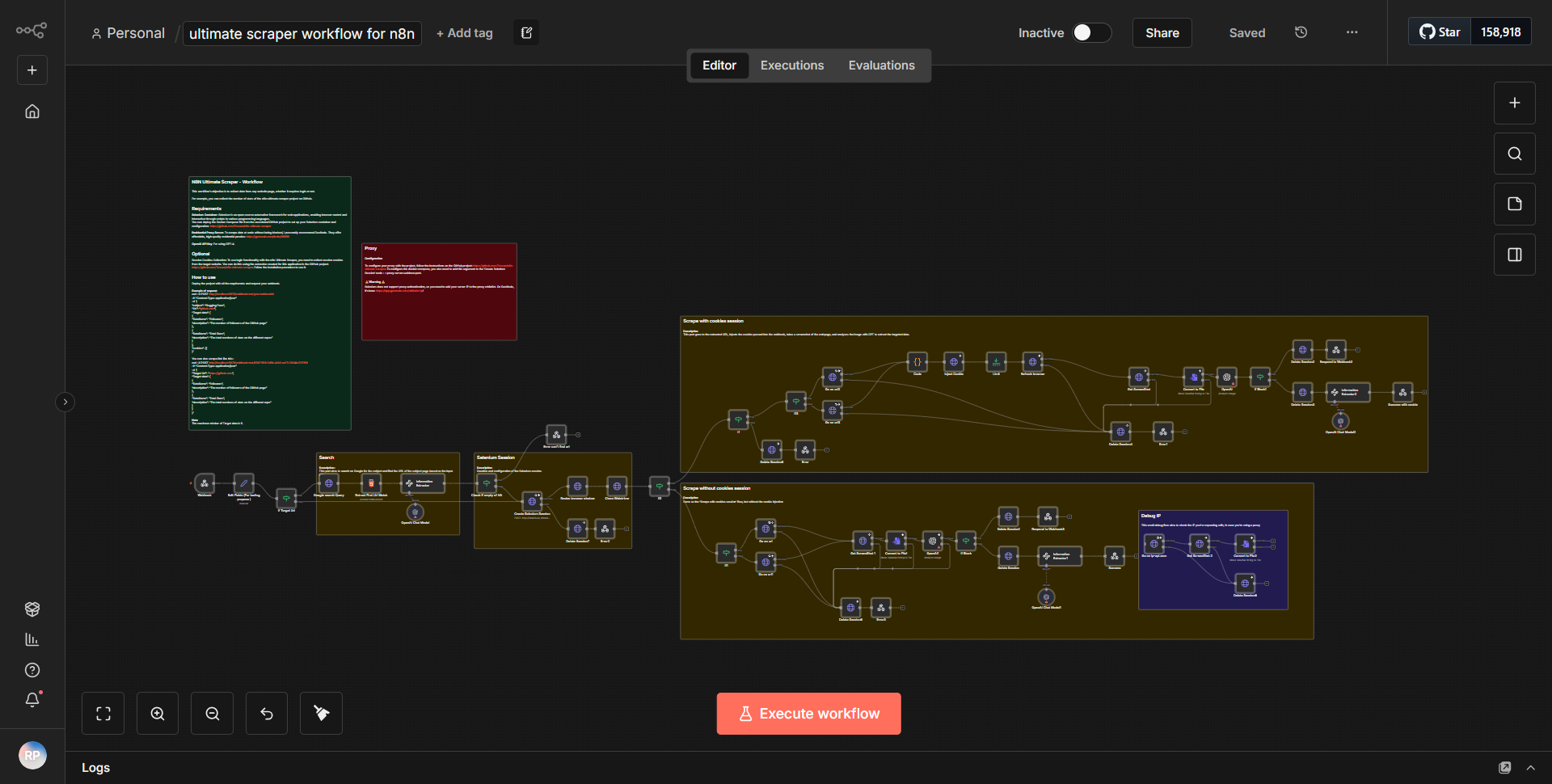
Fluxo de trabalho abrangente do raspador para n8n
Um extenso fluxo de trabalho de extração de dados para n8n projetado para coletar informações de diversas fontes.
Como funciona
O fluxo de trabalho abrangente do Scraper para n8n foi projetado para extrair dados de várias fontes de maneira estruturada. O fluxo de trabalho começa com um
nó Cron
, que aciona o processo em intervalos especificados. Este nó está configurado para executar o fluxo de trabalho diariamente, garantindo que os dados sejam coletados regularmente.Seguindo o nó Cron, o fluxo de trabalho utiliza um
nó de solicitação HTTP
para buscar dados de um URL especificado. Este nó está configurado para executar uma solicitação GET, permitindo recuperar o conteúdo HTML da página da web de destino. A saída desse nó é então passada para umnó HTML Extract
, que é responsável por analisar o conteúdo HTML e extrair pontos de dados relevantes com base em seletores predefinidos.Depois que os dados são extraídos, eles são enviados para um nó
Set
onde são formatados e organizados em uma estrutura mais gerenciável. Este nó permite renomear campos e ajustar o formato dos dados conforme necessário. Os dados processados são então direcionados para umNó de função
, que pode realizar transformações ou cálculos adicionais nos dados, melhorando sua usabilidade.Após a transformação dos dados, eles são enviados para um
Nó do banco de dados
para armazenamento. Este nó é configurado para inserir os dados em um banco de dados especificado, garantindo que as informações extraídas sejam salvas para referência futura. Por fim, o fluxo de trabalho termina com umnó Webhook
, que pode ser usado para notificar outros serviços ou acionar ações adicionais com base na conclusão do processo de extração de dados.Principais recursos
1. Extração automatizada de dados:
o fluxo de trabalho automatiza o processo de extração de dados de diversas fontes, reduzindo o esforço manual e aumentando a eficiência.
2. Programação Personalizável:
Com o nó Cron, os usuários podem personalizar facilmente a frequência de extração de dados, garantindo que as informações mais recentes estejam sempre disponíveis.
3. Análise de dados flexível:
O nó Extração de HTML permite a análise flexível de conteúdo HTML, permitindo que os usuários especifiquem exatamente quais pontos de dados extrair com base em suas necessidades.
4. Recursos de transformação de dados:
A inclusão dos nós Set e Function permite ampla manipulação de dados, garantindo que os dados extraídos estejam no formato desejado antes do armazenamento.
5. Integração com bancos de dados:
O fluxo de trabalho integra-se perfeitamente aos bancos de dados, permitindo fácil armazenamento e recuperação de dados extraídos.
6. Sistema de Notificação:
O nó Webhook fornece um mecanismo para notificar outros serviços ou acionar fluxos de trabalho adicionais, melhorando a funcionalidade geral do sistema.
Integração de ferramentas
O Comprehensive Scraper Workflow integra-se com diversas ferramentas e serviços, utilizando nós específicos dentro do n8n:
- Nó Cron:
Para agendar a execução do fluxo de trabalho.
- Nó de solicitação HTTP:
para buscar dados de URLs externos.
- Nó de extração de HTML:
para analisar conteúdo HTML e extrair pontos de dados específicos.
- Set node:
Para formatar e organizar os dados extraídos.
- Nó de função:
Para realizar transformações de dados adicionais.
- Nó de banco de dados:
Para armazenar os dados extraídos em um banco de dados.
- Nó Webhook:
para enviar notificações ou acionar outros fluxos de trabalho.
Chaves de API necessárias
Este fluxo de trabalho não requer chaves de API ou credenciais de autenticação para funcionar. Todos os nós operam com base em dados acessíveis publicamente ou configurações de banco de dados locais.









