🤖 Text_Audio_Images 用の電報通信ボット
AI を利用して Telegram の会話内のテキスト、音声、画像を処理して応答を生成するマルチモーダル エージェント。
仕組み
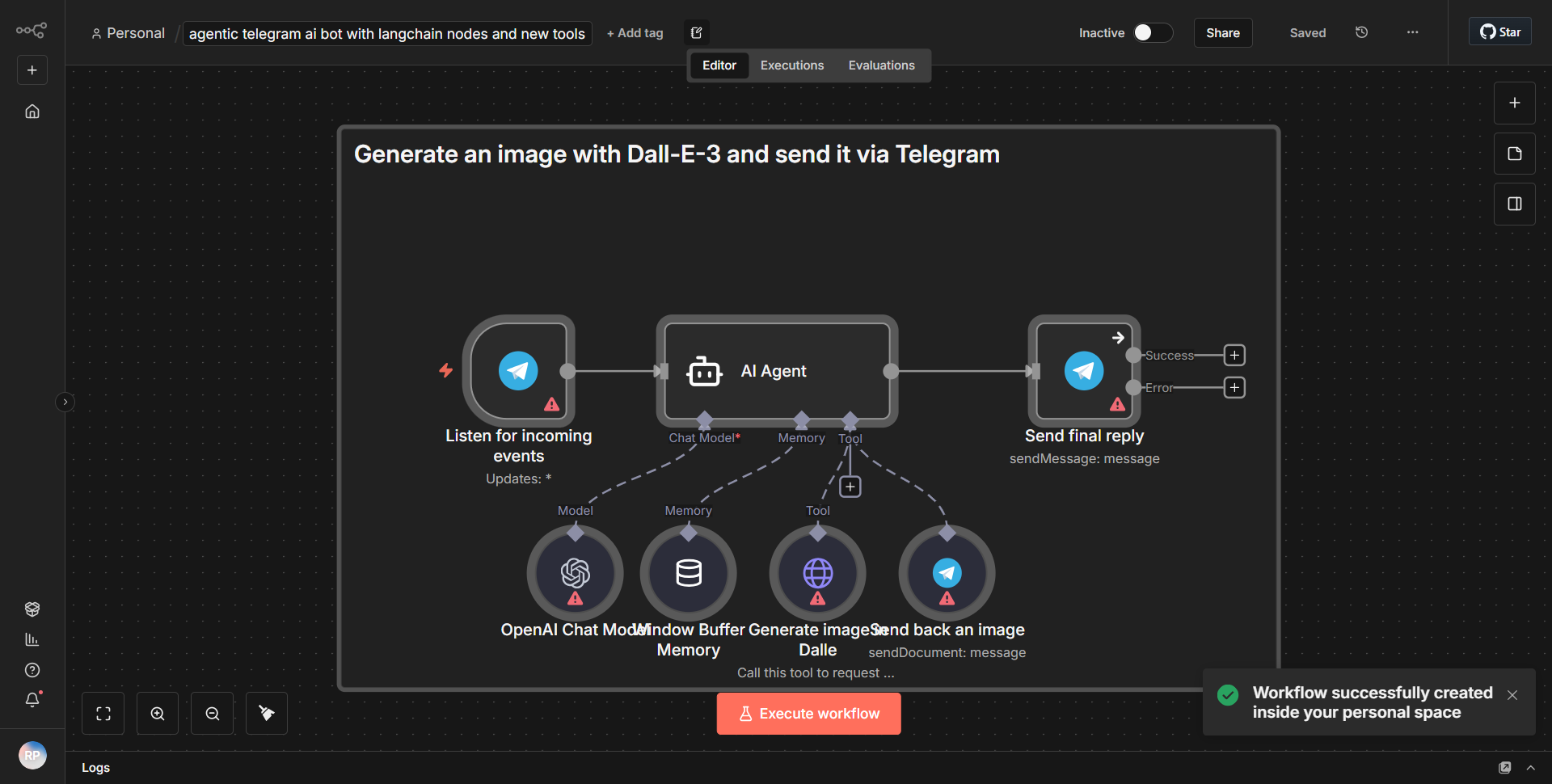
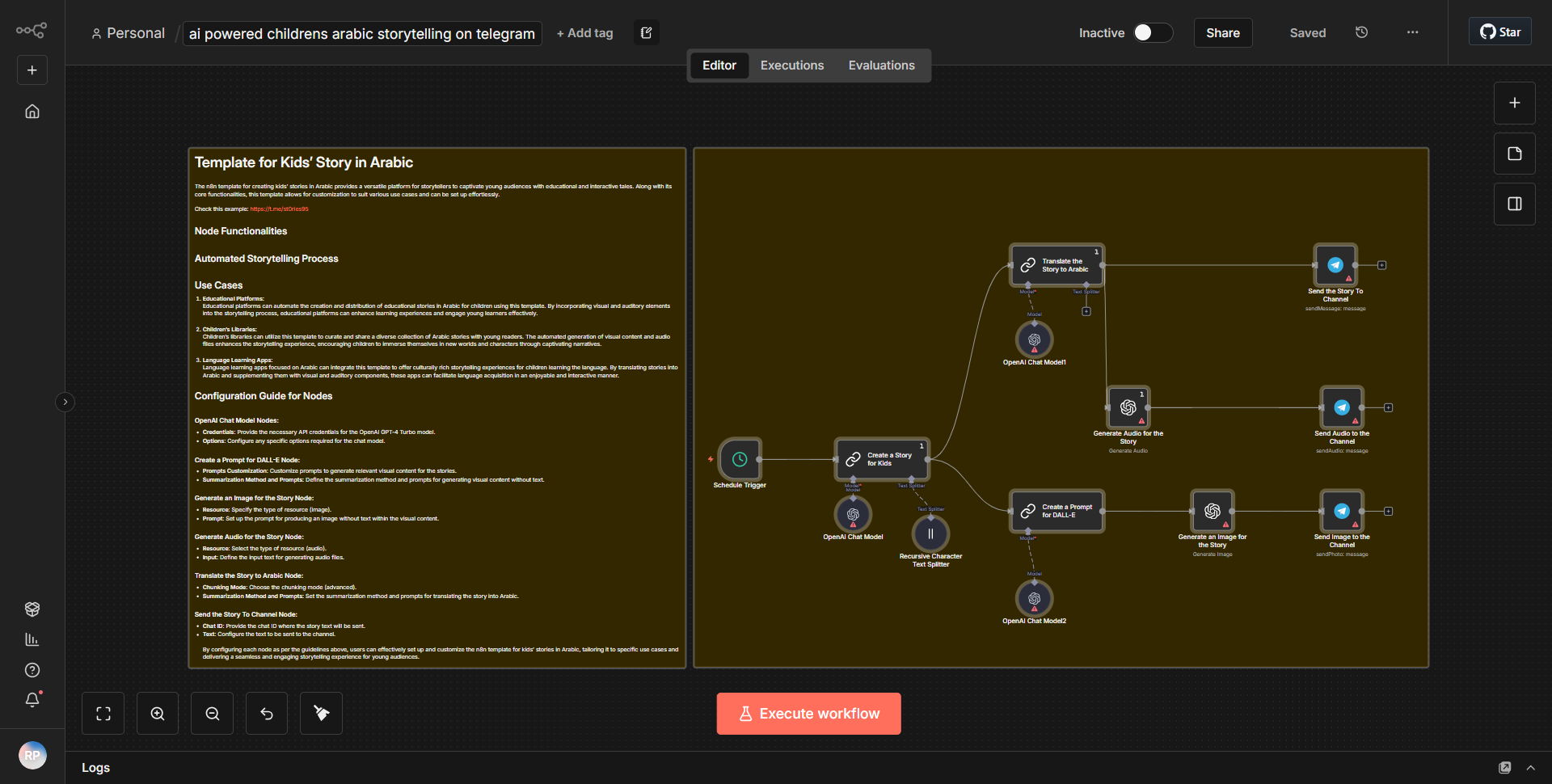
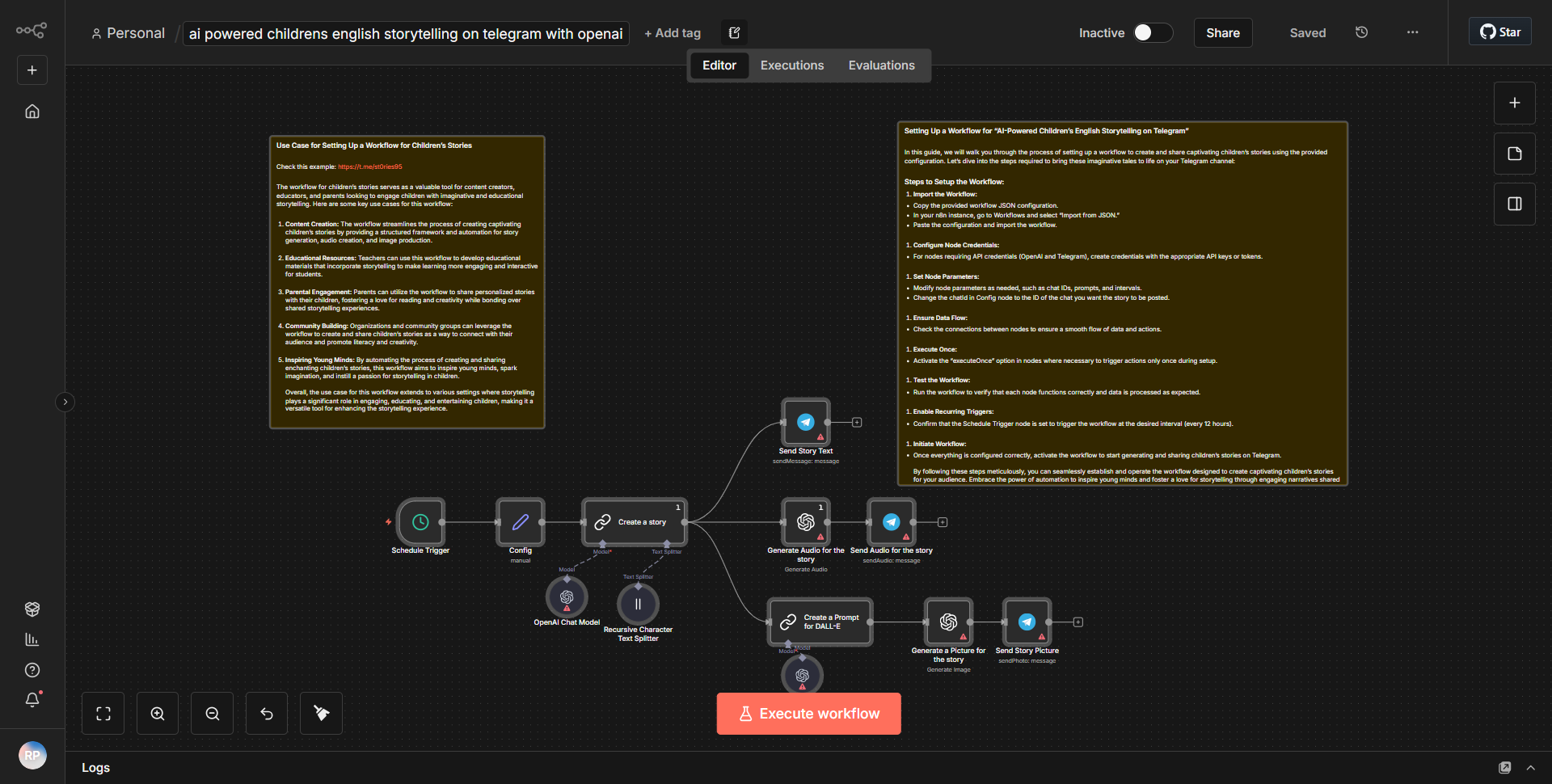
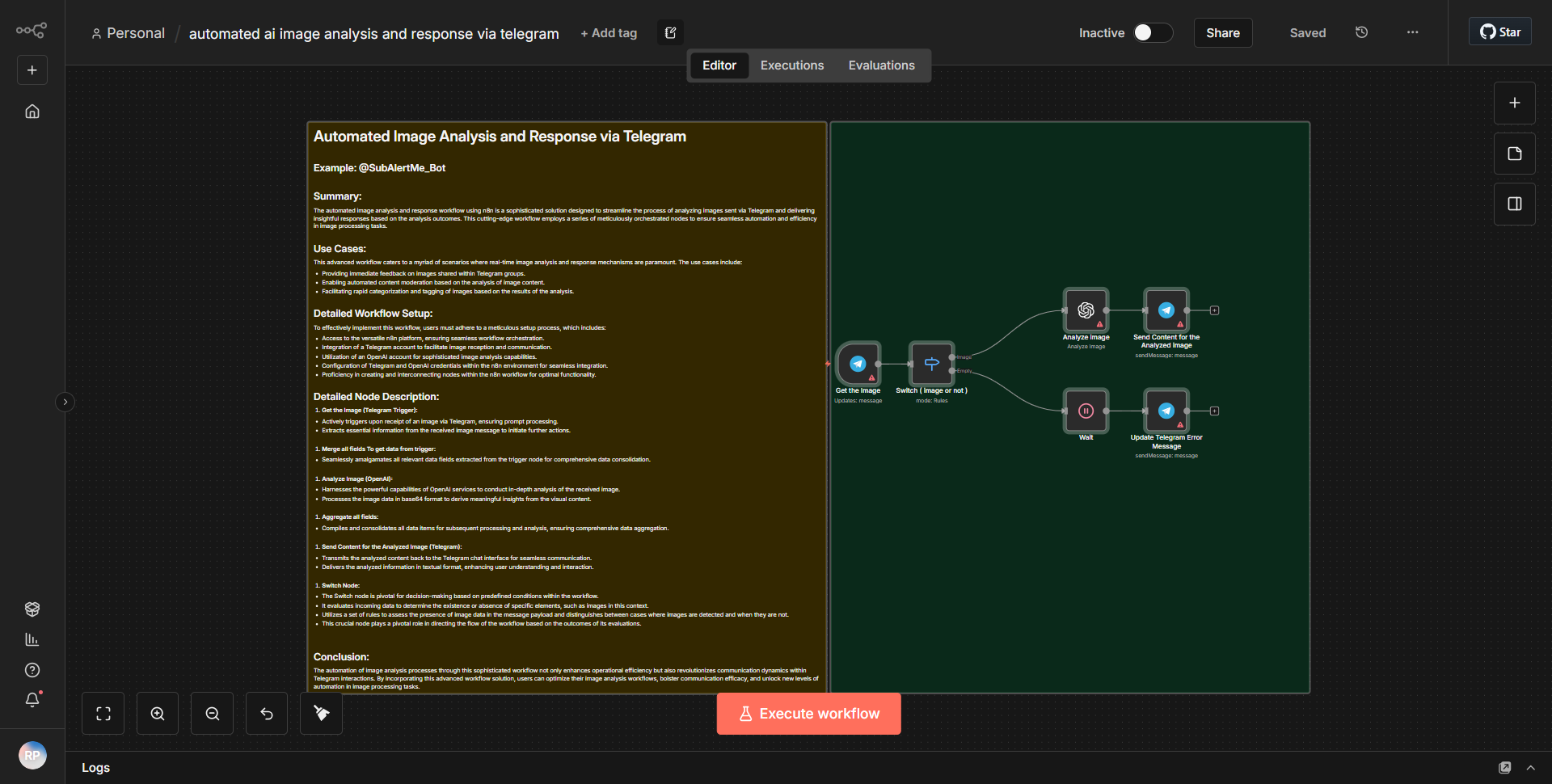
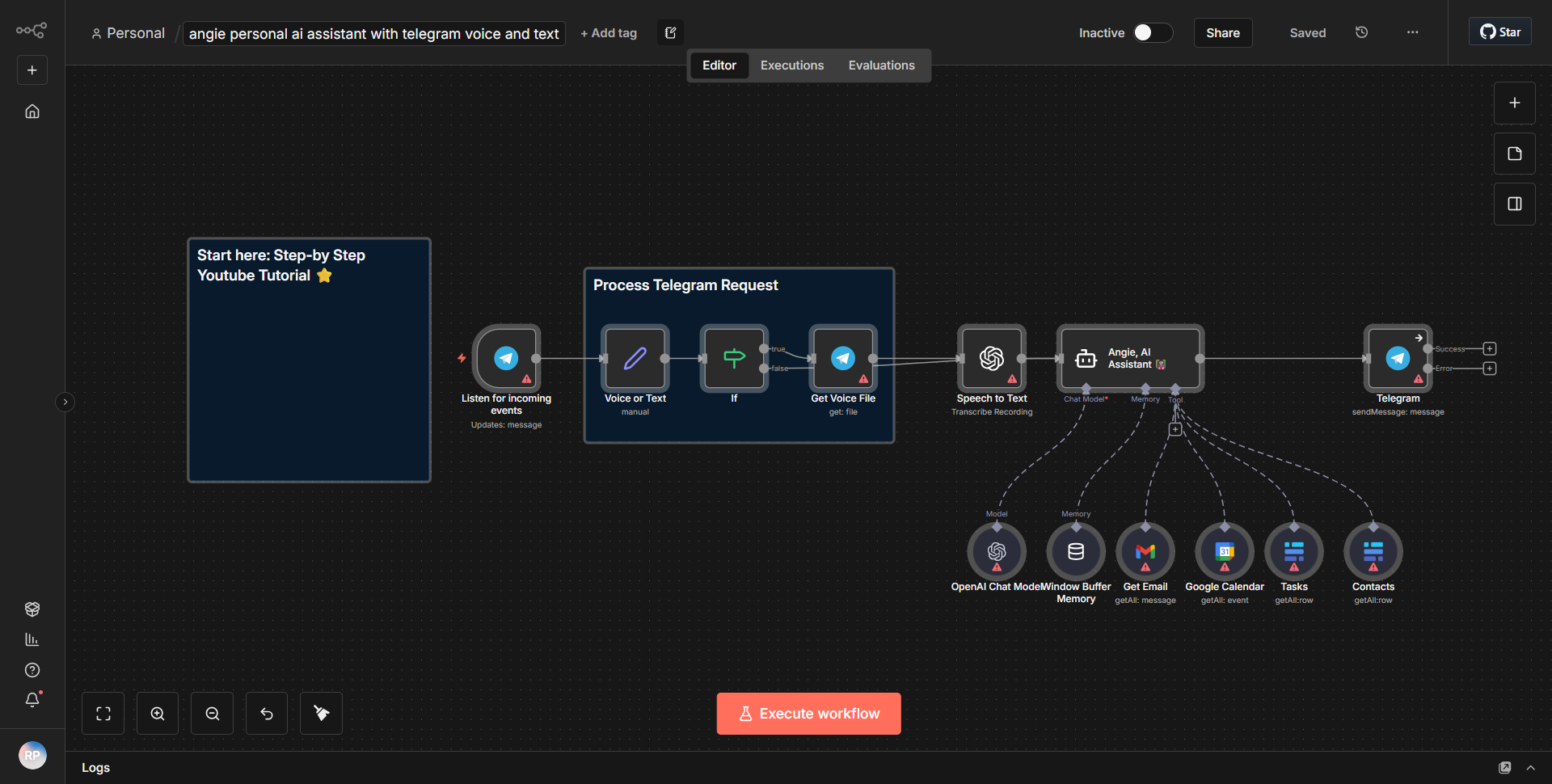
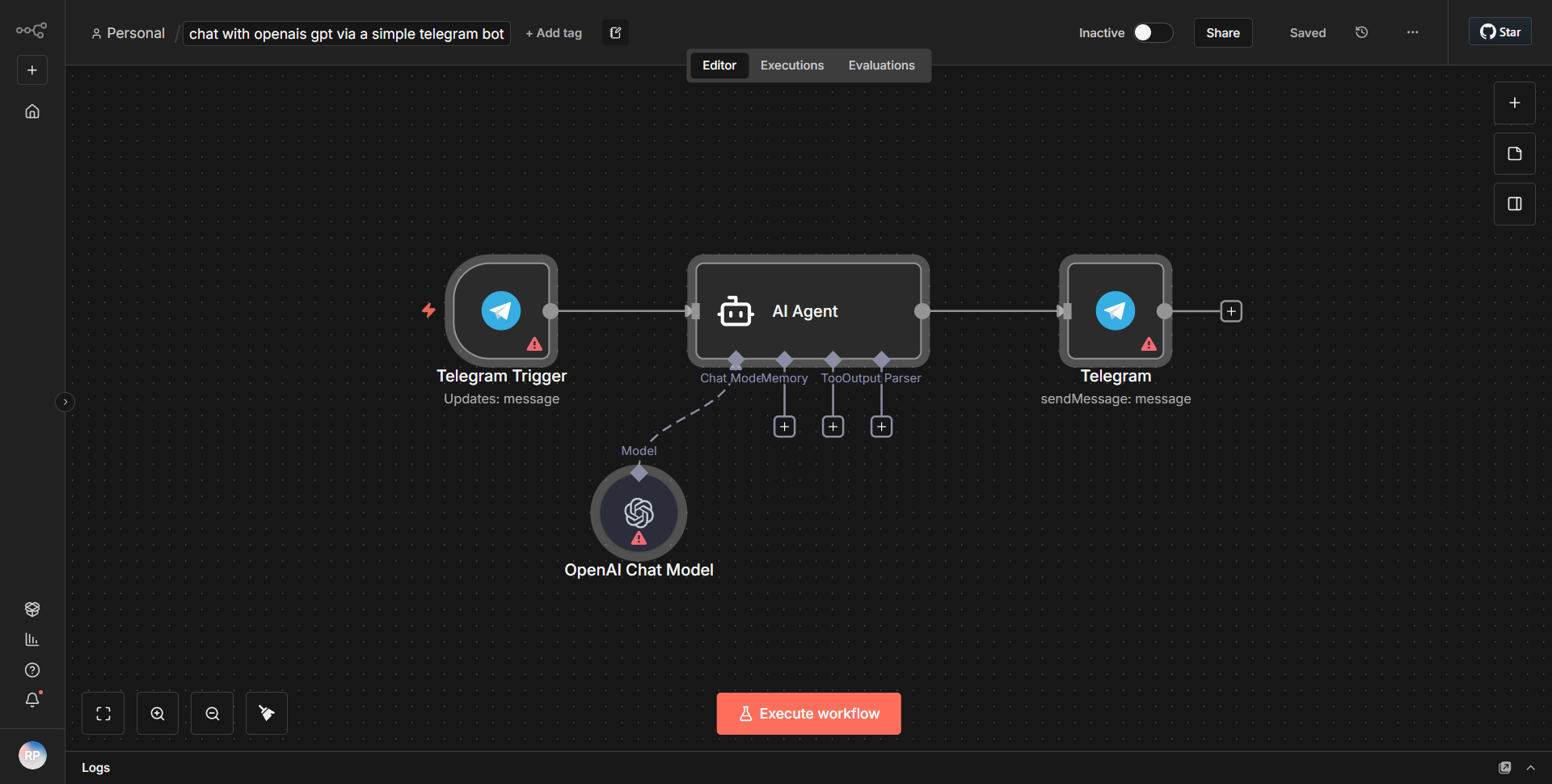
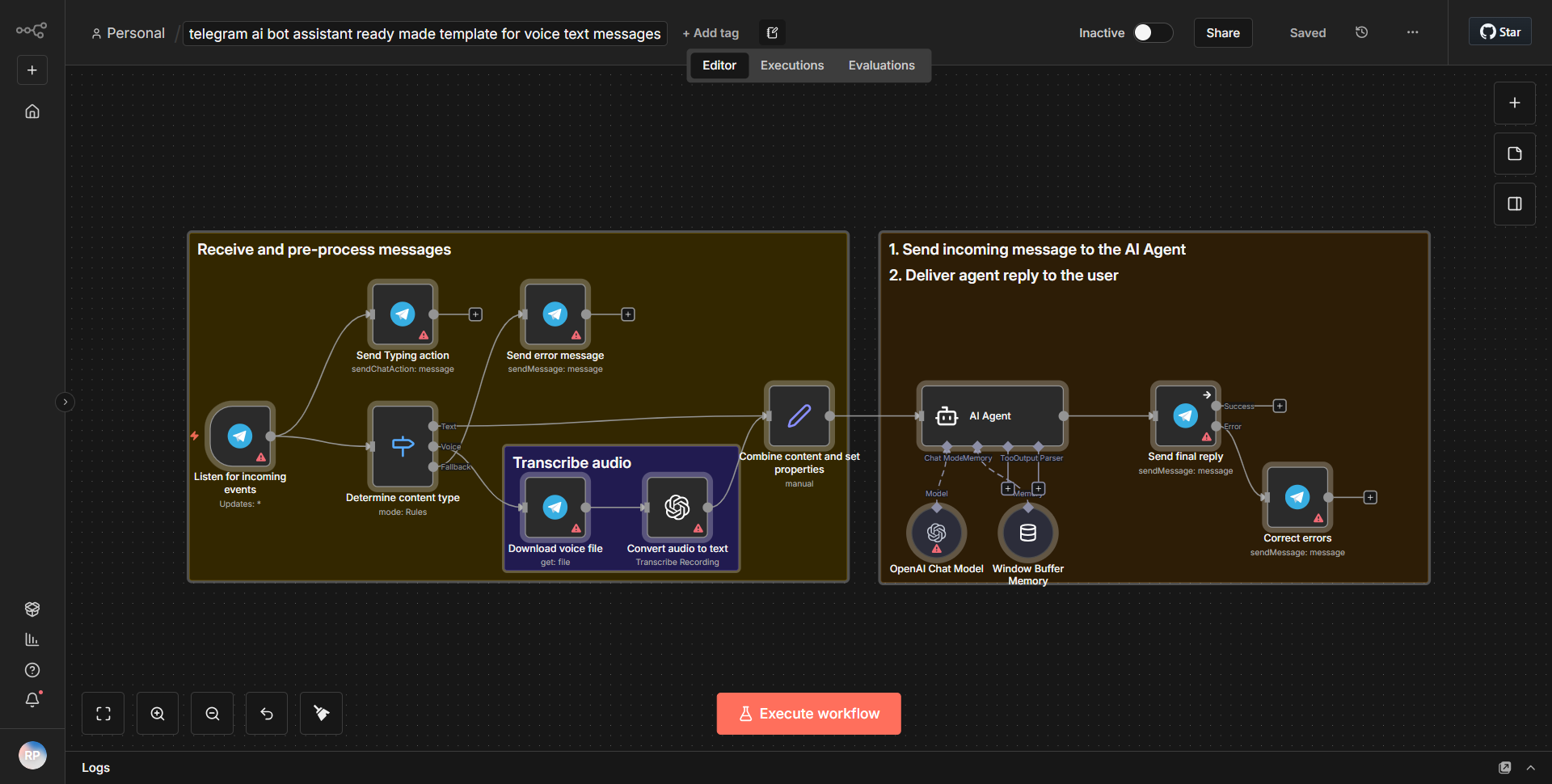
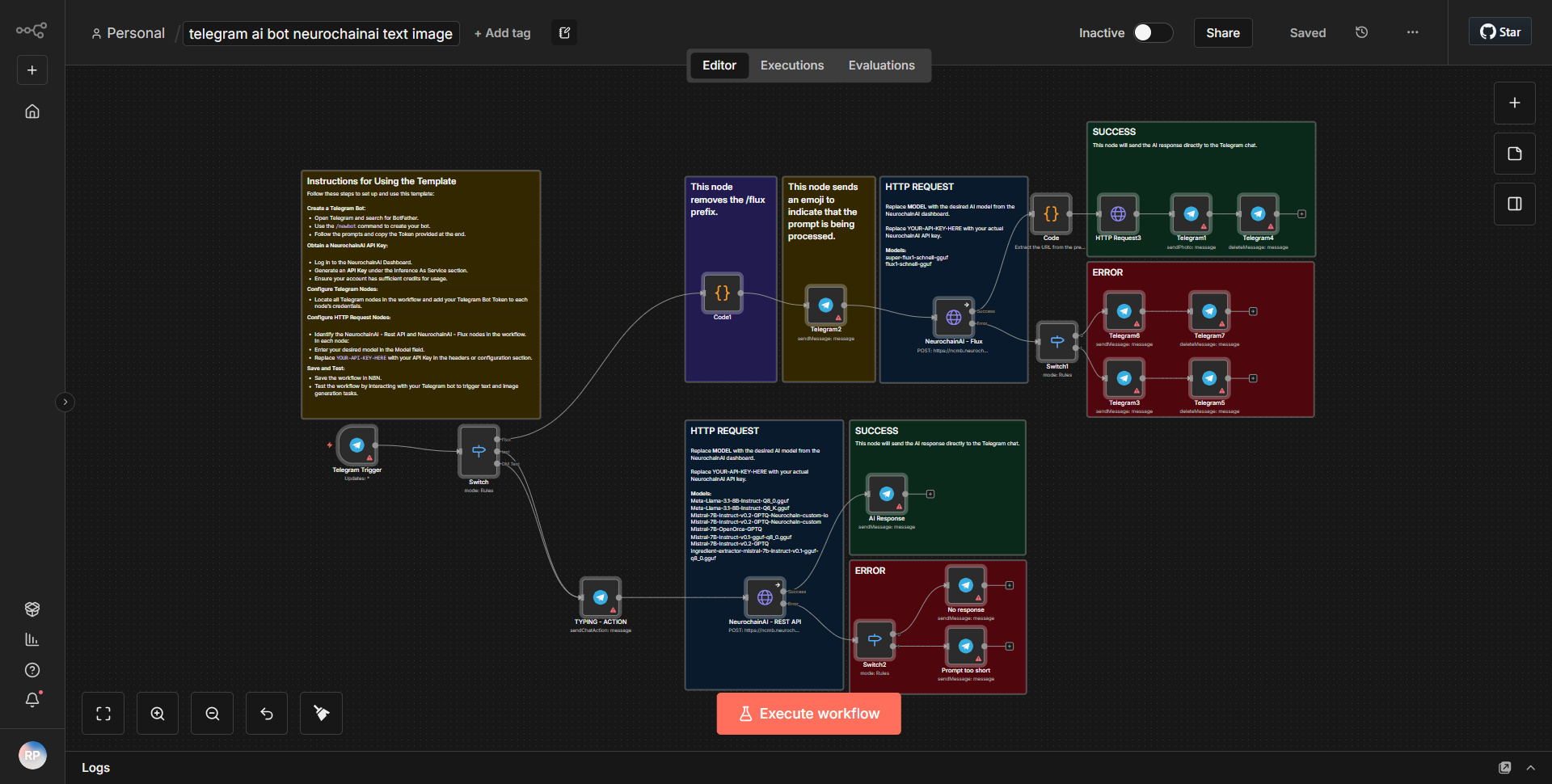
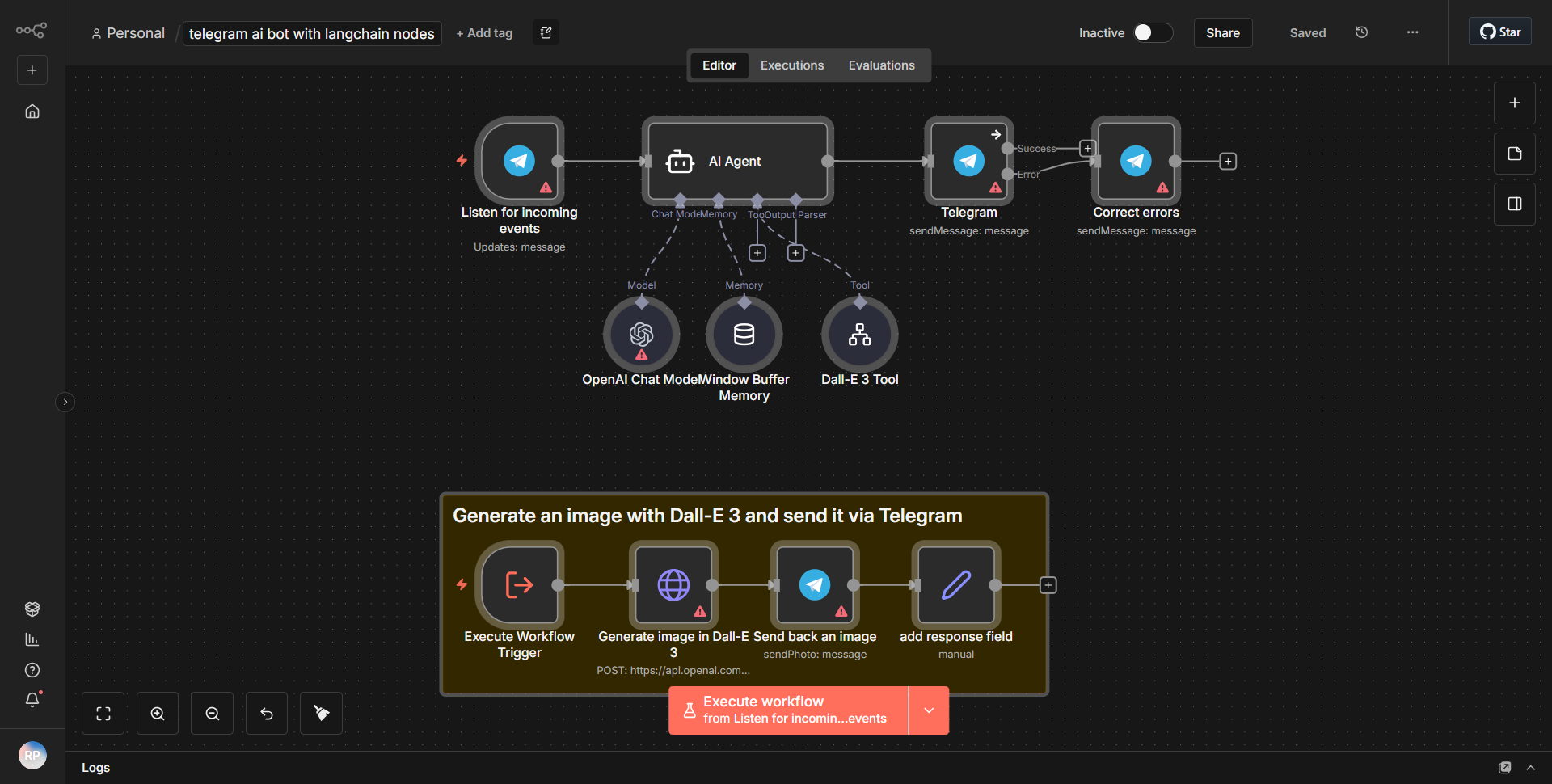
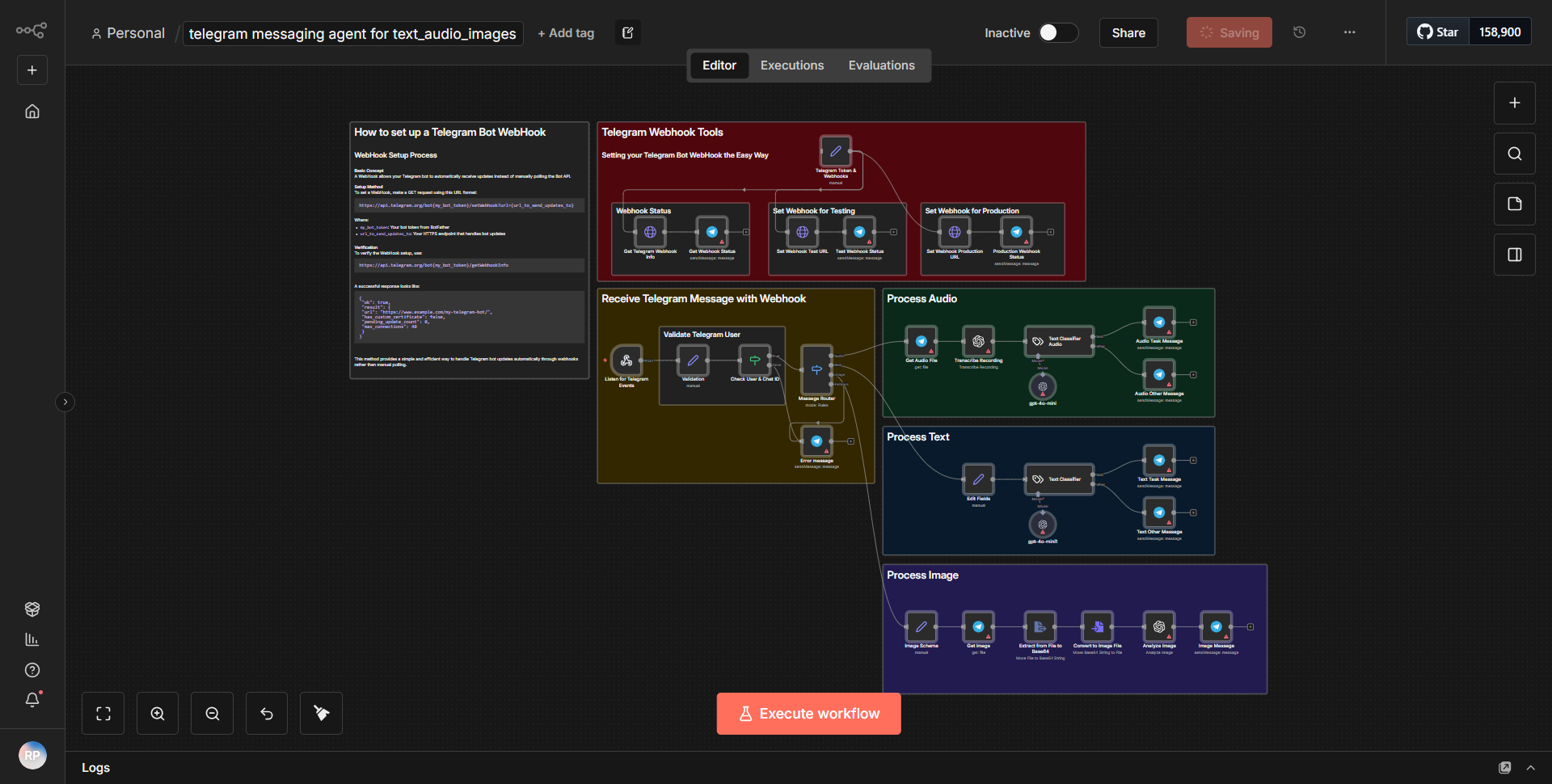
「Text_Audio_Images 用 Telegram Communication Bot」というワークフローは、テキスト、音声、画像を処理することで Telegram を介したマルチモーダル通信を促進するように設計されています。ワークフローは、指定されたチャットで新しいメッセージが受信されるたびにアクティブ化される Telegram Trigger ノードから始まります。このノードは、受信メッセージと、コンテンツの種類 (テキスト、オーディオ、または画像) を含むそのメタデータをキャプチャします。
トリガーに続いて、ワークフローは Function ノードを使用して、受信したコンテンツのタイプを決定します。このノードは受信データを処理し、それがテキスト、音声、画像のいずれであるかに基づいてそれをルーティングします。テキスト メッセージの場合、ワークフローは OpenAI ノードを利用して、入力テキストに基づいて応答を生成します。 OpenAI ノードはテキストを OpenAI API に送信し、OpenAI API は入力を処理して、生成された応答を返します。
音声メッセージの場合、ワークフローには、最初に Speech-to-Text サービスを使用して音声がテキストに変換される別のパスが含まれています。文字に書き起こされると、テキストは応答を生成するために OpenAI ノードに送信されます。生成された応答は Telegram チャットに送り返されます。
画像の場合、ワークフローは画像認識サービスを通じて画像を処理し、画像の内容を分析して説明テキストを生成します。この説明テキストは OpenAI ノードに送信されて適切な応答が作成され、再び Telegram チャットに中継されます。
最後に、OpenAI ノードによって生成されたすべての応答は、テキスト、音声、または画像入力からのものであっても、Telegram Send Message ノードを使用して Telegram チャットに送り返され、通信ループが完了します。
主な機能
1. マルチモーダル入力処理:
ワークフローはテキスト、音声、画像を処理できるため、Telegram 内での多様な通信方法が可能になります。
2. AI を活用した応答:
OpenAI の機能を利用して、受信した入力に基づいてインテリジェントでコンテキストを認識した応答を生成します。
3. 音声からテキストへの変換:
音声メッセージをテキストに変換し、ボットが音声メッセージを効果的に理解して応答できるようにします。
4. 画像認識:
チャットで送信された画像を分析し、説明テキストを生成し、視覚的なコンテンツに基づいてボットの対話機能を強化します。
5. リアルタイム インタラクション:
ワークフローは受信メッセージによってトリガーされ、即時の応答とユーザーとの関わりを保証します。
ツールの統合
ワークフローは、効果的に機能するためにいくつかのツールとサービスを統合します。
- テレグラム トリガー:
テレグラムからの受信メッセージをキャプチャします。
- 関数ノード:
受信コンテンツのタイプ (テキスト、オーディオ、画像) を決定します。
- OpenAI ノード:
応答生成のためにテキスト入力を OpenAI API に送信します。
- Speech-to-Text サービス:
音声メッセージをテキストに変換して処理します。
- 画像認識サービス:
画像を分析して説明テキストを生成します。
- Telegram メッセージ送信ノード:
Telegram チャットに応答を送り返します。
API キーが必要です
このワークフローを操作するには、次の API キーと認証情報が必要です。
- OpenAI API キー:
OpenAI サービスにアクセスして応答を生成するために必要です。
- Telegram Bot Token:
Telegram Trigger ノードと Send Message ノードが Telegram API と対話するために必要です。
ワークフロー設定には追加の API キーや認証情報は記載されていません。