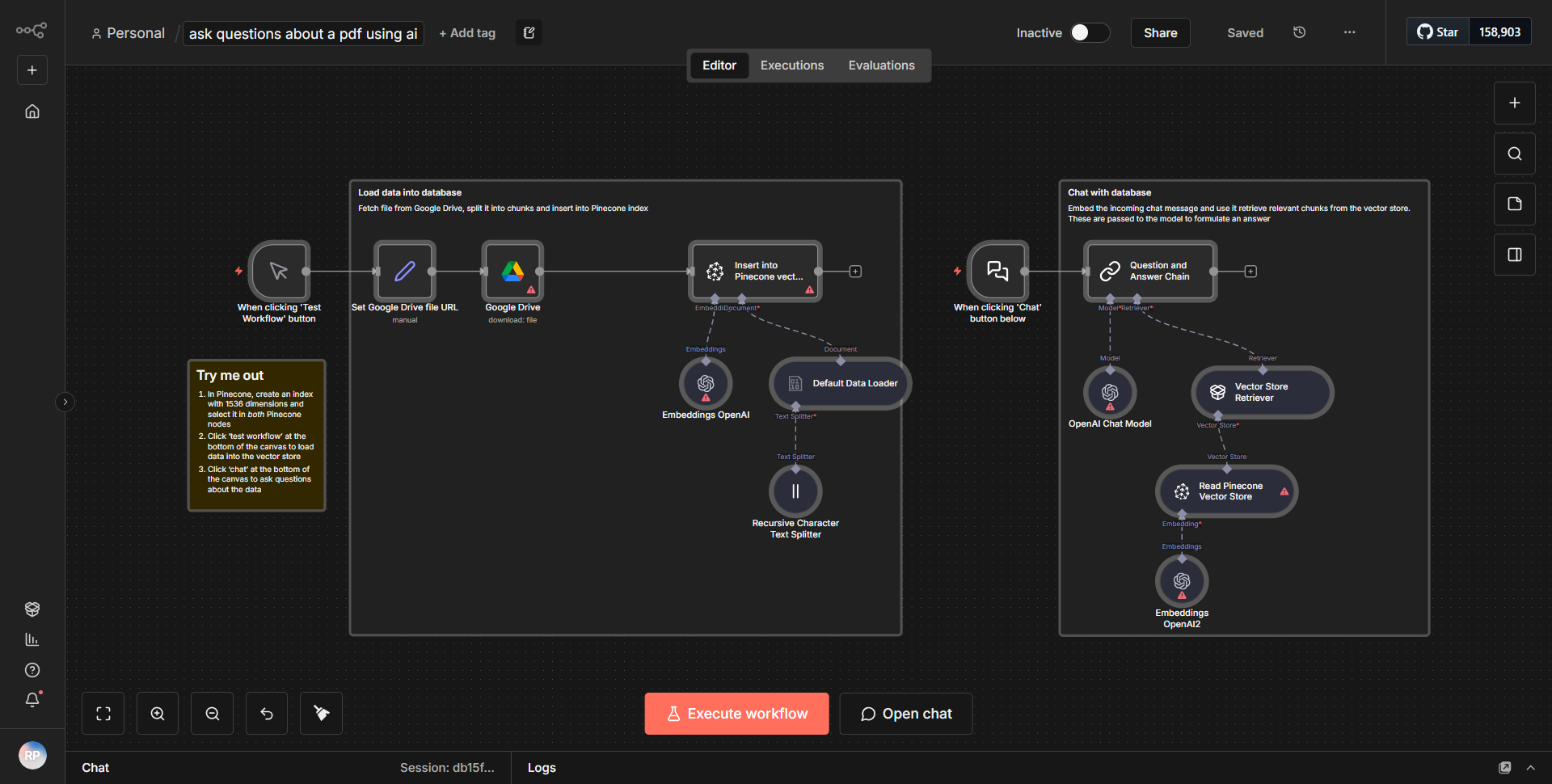
Pergunte sobre um PDF utilizando IA
Este fluxo de trabalho recupera um arquivo PDF do Google Drive, divide-o em segmentos, processa os segmentos com incorporações OpenAI e facilita interações conversacionais com o conteúdo do documento.
Como funciona
Este fluxo de trabalho começa recuperando um arquivo PDF do Google Drive usando o nó do Google Drive. O nó é configurado para procurar um arquivo específico com base em seu nome ou ID, garantindo que o documento correto seja acessado. Assim que o PDF for recuperado, o fluxo de trabalho prossegue para o nó "Extração de PDF", que extrai o conteúdo do texto do arquivo PDF. Este texto extraído é então segmentado em partes menores para facilitar o processamento.
Após a extração e segmentação, o fluxo de trabalho utiliza o nó OpenAI para gerar embeddings para cada segmento de texto. Esta etapa é crucial porque transforma os dados textuais em um formato que pode ser compreendido e processado por algoritmos de IA. As incorporações permitem consultas e interações mais eficientes com o conteúdo do documento.
Após a criação dos embeddings, o fluxo de trabalho incorpora uma interface conversacional, permitindo aos usuários fazer perguntas sobre o conteúdo do PDF. Isto é conseguido através de uma série de nós que tratam a entrada do usuário, processam as consultas e retornam respostas relevantes com base nos embeddings gerados anteriormente. O fluxo de trabalho cria efetivamente um ciclo onde as consultas dos usuários podem ser processadas continuamente, permitindo uma experiência interativa com o conteúdo do PDF.
Principais recursos
1. Recuperação de PDF:
o fluxo de trabalho se integra perfeitamente ao Google Drive para buscar documentos PDF, facilitando o acesso a arquivos armazenados na nuvem.
2. Extração de Texto:
Emprega um nó dedicado para extrair texto de arquivos PDF, garantindo que todas as informações relevantes estejam disponíveis para processamento.
3. Segmentação de conteúdo:
O texto extraído é dividido em segmentos gerenciáveis, o que aumenta a eficiência do processamento de IA e permite respostas mais precisas às dúvidas dos usuários.
4. Integrações de IA:
Ao utilizar embeddings OpenAI, o fluxo de trabalho transforma o texto em um formato vetorial, permitindo recursos avançados de IA para compreender e responder às dúvidas dos usuários.
5. Interface Conversacional:
O fluxo de trabalho suporta um formato dinâmico de perguntas e respostas, permitindo que os usuários se envolvam interativamente com o conteúdo do PDF, tornando-o uma ferramenta poderosa para recuperação e aprendizagem de informações.
Integração de ferramentas
- Google Drive:
usado para recuperar o arquivo PDF. O nó do Google Drive está configurado para acessar arquivos específicos com base em parâmetros definidos pelo usuário.
- Extração de PDF:
Este nó é responsável por extrair o texto do documento PDF, garantindo que o conteúdo esteja disponível para processamento posterior.
- OpenAI:
O nó OpenAI é utilizado para gerar embeddings a partir dos segmentos de texto extraídos, permitindo interações sofisticadas de IA.
- Webhook:
Este nó permite o recebimento de dúvidas dos usuários, facilitando o aspecto conversacional do fluxo de trabalho.
Chaves de API necessárias
Para operar este fluxo de trabalho, são necessárias as seguintes chaves e credenciais de API:
- Chave de API do Google Drive:
necessária para autenticar e acessar arquivos armazenados no Google Drive.
- Chave de API OpenAI:
necessária para utilizar os serviços OpenAI para gerar incorporações e processar consultas de usuários.
Nenhuma chave de API ou credencial de autenticação adicional é necessária além das mencionadas acima.