Supabase Data Insertion, Upsertion, and Retrieval
This workflow illustrates the process of executing insertion, upsertion, and retrieval actions using Supabase, particularly aimed at managing vector embeddings and their related metadata.
How it works
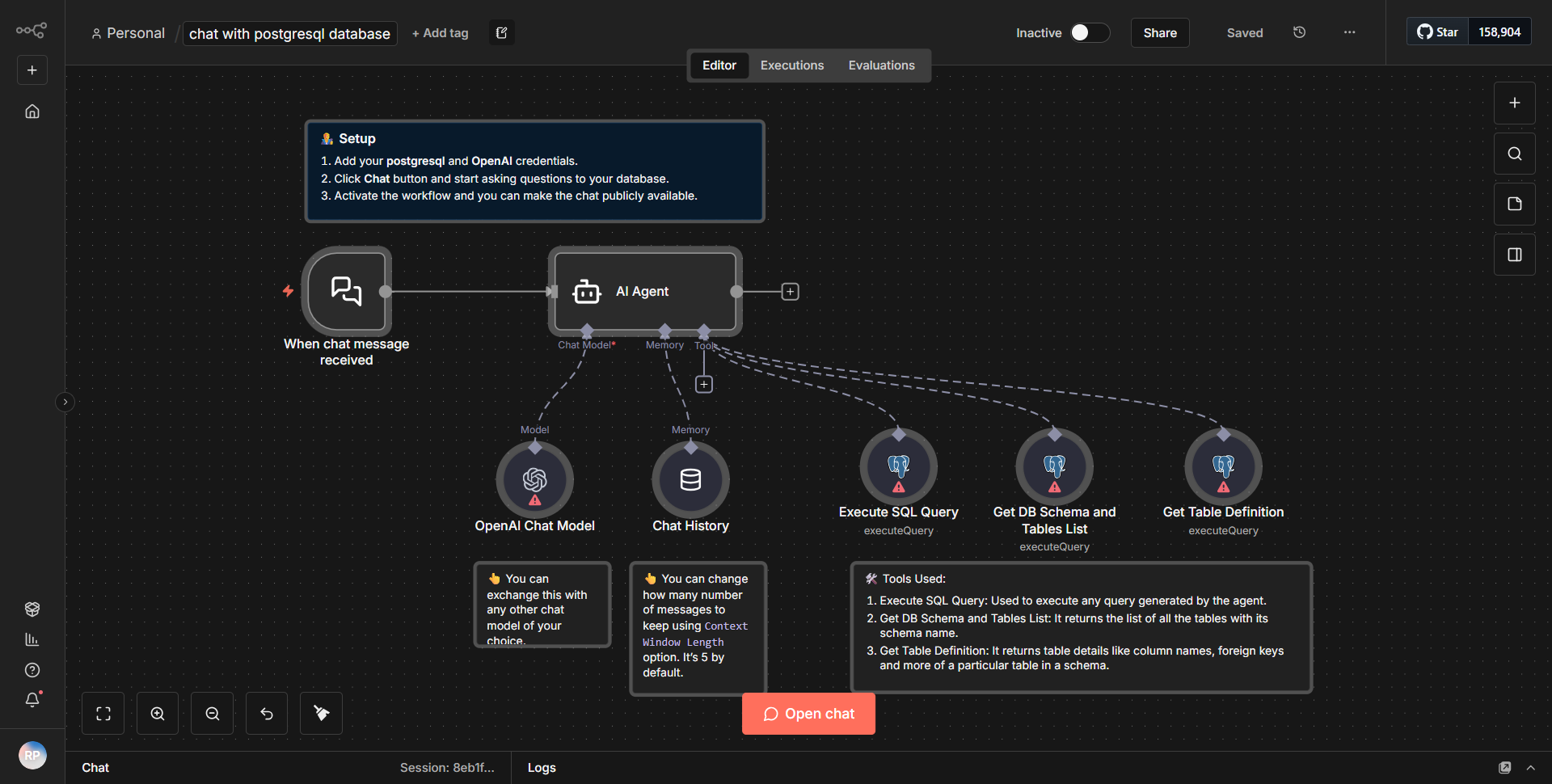
This workflow is designed to manage data operations in Supabase, specifically focusing on the insertion, upsertion, and retrieval of vector embeddings along with their associated metadata. The workflow begins with a trigger node that initiates the process based on a specific event.
1. Trigger Node:
The workflow starts with a trigger that listens for incoming data or events. This could be a webhook or a scheduled trigger, depending on the specific implementation.
2. Data Preparation:
After the trigger, the workflow utilizes a function node to prepare the data for insertion. This node processes the incoming data, ensuring it is formatted correctly for Supabase. It may involve transforming the data structure or extracting necessary fields.
3. Supabase Insert Node:
The next step involves a Supabase node configured to insert new records into a specified table. This node takes the prepared data and sends it to Supabase, creating new entries in the database.
4. Supabase Upsert Node:
Following the insertion, the workflow includes an upsert operation using another Supabase node. This node checks for existing records based on a unique identifier and updates them if they exist or inserts them if they do not. This ensures that the database remains up-to-date with the latest information.
5. Supabase Retrieve Node:
Finally, the workflow retrieves data from Supabase using a retrieval node. This node queries the database for specific records, which can be used for further processing or returned as a response to the initial trigger.
Throughout the workflow, data flows seamlessly from one node to the next, ensuring that operations are executed in the correct sequence to maintain data integrity and consistency.
Key Features
- Data Insertion:
The workflow allows for the straightforward insertion of new records into Supabase, making it easy to add new vector embeddings and metadata.
- Upsertion Capability:
The upsert functionality ensures that existing records are updated without duplication, which is crucial for maintaining accurate data in applications that frequently change.
- Data Retrieval:
The ability to query and retrieve data from Supabase enables users to access and utilize stored vector embeddings and metadata efficiently.
- Custom Data Processing:
The inclusion of a function node allows for custom data transformations, providing flexibility in how data is prepared before being sent to Supabase.
- Event-Driven Architecture:
The workflow can be triggered by various events, making it adaptable to different use cases and integration scenarios.
Tools Integration
- Supabase:
The primary service used for database operations, including insertion, upsertion, and retrieval of records.
- Function Node:
Used for preparing and transforming data before it is sent to Supabase.
- Trigger Node:
Initiates the workflow based on specific events or schedules.
API Keys Required
To operate this workflow, an API key for Supabase is required. This key is necessary for authenticating requests made to the Supabase service. Ensure that the appropriate credentials are configured in the n8n environment to facilitate seamless communication with the Supabase API.