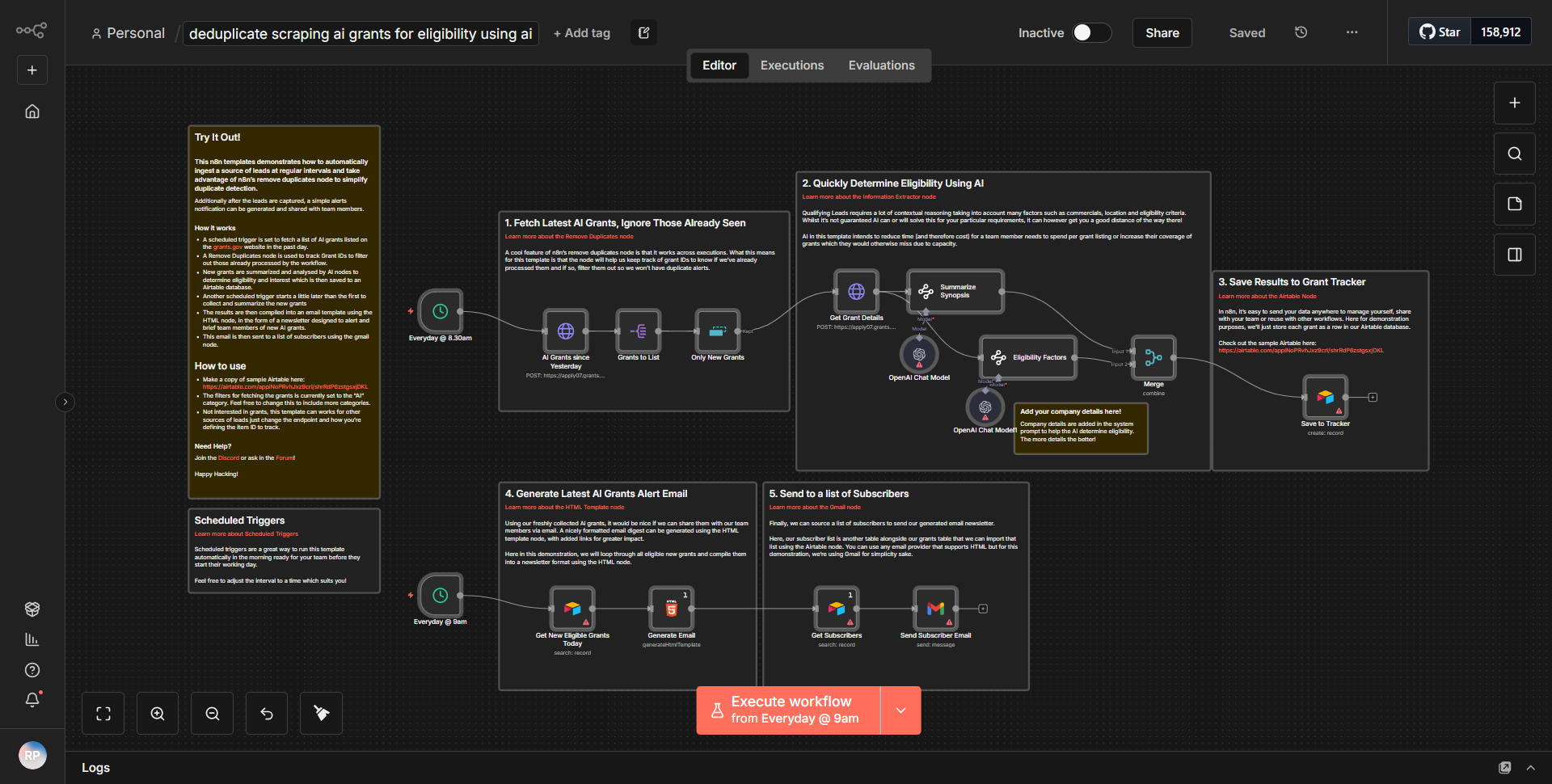
Qdrant、Python、Data Extractor を使用した顧客分析
Qdrant、Python、データ抽出モジュールを使用して顧客の洞察を収集します。
仕組み
「Qdrant、Python、Data Extractor を活用した顧客分析」というタイトルのワークフローは、ベクトル データベースである Qdrant の機能と、データ処理用の Python およびデータ抽出モジュールを活用して、顧客に関する洞察を収集するように設計されています。ワークフローは、おそらく特定のイベントまたはスケジュールに基づいてプロセスを開始するトリガー ノードから始まります。
1. データ抽出:
ワークフローは、指定されたソースから顧客データを取得するデータ抽出ノードから始まります。これには、データベースまたは API に接続して、関連する顧客情報を取得することが含まれる場合があります。
2. Python によるデータ処理:
データが抽出されると、Python ノードに渡されます。ここでは、カスタム Python スクリプトが実行されて、データがさらに処理されます。これには、データのクリーニング、変換、または分析用のデータを準備するために必要な分析計算が含まれる場合があります。
3. Qdrant との統合:
処理後、ワークフローは準備されたデータを Qdrant ノードに送信します。 Qdrant は、顧客データのベクトル表現を保存および管理するために利用され、効率的な類似性検索とベクトル埋め込みに基づく洞察の取得を可能にします。
4. 洞察の生成:
ワークフローには、保存されたデータに基づいて洞察を生成するために Qdrant にクエリを実行する追加のノードが含まれる場合があります。これには、顧客間のパターンや傾向を特定するための類似性検索の実行が含まれる場合があります。
5. 出力とレポート:
最後に、ワークフローは、洞察をレポートにフォーマットするか、利害関係者に通知したり、結果をデータベースに保存したりするなどのさらなるアクションのために洞察を別のサービスに送信する出力ノードで終了します。
このプロセス全体を通じて、ノードは相互接続され、抽出から洞察生成までのシームレスなデータ フローを確保し、顧客データの包括的な分析を可能にします。
主な機能
- データ抽出:
ワークフローはさまざまなソースから顧客データを取得し、最も関連性の高い最新の情報に基づいて分析を行うことができます。
- カスタム Python 処理:
Python ノードの統合により、高度なデータ操作と分析が可能になり、ユーザーは特定のニーズに合わせたカスタム ロジックを実装できます。
- ベクター データベースの利用:
Qdrant を使用すると、ワークフローで高次元データの効率的な保存と取得が可能になり、類似性検索による迅速な洞察が容易になります。
- 洞察の生成:
顧客データから実用的な洞察を生成する機能は、企業が顧客の行動や好みを理解し、より適切な意思決定を促進するのに役立ちます。
- 自動レポート:
ワークフローは自動的にフォーマットして洞察を提供できるため、手作業が軽減され、重要な情報にタイムリーにアクセスできるようになります。
ツールの統合
- データ抽出ノード:
このノードは、さまざまなソースから顧客データを取得する役割を果たします。
- Python ノード:
抽出されたデータを処理するカスタム スクリプトを実行するために使用されます。
- Qdrant ノード:
顧客データの保存とクエリのために Qdrant ベクトル データベースと統合します。
- 出力ノード:
分析から生成された洞察をフォーマットして提供します。
API キーが必要です
ワークフローでは、操作に必要な API キーや認証資格情報は指定されていません。ただし、データ抽出に外部 API またはデータベースへのアクセスが含まれる場合は、適切な資格情報が必要になる場合があり、これをそれぞれのノードで構成する必要があります。