リストに戻る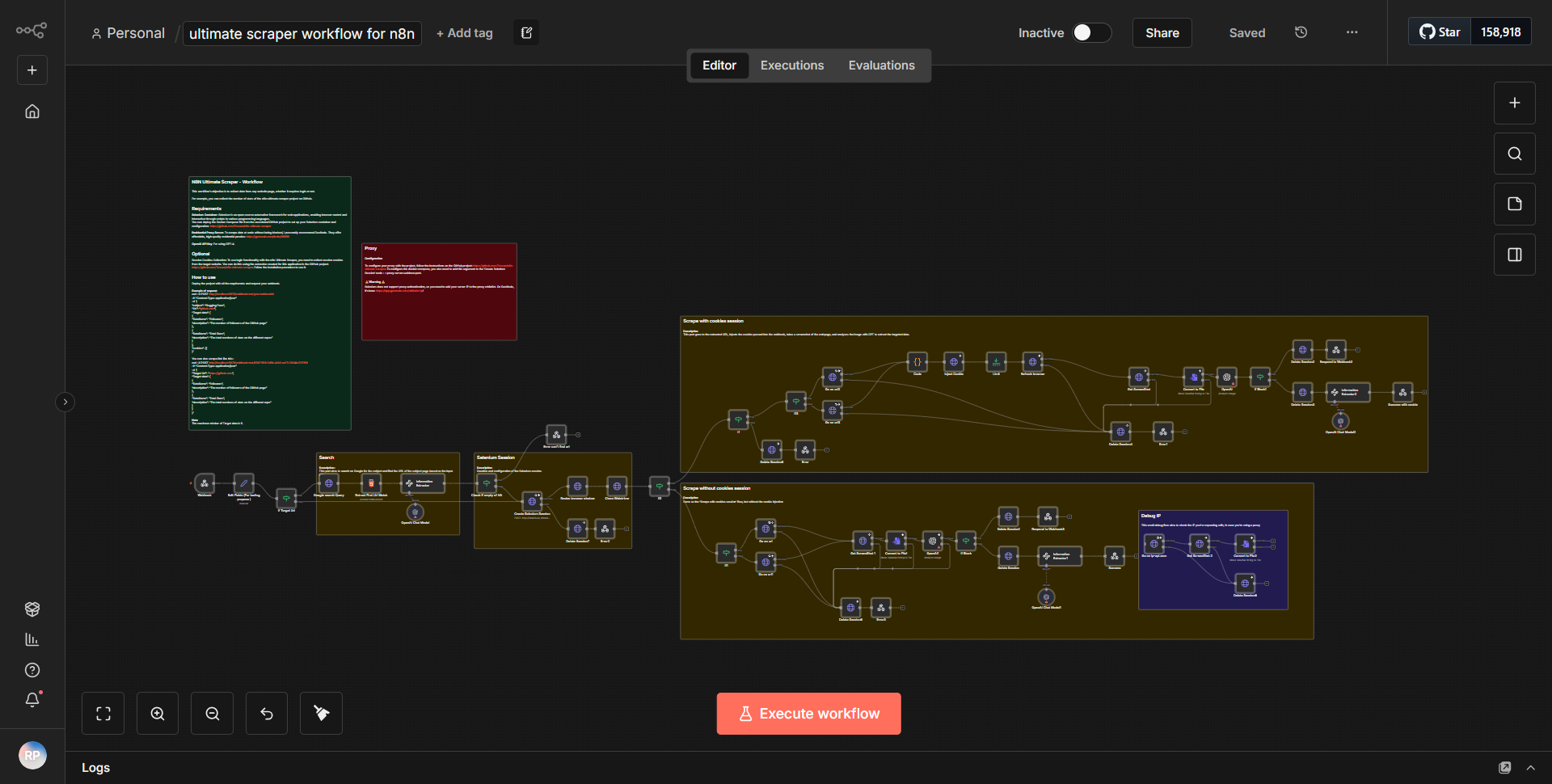
n8n の包括的なスクレイパー ワークフローは、構造化された方法で複数のソースからデータを抽出するように設計されています。ワークフローは
Cron ノードに続いて、ワークフローは
データが抽出されると、
データが変換された後、保存するために
n8n 向けの包括的なスクレーパー ワークフロー
Data Collection, Automation
複数のソースから情報を収集するように設計された n8n 用の広範なデータ抽出ワークフロー。
仕組み
n8n の包括的なスクレイパー ワークフローは、構造化された方法で複数のソースからデータを抽出するように設計されています。ワークフローは
Cron ノード
で始まり、指定された間隔でプロセスをトリガーします。このノードはワークフローを毎日実行するように構成されており、データが定期的に収集されるようになります。Cron ノードに続いて、ワークフローは
HTTP リクエスト ノード
を利用して、指定された URL からデータをフェッチします。このノードは GET リクエストを実行するように構成されており、ターゲット Web ページの HTML コンテンツを取得できるようになります。このノードからの出力は、HTML Extract ノード
に渡されます。このノードは、HTML コンテンツを解析し、事前定義されたセレクターに基づいて関連するデータ ポイントを抽出します。データが抽出されると、
Set ノード
に送信され、そこでフォーマットされ、より管理しやすい構造に編成されます。このノードでは、必要に応じてフィールドの名前を変更したり、データ形式を調整したりできます。処理されたデータは関数ノード
に送られ、データに対して追加の変換や計算を実行できるため、使いやすさが向上します。データが変換された後、保存するために
データベース ノード
に送信されます。このノードは、指定されたデータベースにデータを挿入するように構成されており、抽出された情報が将来の参照のために確実に保存されます。最後に、ワークフローはWebhook ノード
で終了します。これを使用して、他のサービスに通知したり、データ抽出プロセスの完了に基づいて追加のアクションをトリガーしたりできます。主な機能
1. 自動データ抽出:
ワークフローにより、複数のソースからのデータ抽出プロセスが自動化され、手作業が軽減され、効率が向上します。
2. カスタマイズ可能なスケジュール:
Cron ノードを使用すると、ユーザーはデータ抽出の頻度を簡単にカスタマイズでき、常に最新の情報を利用できるようになります。
3. 柔軟なデータ解析:
HTML Extract ノードは HTML コンテンツの柔軟な解析を可能にし、ユーザーがニーズに基づいて抽出するデータ ポイントを正確に指定できるようにします。
4. データ変換機能:
Set ノードと Function ノードを含めることで、広範なデータ操作が可能になり、抽出されたデータが保存前に目的の形式であることが保証されます。
5. データベースとの統合:
ワークフローはデータベースとシームレスに統合され、抽出されたデータの保存と取得が容易になります。
6. 通知システム:
Webhook ノードは、他のサービスに通知したり、追加のワークフローをトリガーしたりするためのメカニズムを提供し、システム全体の機能を強化します。
ツールの統合
包括的なスクレイパー ワークフローは、n8n 内の特定のノードを利用して、いくつかのツールおよびサービスと統合します。
- Cron ノード:
ワークフローの実行をスケジュールするため。
- HTTP リクエスト ノード:
外部 URL からデータを取得します。
- HTML 抽出ノード:
HTML コンテンツを解析し、特定のデータ ポイントを抽出します。
- セットノード:
抽出されたデータをフォーマットおよび整理します。
- 関数ノード:
追加のデータ変換を実行するため。
- データベースノード:
抽出したデータをデータベースに保存します。
- Webhook ノード:
通知の送信または他のワークフローのトリガー用。
API キーが必要です
このワークフローが機能するために API キーや認証資格情報は必要ありません。すべてのノードは、公的にアクセス可能なデータまたはローカル データベース構成に基づいて動作します。









