Text processing ETL workflow
This workflow establishes an ETL pipeline for text analysis, retrieving information from Twitter, saving it in both MongoDB and PostgreSQL, and dispatching alerts to Slack according to sentiment evaluation.
How it works
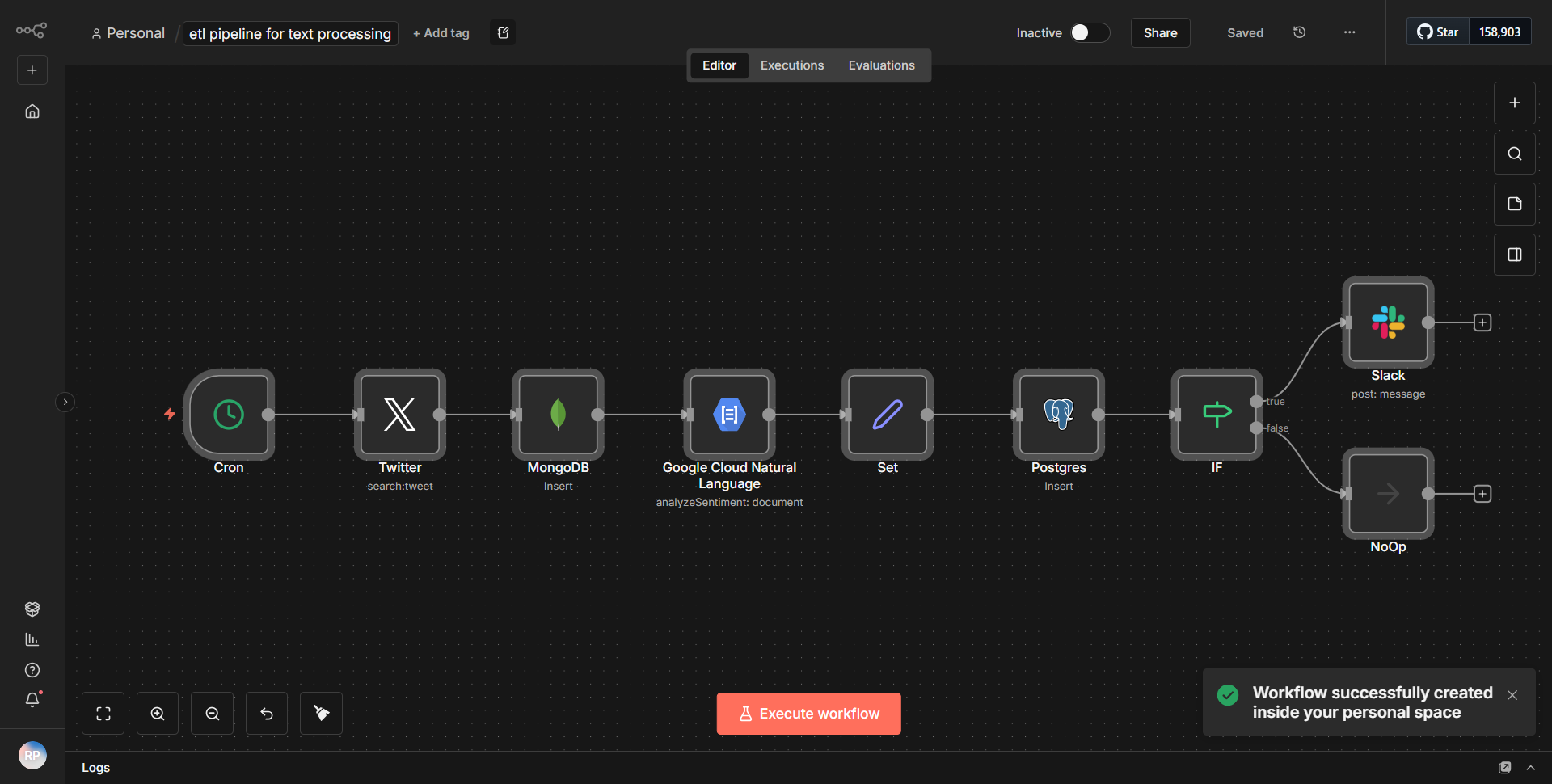
The Text Processing ETL workflow is designed to facilitate an end-to-end pipeline for text analysis, specifically focusing on data retrieval from Twitter, storage in both MongoDB and PostgreSQL, and alert dispatching to Slack based on sentiment evaluation. The workflow operates in a sequential manner, utilizing various nodes to ensure smooth data flow and processing.
1. Twitter Node:
The workflow begins with the Twitter node, which is configured to retrieve tweets based on specific search criteria. This node is responsible for fetching real-time tweets that match the defined parameters, such as keywords or hashtags.
2. Sentiment Analysis Node:
Once the tweets are retrieved, they are passed to a sentiment analysis node. This node processes the text of the tweets to evaluate their sentiment, categorizing them as positive, negative, or neutral. The results of this analysis are crucial for the subsequent steps in the workflow.
3. MongoDB Node:
After sentiment evaluation, the workflow directs the processed tweet data, along with its sentiment score, to a MongoDB node. This node is configured to insert the tweet information into a MongoDB collection, allowing for efficient storage and retrieval of the data for future analysis.
4. PostgreSQL Node:
Simultaneously, the same processed data is sent to a PostgreSQL node. This node is set up to insert the tweet information into a PostgreSQL database, ensuring that the data is stored in a relational format, which can be useful for structured queries and reporting.
5. Slack Node:
Finally, based on the sentiment analysis results, the workflow utilizes a Slack node to send alerts. If a tweet is classified as having a negative sentiment, an alert is dispatched to a designated Slack channel, notifying team members of potentially concerning content.
This structured flow ensures that data is not only collected and analyzed but also stored in multiple formats and communicated effectively to relevant stakeholders.
Key Features
- Real-time Data Retrieval:
The workflow continuously fetches tweets from Twitter, enabling timely analysis of public sentiment on various topics.
- Sentiment Analysis:
The integration of sentiment analysis provides valuable insights into public opinion, allowing for proactive responses to negative sentiments.
- Multi-Database Storage:
By storing data in both MongoDB and PostgreSQL, the workflow offers flexibility in data management, catering to different use cases and query requirements.
- Automated Alerts:
The Slack integration ensures that stakeholders are promptly informed about significant sentiment changes, facilitating quick decision-making and action.
- Scalability:
The workflow can be easily modified to include additional data sources or processing steps, making it adaptable to evolving analytical needs.
Tools Integration
- Twitter Node:
Used for fetching tweets based on specified search criteria.
- Sentiment Analysis Node:
Processes the text of the tweets to determine their sentiment.
- MongoDB Node:
Stores the tweet data in a MongoDB database for unstructured data management.
- PostgreSQL Node:
Inserts tweet data into a PostgreSQL database for structured data management.
- Slack Node:
Sends alerts to a Slack channel based on the sentiment evaluation of the tweets.
API Keys Required
- Twitter API Key:
Required for authenticating and accessing Twitter data.
- MongoDB Connection String:
Needed to connect to the MongoDB database.
- PostgreSQL Connection String:
Required for connecting to the PostgreSQL database.
- Slack Webhook URL:
Necessary for sending messages to the specified Slack channel.
This workflow requires proper configuration of API keys and connection strings to function effectively, ensuring secure and authenticated access to the respective services.