使用 AI 评估 Hugging Face 中的文档并将其保存在 Notion 中。
自动检索和检查 Hugging Face 中的文档,利用 AI 提取必要的细节,并将结构化信息组织到 Notion 数据库中。
它是如何运作的
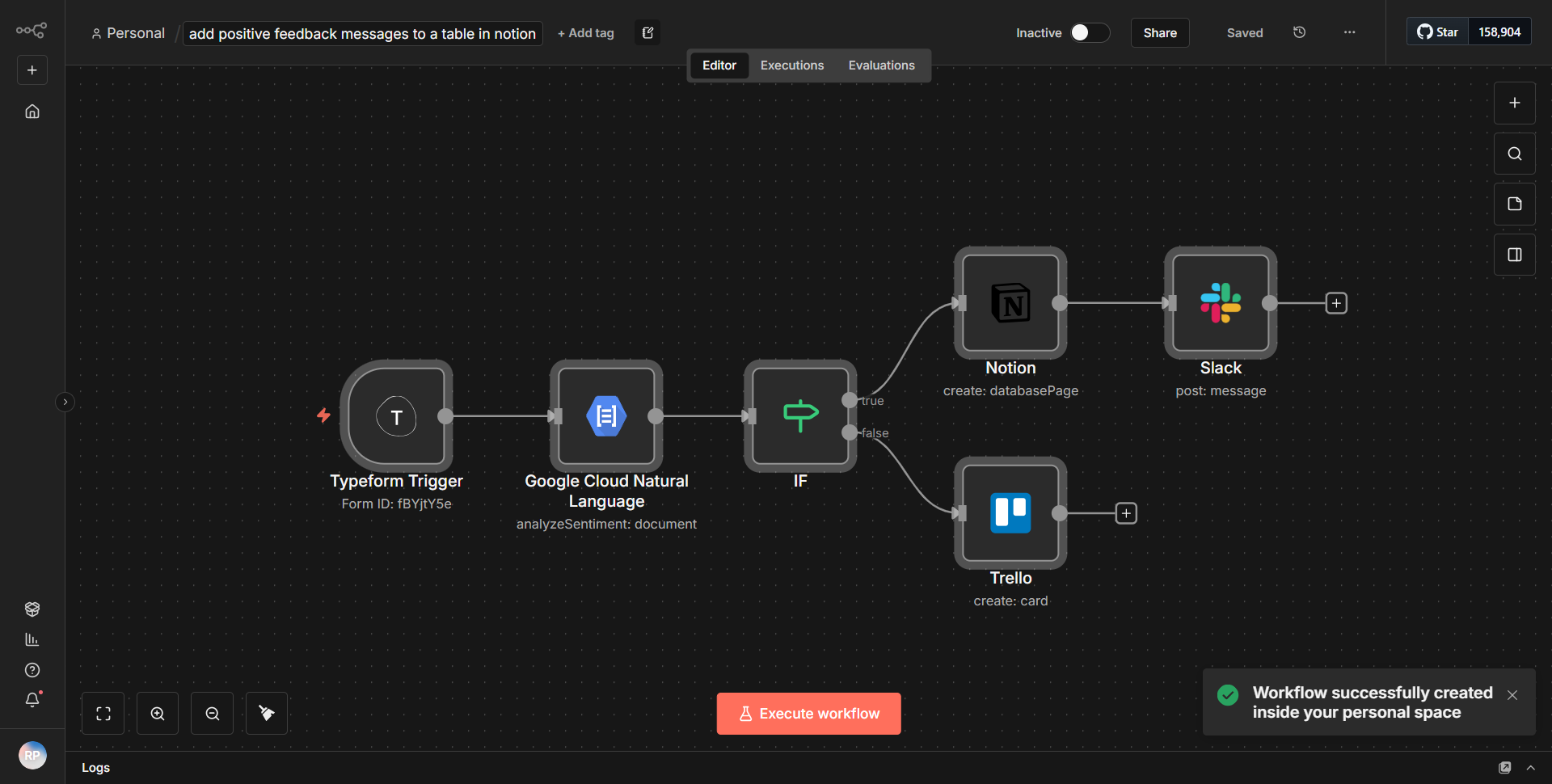
标题为“使用 AI 评估 Hugging Face 文档并将其保存在 Notion 中”的工作流程可自动执行检索、分析和存储文档的过程。它从一个触发器节点开始,该节点根据指定的计划或事件启动工作流。第一个节点是“HTTP 请求”节点,用于从 Hugging Face API 获取文档。该节点配置为向相关端点发送 GET 请求,以 JSON 格式检索必要的数据。
检索文档后,工作流程将利用“函数”节点来处理数据。该节点使用 JavaScript 代码从文档中提取重要的详细信息,例如标题、摘要和主要发现。然后将处理后的数据结构化为适合存储的格式。
数据提取后,工作流程使用“Notion”节点来创建或更新 Notion 数据库中的条目。该节点配置为将上一步提取的信息映射到概念数据库中的适当字段,确保有效捕获和组织所有相关细节。
最后一步涉及“设置”节点,用于格式化输出并为任何进一步的操作或记录准备数据。成功将信息存储在 Notion 中后,工作流程结束,完成文档评估和数据组织的周期。
主要特点
1. 自动文档检索
:工作流程自动从 Hugging Face 获取文档,无需手动下载,并确保始终分析最新研究。
2. 人工智能分析
:利用人工智能功能,工作流程从文档中提取关键信息,为用户提供总结性见解,而无需阅读整个文本。
3. 无缝Notion集成
:结构化数据直接存储在Notion数据库中,允许用户在熟悉的环境中轻松访问和管理他们的研究成果。
4. 可定制的数据处理
:使用功能节点可以定制数据提取过程,使其适应不同类型的文档或特定的用户需求。
5. 定时执行
:可以将工作流程设置为定期运行,确保用户不断收到更新的信息,无需人工干预。
工具集成
该工作流程集成了以下工具和服务:
1. Hugging Face API
:用于检索文档,允许访问各种研究论文和数据集。
• 节点:HTTP 请求
2. 概念
:用于以结构化数据库格式存储和组织提取的信息。
• 节点:概念
3. 功能节点
:用于处理和提取文档中的相关数据,实现定制化分析。
• 节点:函数
4. 设置节点
:用于格式化输出数据并为最终存储步骤做好准备。
• 节点:设置
需要 API 密钥
要成功操作此工作流程,需要以下 API 密钥和凭据:
1. Hugging Face API 密钥
:验证 Hugging Face API 检索文档的请求所必需的。
2. Notion 集成令牌
:需要进行身份验证并允许工作流程在 Notion 数据库中创建或更新条目。
除了为 Hugging Face 和 Notion 指定的密钥或凭据之外,不需要其他 API 密钥或凭据。