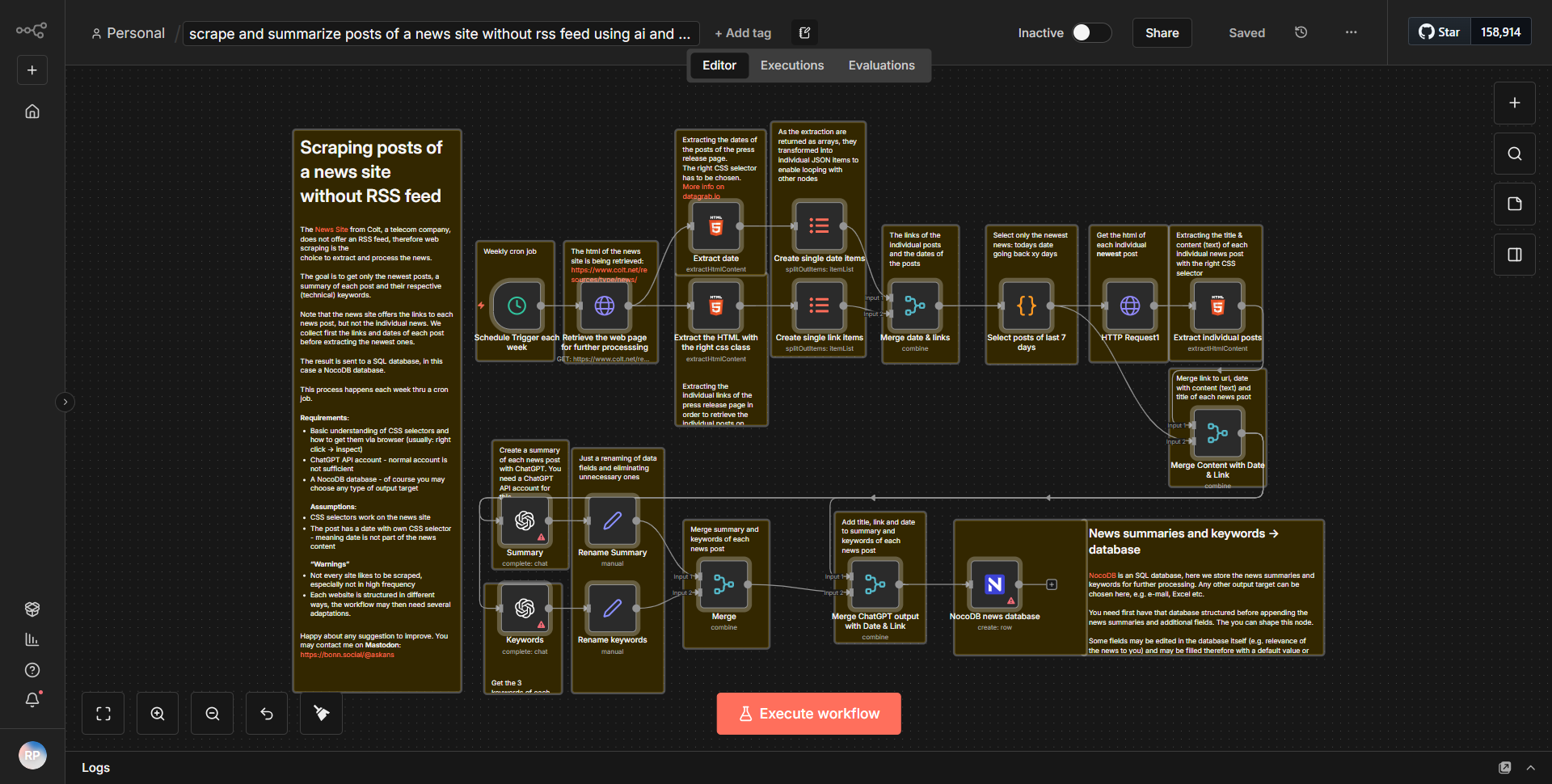
RSSフィードのないニュースサイトからAIを活用して記事を抽出・圧縮し、NocoDBに格納します。
AIを活用してRSSフィードが欠落しているニュース記事を抽出・圧縮し、NocoDBに保存します。
仕組み
ワークフローは、RSS フィードを提供しない指定されたニュース Web サイトの HTML コンテンツを取得するように構成された
HTTP リクエスト
ノードから始まります。このノードは、ターゲット URL に対して GET リクエストを実行し、ページ コンテンツ全体を取得するように設定されています。このノードの出力は生の HTML であり、処理のために次のノードに渡されます。HTTP Request ノードの後には、
HTML Extract
ノードがあります。このノードは、前のステップで取得した HTML コンテンツを解析します。 CSS セレクターを利用して、記事のタイトル、発行日、記事の本文などの特定の要素を HTML から識別して抽出します。抽出されたデータは、より管理しやすい形式 (通常は JSON) で構造化されます。次に、ワークフローには、抽出されたデータをさらに処理する
Function
ノードが含まれています。このノードでは、AI 技術を使用して記事が凝縮されています。これには、特定の実装に応じて、コンテンツの要約や重要なポイントの抽出が含まれる場合があります。このノードの出力は記事の要約バージョンであり、すぐに保存できます。ワークフローの最後のステップは
NocoDB
ノードです。これは、要約された記事を NocoDB データベースに保存するために使用されます。このノードは、指定されたテーブルに新しいレコードを作成するように構成されており、各レコードは要約記事に対応します。 NocoDB に送信されるデータには、タイトル、概要、および以前に抽出されたその他の関連メタデータが含まれます。ワークフロー全体を通じて、データは 1 つのノードから次のノードへ順番に流れ、生の HTML を構造化された要約されたコンテンツに変換し、簡単にアクセスして管理できるようにデータベースに保存されます。
主な機能
1. AI を活用した要約:
このワークフローでは AI 技術を活用して、長い記事を簡潔な要約に凝縮し、ユーザーが重要な情報を素早く把握しやすくします。
2. HTML コンテンツの抽出:
RSS フィードのない Web サイトから HTML コンテンツを直接スクレイピングすることで、ワークフローは、他の方法ではアクセスできないさまざまなソースからニュース記事を収集できます。
3. NocoDB との統合:
要約された記事を NocoDB に保存できるため、整理されたデータ管理と簡単な検索が可能になり、さらなる分析やレポート作成が容易になります。
4. カスタマイズ可能なデータ抽出:
HTML 抽出ノードで CSS セレクターを使用すると、ユーザーは記事のどの要素を抽出するかをカスタマイズできるため、さまざまな Web サイト構造に基づいた柔軟性が得られます。
5. 自動化されたワークフロー:
プロセス全体が自動化され、手動によるデータ収集と要約の必要性が減り、ユーザーの時間と労力が節約されます。
ツールの統合
- HTTP リクエスト ノード:
指定されたニュース Web サイトから HTML コンテンツを取得するために使用されます。
- HTML 抽出ノード:
HTML を解析し、CSS セレクターを使用して関連する記事データを抽出します。
- 関数ノード:
抽出したデータを処理し、AIを活用して集計を行います。
- NocoDB ノード:
構造化データ管理のために、要約された記事を NocoDB データベースに保存します。
API キーが必要です
このワークフローが機能するには、API キーや認証資格情報は必要ありません。使用されるノードは外部 API アクセスを必要とせずに動作し、ニュース Web サイトへの HTTP リクエストとデータ ストレージ用の NocoDB との統合のみに依存します。









