Extraia e condense artigos de um site de notícias sem feed RSS utilizando IA e armazene os resultados no NocoDB.
Extrai e condensa artigos de notícias que não possuem feeds RSS utilizando IA, com os resultados armazenados no NocoDB.
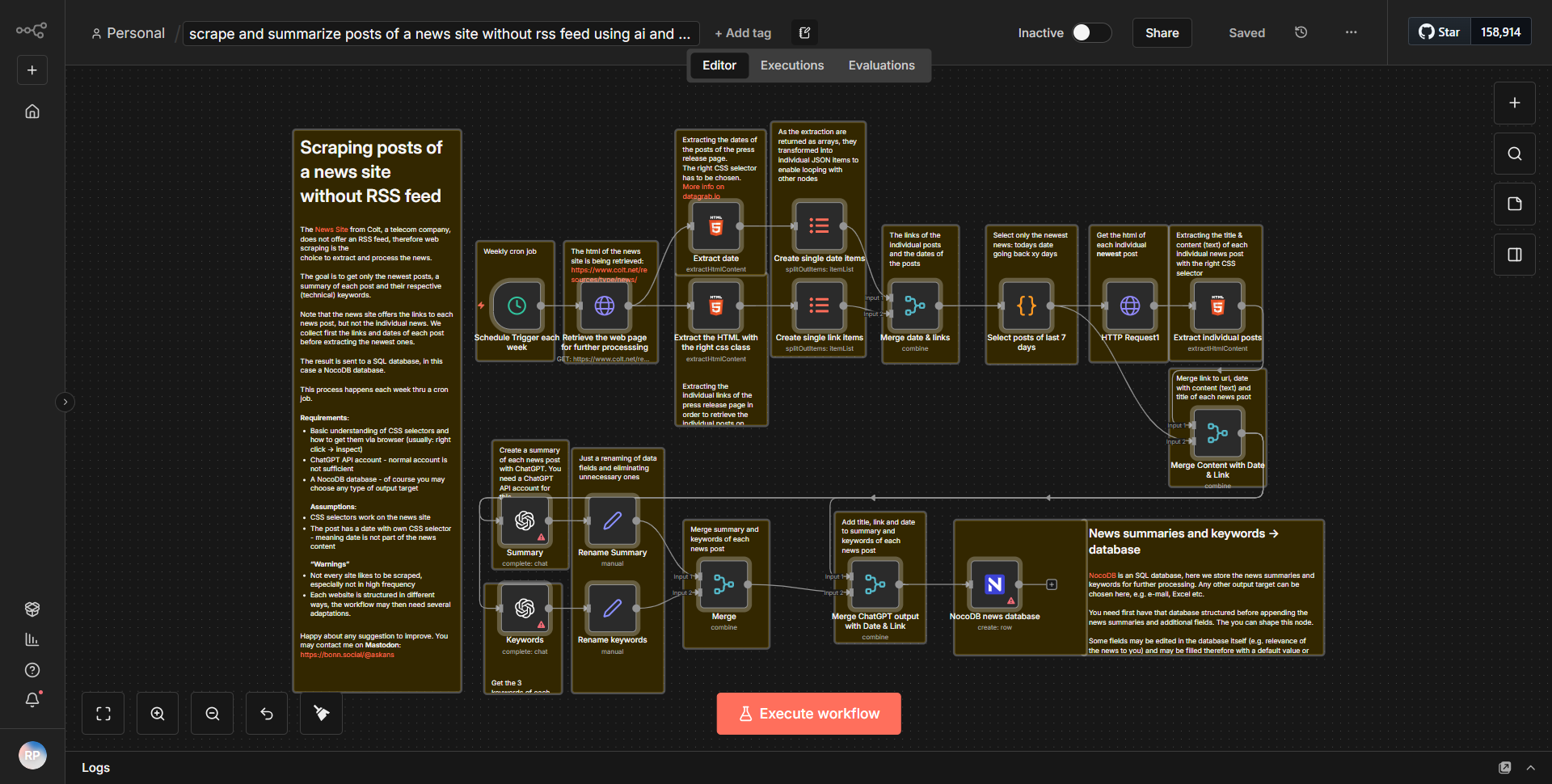
Como funciona
O fluxo de trabalho começa com um nó
Solicitação HTTP
configurado para buscar o conteúdo HTML de um site de notícias específico que não fornece um feed RSS. Este nó está configurado para realizar uma solicitação GET para a URL de destino, recuperando todo o conteúdo da página. A saída deste nó é o HTML bruto, que é então passado para o próximo nó para processamento.Após o nó Solicitação HTTP, há um nó
Extração HTML
. Este nó é responsável por analisar o conteúdo HTML recuperado na etapa anterior. Ele utiliza seletores CSS para identificar e extrair elementos específicos do HTML, como títulos de artigos, datas de publicação e corpo principal dos artigos. Os dados extraídos são estruturados em um formato mais gerenciável, normalmente como JSON.Em seguida, o fluxo de trabalho inclui um nó
Function
que processa ainda mais os dados extraídos. Neste nó, os artigos são condensados utilizando técnicas de IA. Isto pode envolver resumir o conteúdo ou extrair pontos-chave, dependendo da implementação específica. A saída deste nó é uma versão resumida dos artigos, pronta para armazenamento.A etapa final do fluxo de trabalho é um nó
NocoDB
, que é usado para armazenar os artigos resumidos em um banco de dados NocoDB. Este nó está configurado para criar novos registros em uma tabela específica, onde cada registro corresponde a um artigo resumido. Os dados enviados ao NocoDB incluem o título, o resumo e quaisquer outros metadados relevantes extraídos anteriormente.Ao longo do fluxo de trabalho, os dados fluem sequencialmente de um nó para o próximo, transformando HTML bruto em conteúdo estruturado e resumido que é armazenado em um banco de dados para fácil acesso e gerenciamento.
Principais recursos
1. Resumo baseado em IA:
o fluxo de trabalho utiliza técnicas de IA para condensar artigos longos em resumos concisos, tornando mais fácil para os usuários compreenderem rapidamente as informações essenciais.
2. Extração de conteúdo HTML:
ao extrair conteúdo HTML diretamente de sites sem feeds RSS, o fluxo de trabalho pode reunir artigos de notícias de diversas fontes que, de outra forma, seriam inacessíveis.
3. Integração com NocoDB:
A capacidade de armazenar artigos resumidos no NocoDB permite o gerenciamento organizado de dados e fácil recuperação, facilitando análises ou relatórios adicionais.
4. Extração de dados personalizável:
O uso de seletores CSS no nó HTML Extract permite que os usuários personalizem quais elementos dos artigos desejam extrair, proporcionando flexibilidade com base em diferentes estruturas do site.
5. Fluxo de trabalho automatizado:
Todo o processo é automatizado, reduzindo a necessidade de coleta e resumo manual de dados, economizando tempo e esforço para os usuários.
Integração de ferramentas
- Nó de solicitação HTTP:
usado para buscar conteúdo HTML do site de notícias especificado.
- Nó de extração HTML:
analisa o HTML e extrai dados relevantes do artigo usando seletores CSS.
- Nó de Função:
Processa os dados extraídos e utiliza IA para resumo.
- NocoDB Node:
Armazena os artigos resumidos em um banco de dados NocoDB para gerenciamento estruturado de dados.
Chaves de API necessárias
Nenhuma chave de API ou credencial de autenticação é necessária para que este fluxo de trabalho funcione. Os nós utilizados operam sem necessidade de acesso API externo, contando apenas com a solicitação HTTP ao site de notícias e a integração com NocoDB para armazenamento de dados.









