Rastreador da Web com IA autossuficiente
Um web scraper autossuficiente baseado em IA para coletar e analisar dados.
Como funciona
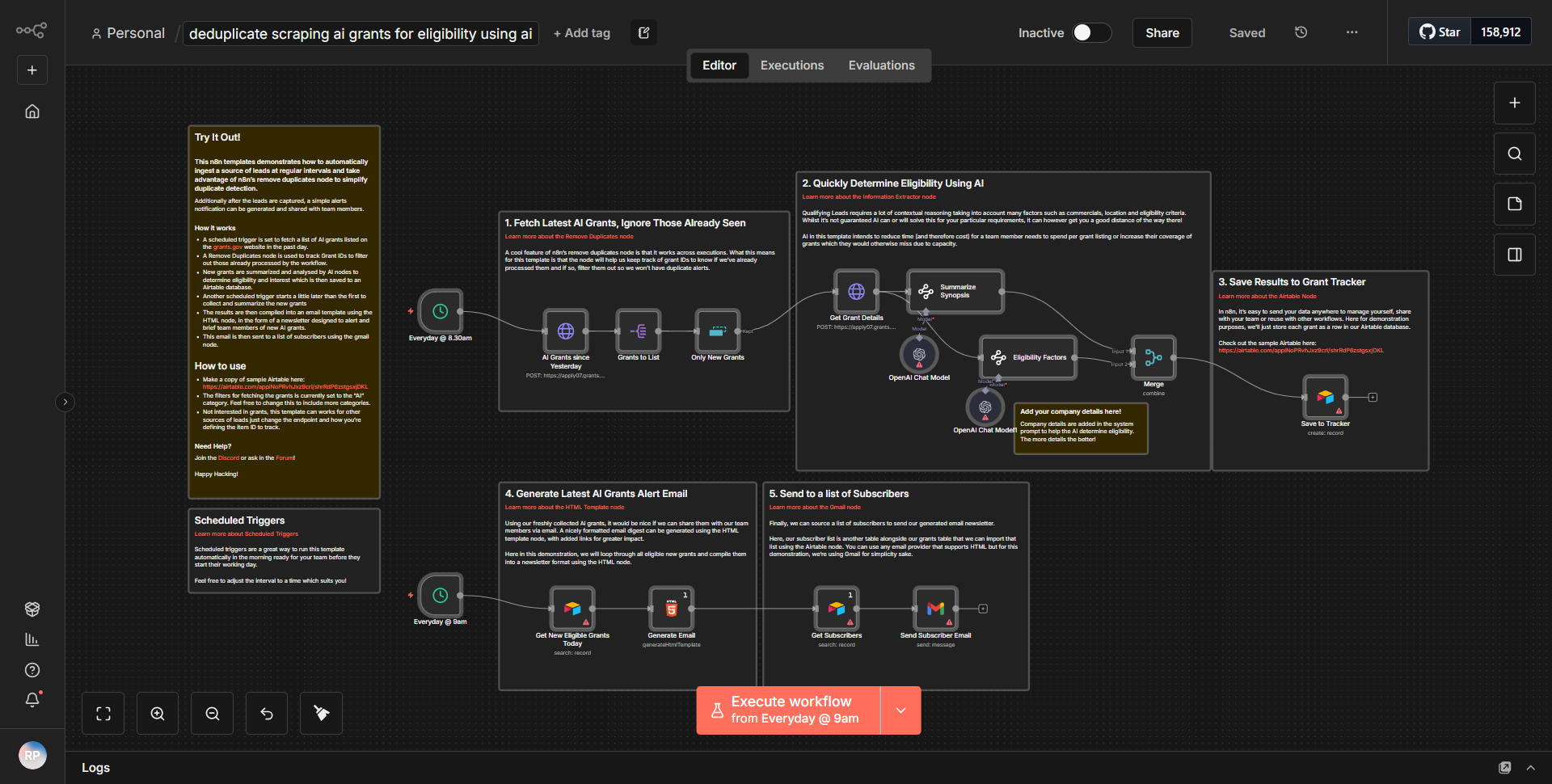
O fluxo de trabalho "Rastreador da Web com IA autossuficiente" opera como um raspador da Web autônomo projetado para coletar e analisar dados da Internet. O fluxo de trabalho começa com um nó acionador que inicia o processo de extração com base em um cronograma ou evento definido. Uma vez acionado, o fluxo de trabalho segue um fluxo sistemático de dados através de vários nós.
1. Iniciar nó:
o fluxo de trabalho é iniciado de acordo com um agendamento ou por meio de um webhook, dependendo da configuração.
2. Nó de solicitação HTTP:
Este nó é responsável por enviar uma solicitação ao site de destino. Recupera o conteúdo HTML do URL especificado.
3. Nó de extração HTML:
após obter o conteúdo HTML, esse nó analisa os dados para extrair informações relevantes, como títulos, links ou elementos de texto específicos com base em seletores predefinidos.
4. Nó de Função:
Este nó processa ainda mais os dados extraídos, aplicando quaisquer transformações ou cálculos necessários. Também pode incluir lógica para filtrar ou formatar os dados para melhor usabilidade.
5. Nó de armazenamento de dados:
Os dados processados são então armazenados em um banco de dados ou serviço em nuvem para referência e análise futuras. Isso pode envolver nós como Planilhas Google, Airtable ou uma integração de banco de dados personalizada.
6. Nó de Notificação:
Finalmente, o fluxo de trabalho pode incluir um sistema de notificação que alerta o usuário sobre a conclusão da tarefa de scraping ou quaisquer descobertas significativas. Isso pode ser por e-mail, Slack ou outro serviço de mensagens.
Os nós são interconectados de forma linear, garantindo que os dados fluam perfeitamente de uma etapa para a próxima, permitindo a coleta e o processamento eficientes de dados.
Principais recursos
- Operação autônoma:
o fluxo de trabalho foi projetado para ser executado sem intervenção manual, tornando-o adequado para coleta contínua de dados.
- Extração de dados:
capaz de extrair pontos de dados específicos de páginas da web usando seletores personalizáveis, permitindo que os usuários adaptem o processo de extração às suas necessidades.
- Processamento de Dados:
Inclui funcionalidade para processar e transformar os dados extraídos, garantindo que estejam em um formato utilizável para análise.
- Integração de armazenamento:
oferece suporte a diversas soluções de armazenamento, permitindo que os usuários salvem seus dados em formatos e locais preferidos para fácil acesso e análise.
- Sistema de Notificação:
Fornece alertas e notificações após a conclusão de tarefas ou quando condições específicas são atendidas, mantendo os usuários informados sobre o status do fluxo de trabalho.
Integração de ferramentas
O fluxo de trabalho se integra a diversas ferramentas e serviços para aprimorar sua funcionalidade:
- Nó de solicitação HTTP:
usado para buscar dados de sites de destino.
- Nó de extração HTML:
analisa o conteúdo HTML para extrair dados relevantes.
- Nó de função:
executa processamento e transformações de dados personalizados.
- Nós de banco de dados:
integra-se a serviços como Google Sheets ou Airtable para armazenamento de dados.
- Nós de notificação:
envia alertas por e-mail ou plataformas de mensagens como o Slack.
Chaves de API necessárias
Nenhuma chave de API ou credencial de autenticação é necessária para a funcionalidade básica deste fluxo de trabalho. No entanto, se o fluxo de trabalho for integrado a serviços específicos (como Planilhas Google ou Airtable), os usuários precisarão fornecer as chaves de API ou tokens de autenticação necessários para esses serviços para permitir o armazenamento e a recuperação de dados.