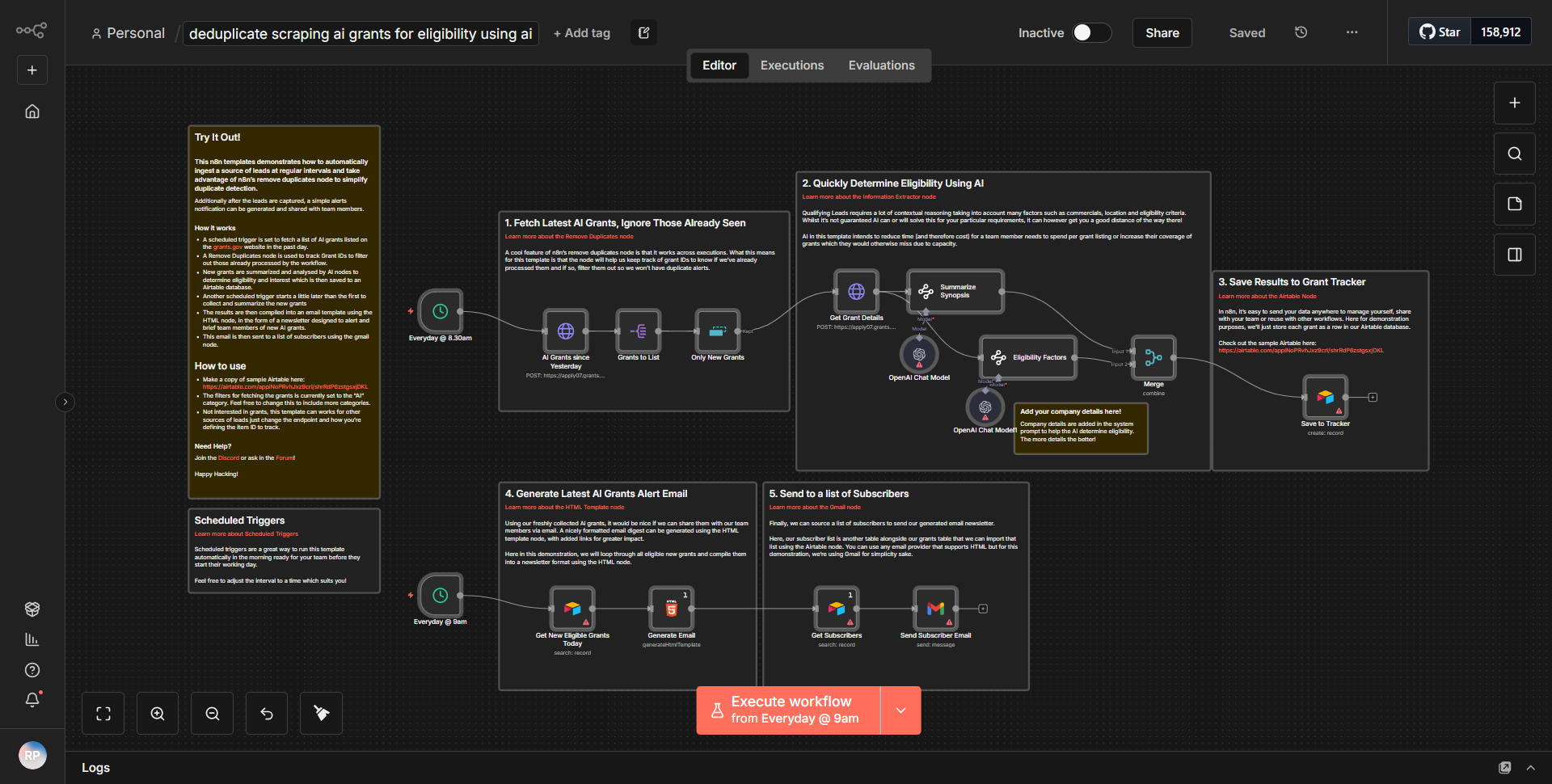
Autarker KI-Webcrawler
Ein autarker, KI-gesteuerter Web Scraper zum Sammeln und Analysieren von Daten.
Wie es funktioniert
Der Workflow „Autarker KI-Webcrawler“ fungiert als autonomer Web-Scraper, der Daten aus dem Internet sammelt und analysiert. Der Workflow beginnt mit einem Triggerknoten, der den Scraping-Prozess basierend auf einem definierten Zeitplan oder Ereignis initiiert. Nach dem Auslösen folgt der Workflow einem systematischen Datenfluss durch verschiedene Knoten.
1. Startknoten:
Der Workflow wird je nach Konfiguration entweder nach einem Zeitplan oder über einen Webhook initiiert.
2. HTTP-Anfrageknoten:
Dieser Knoten ist für das Senden einer Anfrage an die Zielwebsite verantwortlich. Es ruft den HTML-Inhalt der angegebenen URL ab.
3. HTML-Extraktknoten:
Nach Erhalt des HTML-Inhalts analysiert dieser Knoten die Daten, um relevante Informationen wie Titel, Links oder bestimmte Textelemente basierend auf vordefinierten Selektoren zu extrahieren.
4. Funktionsknoten:
Dieser Knoten verarbeitet die extrahierten Daten weiter und wendet alle erforderlichen Transformationen oder Berechnungen an. Es kann auch Logik zum Filtern oder Formatieren der Daten für eine bessere Benutzerfreundlichkeit umfassen.
5. Datenspeicherknoten:
Die verarbeiteten Daten werden dann zur späteren Bezugnahme und Analyse in einer Datenbank oder einem Cloud-Dienst gespeichert. Dies kann Knoten wie Google Sheets, Airtable oder eine benutzerdefinierte Datenbankintegration umfassen.
6. Benachrichtigungsknoten:
Schließlich kann der Workflow ein Benachrichtigungssystem umfassen, das den Benutzer über den Abschluss der Scraping-Aufgabe oder wichtige Ergebnisse informiert. Dies kann per E-Mail, Slack oder einem anderen Messaging-Dienst erfolgen.
Die Knoten sind linear miteinander verbunden und stellen so einen nahtlosen Datenfluss von einem Schritt zum nächsten sicher, was eine effiziente Datenerfassung und -verarbeitung ermöglicht.
Hauptmerkmale
- Autonomer Betrieb:
Der Workflow ist so konzipiert, dass er ohne manuelle Eingriffe ausgeführt werden kann, sodass er für die kontinuierliche Datenerfassung geeignet ist.
- Datenextraktion:
Kann mithilfe anpassbarer Selektoren bestimmte Datenpunkte aus Webseiten extrahieren, sodass Benutzer den Scraping-Prozess an ihre Bedürfnisse anpassen können.
- Datenverarbeitung:
Enthält Funktionen zum Verarbeiten und Umwandeln der extrahierten Daten, um sicherzustellen, dass sie in einem für die Analyse verwendbaren Format vorliegen.
- Speicherintegration:
Unterstützt verschiedene Speicherlösungen, sodass Benutzer ihre Daten in bevorzugten Formaten und an bevorzugten Orten speichern können, um einen einfachen Zugriff und eine einfache Analyse zu ermöglichen.
- Benachrichtigungssystem:
Bietet Warnungen und Benachrichtigungen bei Abschluss von Aufgaben oder wenn bestimmte Bedingungen erfüllt sind, um Benutzer über den Status des Workflows auf dem Laufenden zu halten.
Tools-Integration
Der Workflow lässt sich in mehrere Tools und Dienste integrieren, um seine Funktionalität zu verbessern:
- HTTP-Anforderungsknoten:
Wird zum Abrufen von Daten von Zielwebsites verwendet.
- HTML-Extraktknoten:
Analysiert HTML-Inhalte, um relevante Daten zu extrahieren.
- Funktionsknoten:
Führt benutzerdefinierte Datenverarbeitung und -transformationen durch.
- Datenbankknoten:
Lässt sich zur Datenspeicherung in Dienste wie Google Sheets oder Airtable integrieren.
- Benachrichtigungsknoten:
Sendet Benachrichtigungen per E-Mail oder Messaging-Plattformen wie Slack.
API-Schlüssel erforderlich
Für die Grundfunktionalität dieses Workflows sind keine API-Schlüssel oder Authentifizierungsdaten erforderlich. Wenn der Workflow jedoch in bestimmte Dienste (wie Google Sheets oder Airtable) integriert ist, müssen Benutzer die erforderlichen API-Schlüssel oder Authentifizierungstokens für diese Dienste bereitstellen, um das Speichern und Abrufen von Daten zu ermöglichen.