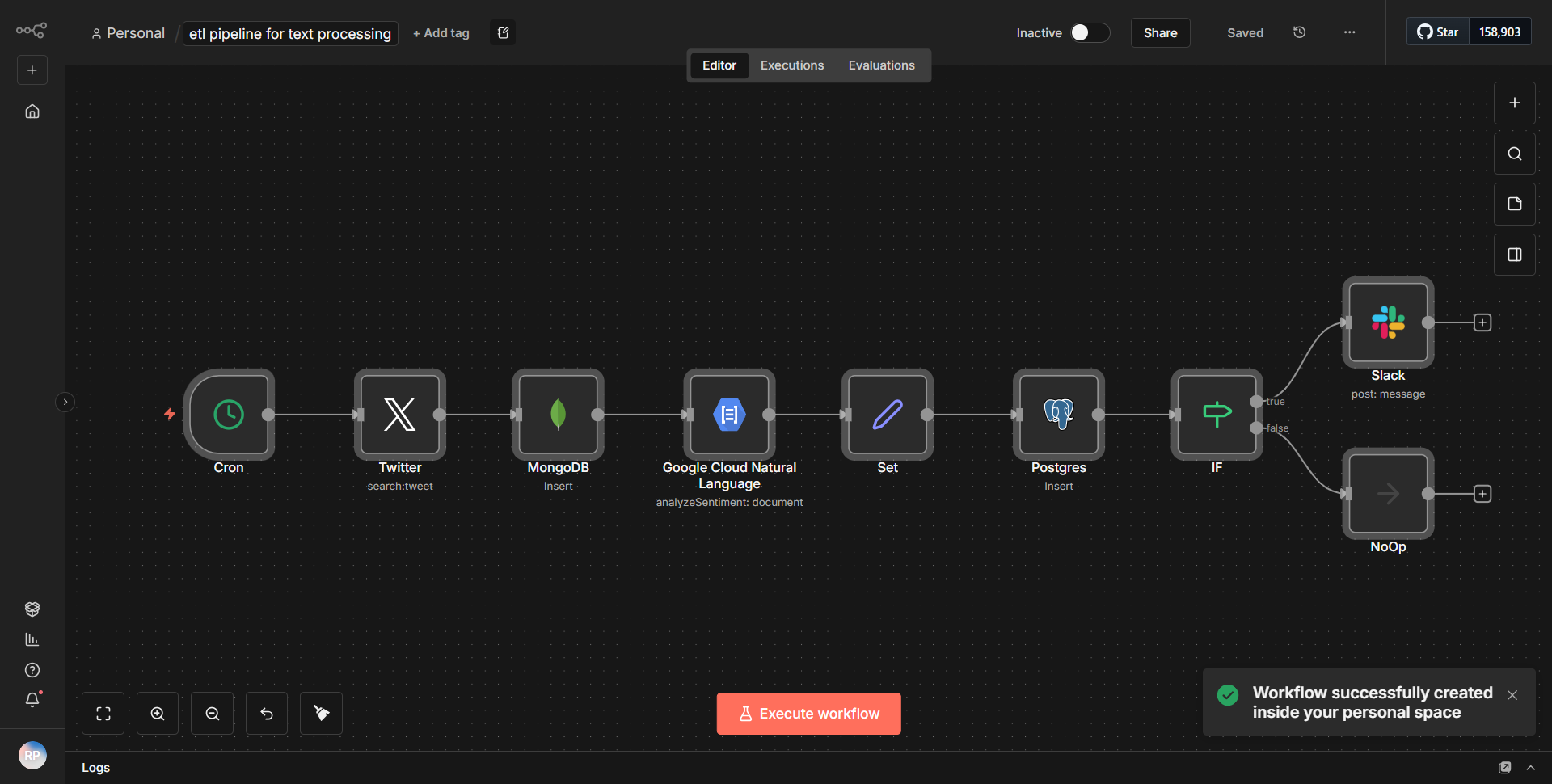
文本处理 ETL 工作流程旨在促进文本分析的端到端管道,特别关注从 Twitter 检索数据、存储在 MongoDB 和 PostgreSQL 中,以及基于情绪评估向 Slack 发送警报。工作流程以顺序方式运行,利用各个节点来确保数据流动和处理的顺利进行。
1. Twitter 节点
:工作流程从 Twitter 节点开始,该节点配置为根据特定搜索条件检索推文。该节点负责获取与定义的参数(例如关键字或主题标签)匹配的实时推文。
2. 情感分析节点
:检索到推文后,它们将被传递到情感分析节点。该节点处理推文的文本以评估其情绪,将其分类为积极、消极或中立。此分析的结果对于工作流程中的后续步骤至关重要。
3. MongoDB 节点
:情感评估后,工作流程将处理后的推文数据及其情感分数定向到 MongoDB 节点。该节点配置为将推文信息插入 MongoDB 集合中,以便高效存储和检索数据以供将来分析。
4. PostgreSQL节点
:同时,将相同的处理后的数据发送到PostgreSQL节点。该节点的设置是将推文信息插入到 PostgreSQL 数据库中,确保数据以关系格式存储,这对于结构化查询和报告非常有用。
5. Slack节点
:最后,基于情感分析结果,工作流利用Slack节点发送警报。如果一条推文被归类为具有负面情绪,则会向指定的 Slack 频道发送警报,通知团队成员可能存在相关内容。
这种结构化流程确保数据不仅被收集和分析,而且以多种格式存储并有效地传达给相关利益相关者。
主要特点
- 实时数据检索
:工作流程不断从 Twitter 获取推文,从而能够及时分析各种主题的公众情绪。
- 情绪分析
:情绪分析的集成提供了对公众舆论的宝贵见解,可以主动应对负面情绪。
- 多数据库存储
:通过将数据存储在 MongoDB 和 PostgreSQL 中,工作流程提供了数据管理的灵活性,满足不同的用例和查询要求。
- 自动警报
:Slack 集成可确保利益相关者及时获悉重大情绪变化,从而促进快速决策和行动。
- 可扩展性
:可以轻松修改工作流程以包含其他数据源或处理步骤,使其能够适应不断变化的分析需求。
工具集成
- Twitter 节点
:用于根据指定的搜索条件获取推文。
- 情绪分析节点
:处理推文文本以确定其情绪。
- MongoDB Node
:将推文数据存储在 MongoDB 数据库中,用于非结构化数据管理。
- PostgreSQL 节点
:将推文数据插入 PostgreSQL 数据库以进行结构化数据管理。
- Slack 节点
:根据推文的情绪评估向 Slack 通道发送警报。
需要 API 密钥
- Twitter API 密钥
:验证和访问 Twitter 数据所需。
- MongoDB 连接字符串
:需要连接到 MongoDB 数据库。
- PostgreSQL 连接字符串
:连接到 PostgreSQL 数据库所需。
- Slack Webhook URL
:将消息发送到指定的 Slack 通道所必需的。
此工作流程需要正确配置 API 密钥和连接字符串才能有效运行,确保对相应服务的安全且经过身份验证的访问。