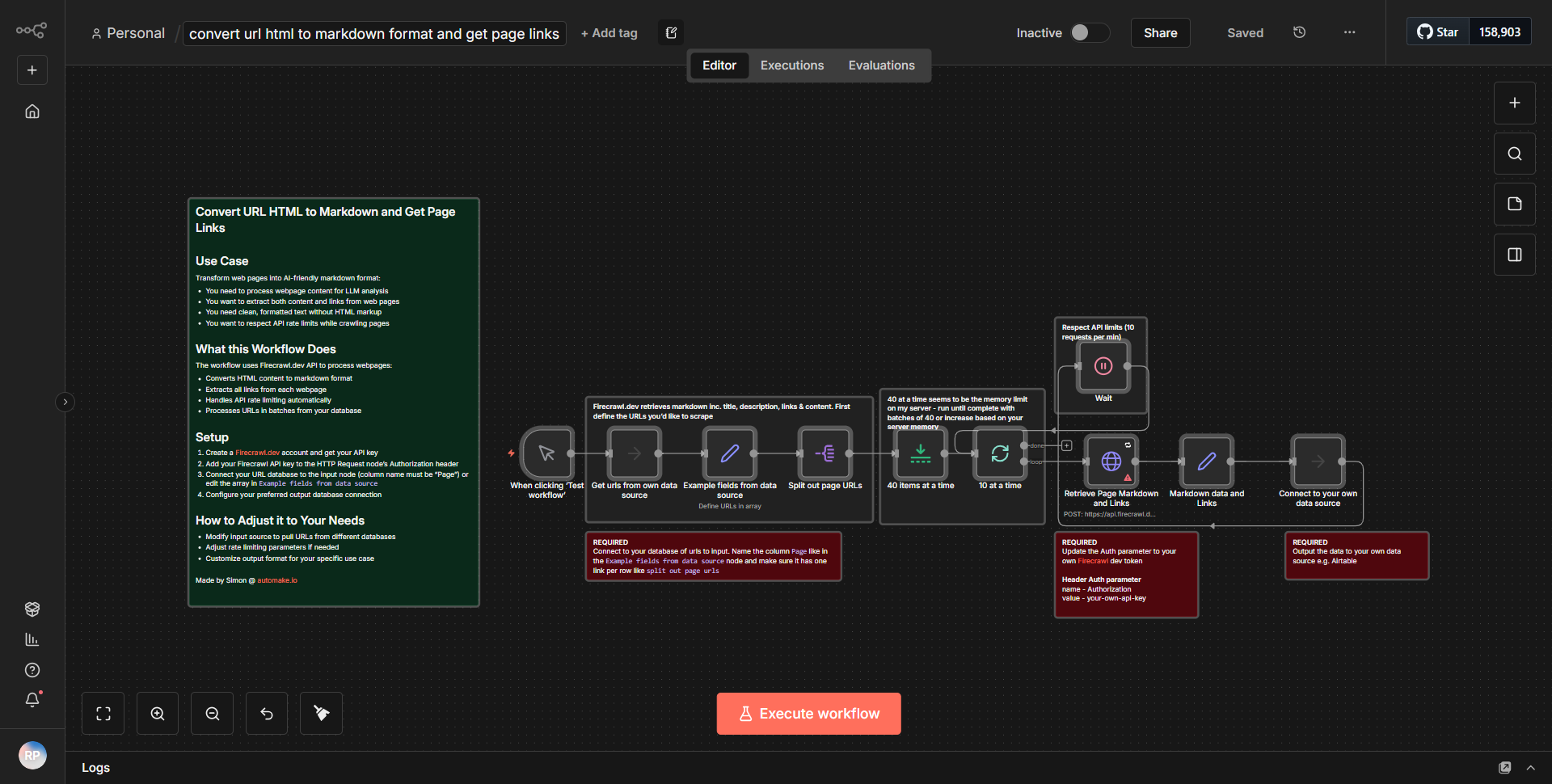
Transforme URLs HTML em formato Markdown e recupere links de páginas
Este fluxo de trabalho transforma dados HTML provenientes de um URL especificado no formato Markdown, ao mesmo tempo que recupera todos os links presentes na página, tornando-os valiosos para extração e análise de conteúdo.
Como funciona
Este fluxo de trabalho começa com o nó "Solicitação HTTP", que está configurado para buscar conteúdo HTML de um URL especificado. Ao receber a resposta, os dados HTML são passados para o nó "HTML Extract". Este nó é responsável por analisar o HTML e extrair todos os hiperlinks (tags âncora) presentes na página. Os links extraídos são então formatados em um formato compatível com Markdown usando o nó "Função", que processa os dados para converter os URLs em sintaxe Markdown. Por fim, o fluxo de trabalho gera o conteúdo Markdown transformado junto com a lista de links, tornando-o adequado para extração e análise de conteúdo. Os nós são conectados sequencialmente, garantindo um fluxo suave de dados de um processo para outro.
Principais recursos
1. Conversão de HTML para Markdown:
O fluxo de trabalho transforma efetivamente o conteúdo HTML no formato Markdown, que é amplamente utilizado para documentação e gerenciamento de conteúdo.
2. Extração de link:
recupera todos os hiperlinks da página HTML fornecida, permitindo aos usuários coletar informações valiosas sobre a estrutura do conteúdo e referências externas.
3. Processo automatizado:
todo o fluxo de trabalho é automatizado, permitindo que os usuários convertam e extraiam dados rapidamente sem intervenção manual.
4. Entrada personalizável:
os usuários podem especificar qualquer URL para buscar conteúdo HTML, tornando o fluxo de trabalho versátil para diferentes páginas da web.
5. Saída de dados:
A saída final inclui o conteúdo do Markdown e a lista de links extraídos, fornecendo dados abrangentes para análise posterior.
Integração de ferramentas
O fluxo de trabalho integra as seguintes ferramentas e serviços:
- Nó de solicitação HTTP:
usado para fazer uma chamada HTTP para recuperar conteúdo HTML de um URL especificado.
- Nó de extração HTML:
utilizado para analisar a resposta HTML e extrair hiperlinks.
- Nó de Função:
Empregado para formatar os links extraídos na sintaxe Markdown.
Chaves de API necessárias
Nenhuma chave de API, credencial ou configuração de autenticação é necessária para que esse fluxo de trabalho funcione. Ele opera exclusivamente com base na solicitação HTTP para o URL especificado, tornando-o acessível para uso geral sem configuração adicional.