声に出して話す黒曜石の音符
Obsidian ノートをポッドキャスト フィード用のオーディオ形式に変換します。
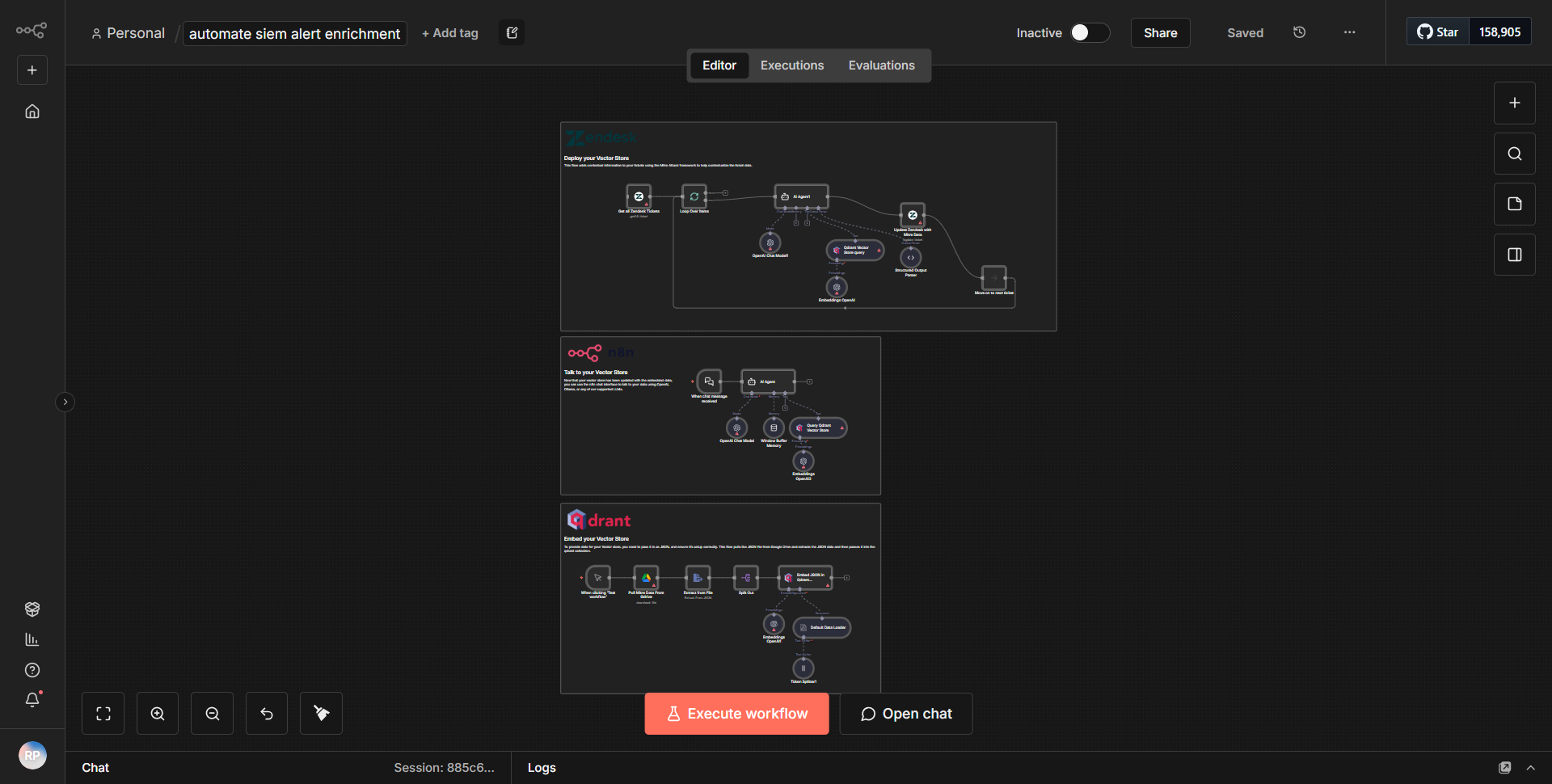
仕組み
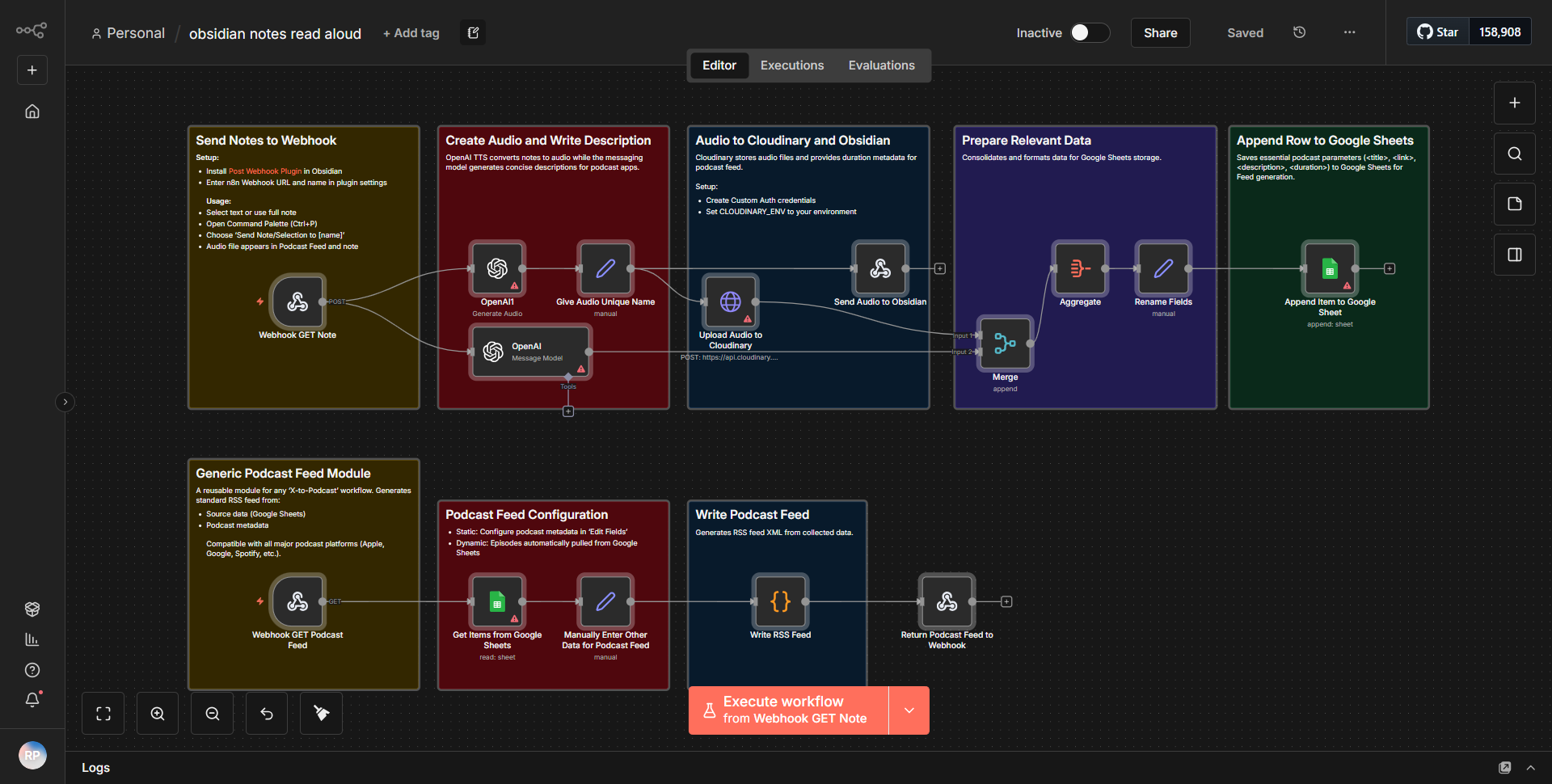
「Obsidian Notes Spoken Aloud」ワークフローは、Obsidian アプリケーションからのメモをポッドキャスト フィードに適した音声形式に変換するように設計されています。ワークフローは、ノートの抽出、処理、オーディオ生成を容易にする、相互接続された一連のノードを通じて動作します。
1. トリガー ノード:
ワークフローは、Obsidian で新しいノートが作成または更新されるときにアクティブ化されるトリガー ノードから始まります。このノードは、メモが保存されている指定されたフォルダーを監視します。
2. ファイル読み取りノード:
トリガーされると、ワークフローは「ファイル読み取り」ノードを利用して、新しく作成または更新されたメモのコンテンツにアクセスします。このノードは、通常はマークダウン形式であるメモ ファイルからテキストを抽出します。
3. Text-to-Speech ノード:
抽出されたテキストは、「Text-to-Speech」ノードに渡されます。このノードは、テキスト コンテンツをオーディオ形式に変換します。ユーザーは、音声の選択や発話速度などのパラメータをカスタマイズして、オーディオ出力を調整できます。
4. ポッドキャスト フィード ノードへのアップロード:
オーディオ ファイルを生成した後、ワークフローには、オーディオ ファイルを指定されたポッドキャスト フィードにアップロードする「アップロード」ノードが含まれます。このノードはポッドキャスト ホスティング サービスとの統合を処理し、オーディオが正しくフォーマットされてアップロードされていることを確認します。
5. 通知ノード:
最後に、ワークフローには、新しい音声ファイルが正常に作成されアップロードされたことをユーザーに通知するアラートを (電子メールまたはメッセージング サービス経由で) 送信する通知ノードが含まれる場合があります。
データはあるノードから次のノードにシームレスに流れ、各ステップが正しい順序で実行されることが保証され、最終的にリスナーが新しいオーディオ ファイルを利用できるようになります。
主な機能
- 自動オーディオ変換:
ワークフローはテキストメモをオーディオファイルに変換するプロセスを自動化し、書いたメモからポッドキャストコンテンツを作成したいユーザーの時間と労力を節約します。
- カスタマイズ可能なテキスト読み上げオプション:
ユーザーはさまざまな音声を選択し、発話速度を調整できるため、さまざまな聴衆の好みに合わせてカスタマイズされたオーディオ体験が可能になります。
- ポッドキャスト フィードとのシームレスな統合:
ワークフローは、生成されたオーディオ ファイルをポッドキャスト フィードに直接アップロードするように設計されており、手動介入なしでコンテンツを簡単に配布できます。
- リアルタイム通知:
ユーザーはオーディオの作成とアップロードが成功すると通知を受け取り、コンテンツ制作のステータスを常に把握できます。
- マークダウン形式のサポート:
ワークフローは、Obsidian で使用される標準形式であるマークダウンで書かれたメモを処理できるため、互換性と使いやすさが保証されます。
ツールの統合
ワークフローは、特定の n8n ノードを介していくつかのツールとサービスを統合します。
- Obsidian:
トリガー ノードは、Obsidian アプリケーションの変更を監視します。
- ファイル システム:
「ファイル読み取り」ノードは、ローカル ファイル システムにアクセスしてメモの内容を読み取ります。
- Text-to-Speech サービス:
「Text-to-Speech」ノードは、TTS サービスを利用してテキストを音声に変換します。
- ポッドキャスト ホスティング サービス:
「アップロード」ノードは、オーディオ ファイル配信のためにポッドキャスト ホスティング プラットフォームに接続します。
- 通知サービス:
ワークフローには、通知を送信するための電子メールまたはメッセージング サービスのノードが含まれる場合があります。
API キーが必要です
ワークフローでは、提供された JSON またはスクリーンショットで、その操作に必要な API キーや認証資格情報が明示的に言及されていません。外部 API 認証を必要とせず、ローカル ファイル アクセスと標準統合に依存しているようです。ただし、使用するプラットフォームによっては、ユーザーは特定のノード、特にポッドキャスト ホスティング サービスの設定を構成する必要がある場合があります。