自立型AIウェブクローラー
データを収集して分析するための自立型 AI 駆動の Web スクレイパーです。
仕組み
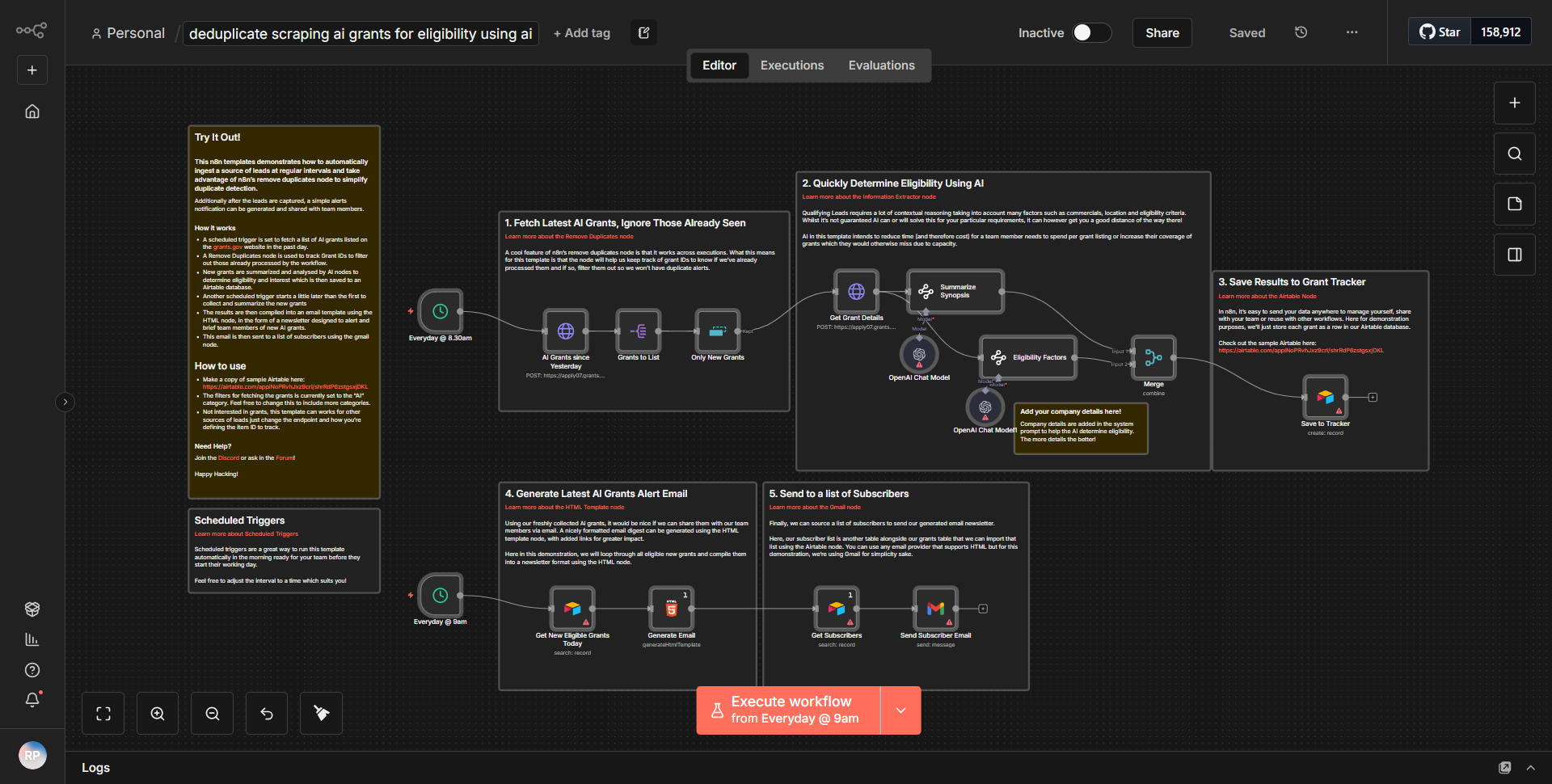
「自立型 AI Web クローラー」ワークフローは、インターネットからデータを収集して分析するように設計された自律型 Web スクレイパーとして動作します。ワークフローは、定義されたスケジュールまたはイベントに基づいてスクレイピング プロセスを開始するトリガー ノードから始まります。ワークフローがトリガーされると、さまざまなノードを介した体系的なデータ フローに従います。
1. ノードの開始:
ワークフローは、構成に応じて、スケジュールに従って、または Webhook 経由で開始されます。
2. HTTP リクエスト ノード:
このノードは、ターゲット Web サイトにリクエストを送信する役割を果たします。指定された URL の HTML コンテンツを取得します。
3. HTML 抽出ノード:
HTML コンテンツを取得した後、このノードはデータを解析し、事前定義されたセレクターに基づいてタイトル、リンク、特定のテキスト要素などの関連情報を抽出します。
4. 関数ノード:
このノードは、抽出されたデータをさらに処理し、必要な変換や計算を適用します。使いやすさを向上させるためにデータをフィルタリングまたはフォーマットするロジックが含まれる場合もあります。
5. データ ストレージ ノード:
処理されたデータは、将来の参照や分析のためにデータベースまたはクラウド サービスに保存されます。これには、Google スプレッドシート、Airtable、カスタム データベース統合などのノードが関係する可能性があります。
6. 通知ノード:
最後に、ワークフローには、スクレイピング タスクの完了または重要な結果についてユーザーに警告する通知システムが含まれる場合があります。これは、電子メール、Slack、または別のメッセージング サービスを通じて行うことができます。
ノードは直線的に相互接続されているため、データが 1 つのステップから次のステップにシームレスに流れることが保証され、効率的なデータの収集と処理が可能になります。
主な機能
- 自律操作:
ワークフローは手動介入なしで実行されるように設計されており、継続的なデータ収集に適しています。
- データ抽出:
カスタマイズ可能なセレクターを使用して Web ページから特定のデータ ポイントを抽出できるため、ユーザーはスクレイピング プロセスをニーズに合わせて調整できます。
- データ処理:
抽出されたデータを処理および変換して、分析に使用可能な形式にする機能が含まれています。
- ストレージ統合:
さまざまなストレージ ソリューションをサポートし、ユーザーが好みの形式と場所にデータを保存して、簡単にアクセスして分析できるようにします。
- 通知システム:
タスクの完了時、または特定の条件が満たされたときにアラートと通知を提供し、ユーザーにワークフローのステータスを知らせます。
ツールの統合
ワークフローは、機能を強化するためにいくつかのツールやサービスと統合されています。
- HTTP リクエスト ノード:
ターゲット Web サイトからデータを取得するために使用されます。
- HTML 抽出ノード:
HTML コンテンツを解析して関連データを抽出します。
- 関数ノード:
カスタム データの処理と変換を実行します。
- データベース ノード:
データ ストレージのために Google Sheets や Airtable などのサービスと統合します。
- 通知ノード:
電子メールまたは Slack などのメッセージング プラットフォーム経由でアラートを送信します。
API キーが必要です
このワークフローの基本機能には、API キーや認証資格情報は必要ありません。ただし、ワークフローが特定のサービス (Google Sheets や Airtable など) と統合されている場合、ユーザーはデータの保存と取得を可能にするために、それらのサービスに必要な API キーまたは認証トークンを提供する必要があります。