Segmentation RAG_Context-Sensitive : transfert de Google Drive vers Pinecone via OpenRouter et Gemini
Exécute une segmentation contextuelle des fichiers Google Drive, les transfère vers Pinecone pour le stockage vectoriel et utilise OpenRouter & Gemini pour un RAG amélioré.
Comment ça marche
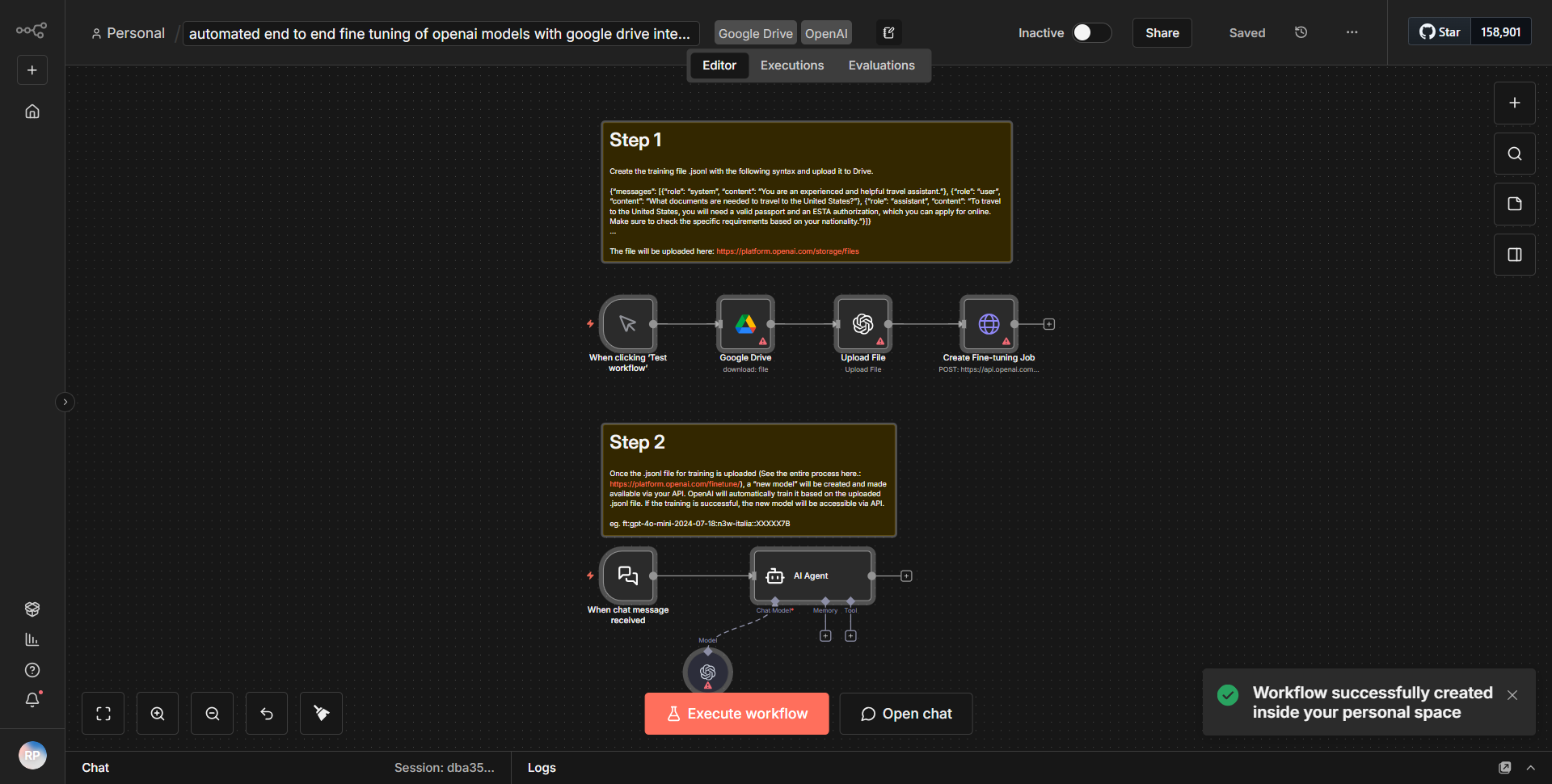
Le flux de travail intitulé « RAG_Context-Sensitive Segmentation : Transferting from Google Drive to Pinecone through OpenRouter & Gemini » est conçu pour exécuter une segmentation contextuelle des fichiers stockés dans Google Drive et transférer les données segmentées vers Pinecone pour le stockage vectoriel. Le flux de travail commence par le nœud Google Drive, qui récupère les fichiers en fonction de critères spécifiés. Une fois les fichiers récupérés, ils sont traités via une série de nœuds qui gèrent la segmentation et la transformation des données.
1. Nœud Google Drive :
ce nœud est chargé de récupérer les fichiers d'un dossier Google Drive spécifié. Il utilise l'API Google Drive pour accéder et récupérer les documents nécessaires.
2. OpenRouter Node :
Une fois les fichiers récupérés, ils sont envoyés au nœud OpenRouter, qui traite les données texte. Ce nœud est crucial pour améliorer le contexte des données, permettant une segmentation plus efficace.
3. Nœud Gemini :
Suite au traitement par OpenRouter, les données sont transmises au nœud Gemini. Ce nœud effectue la segmentation contextuelle réelle, décomposant le texte en morceaux gérables tout en préservant l'intégrité contextuelle des informations.
4. Nœud Pinecone :
Une fois la segmentation terminée, les morceaux résultants sont envoyés au nœud Pinecone. Ce nœud est chargé de stocker les données vectorisées dans Pinecone, une base de données vectorielles qui permet une récupération efficace et des recherches de similarité.
5. Résultat final :
Le flux de travail se termine par le transfert réussi de données segmentées vers Pinecone, où elles peuvent être utilisées pour diverses applications, telles que l'apprentissage automatique ou l'analyse de données.
Principales fonctionnalités
- Segmentation contextuelle :
le flux de travail utilise des techniques avancées pour garantir que la segmentation du texte conserve sa pertinence contextuelle, ce qui est essentiel pour les applications qui reposent sur la compréhension de la signification des données.
- Intégration transparente :
le flux de travail intègre plusieurs services (Google Drive, OpenRouter, Gemini et Pinecone), permettant un processus rationalisé depuis la récupération des données jusqu'au stockage.
- Transfert de données automatisé :
en automatisant le transfert de données segmentées vers Pinecone, le flux de travail réduit les interventions manuelles et augmente l'efficacité de la gestion des données.
- Évolutivité :
l'utilisation de Pinecone pour le stockage vectoriel permet au flux de travail d'évoluer efficacement, en s'adaptant à de grands ensembles de données et à des requêtes complexes.
- Enhanced RAG (Retrieval-Augmented Generation) :
en utilisant OpenRouter et Gemini, le flux de travail améliore les capacités de RAG, le rendant ainsi adapté aux applications nécessitant une récupération et une génération de données de haute qualité.
Intégration d'outils
- Google Drive Node :
utilisé pour récupérer des fichiers depuis Google Drive.
- OpenRouter Node :
traite les données texte pour améliorer le contexte.
- Gemini Node :
effectue une segmentation contextuelle du texte.
- Pinecone Node :
stocke les données segmentées et vectorisées pour une récupération efficace.
Clés API requises
- Clé API Google Drive :
requise pour accéder aux fichiers depuis Google Drive.
- Clé API Pinecone :
Nécessaire pour stocker et gérer les données dans Pinecone.
- Clé API OpenRouter :
nécessaire au traitement des données via le service OpenRouter.
- Clé API Gemini :
requise pour utiliser le service Gemini pour la segmentation.
Aucune clé API ou identifiant d'authentification supplémentaire n'est nécessaire au-delà de ceux spécifiés pour les services respectifs.