RAG_Segmentación sensible al contexto: transferencia de Google Drive a Pinecone a través de OpenRouter y Gemini
Ejecuta la segmentación sensible al contexto de archivos de Google Drive, transfiriéndolos a Pinecone para almacenamiento vectorial y utilizando OpenRouter y Gemini para RAG mejorado.
Cómo funciona
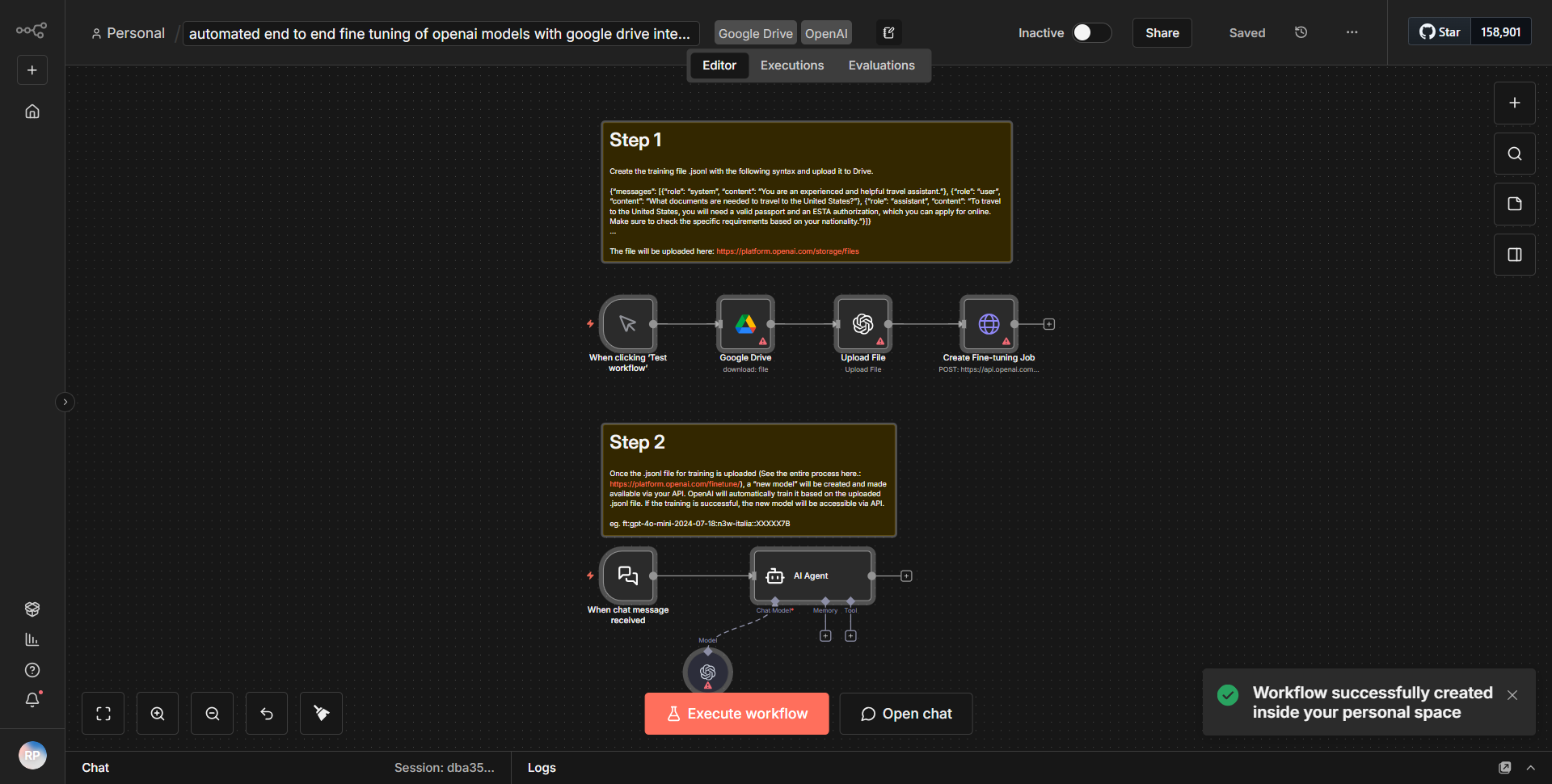
El flujo de trabajo titulado "RAG_Segmentación sensible al contexto: transferencia de Google Drive a Pinecone a través de OpenRouter y Gemini" está diseñado para ejecutar una segmentación sensible al contexto de archivos almacenados en Google Drive y transferir los datos segmentados a Pinecone para su almacenamiento vectorial. El flujo de trabajo comienza con el nodo de Google Drive, que recupera archivos según criterios específicos. Una vez que se obtienen los archivos, se procesan a través de una serie de nodos que manejan la segmentación y la transformación de datos.
1. Nodo de Google Drive:
este nodo es responsable de recuperar archivos de una carpeta específica de Google Drive. Utiliza la API de Google Drive para acceder y recuperar los documentos necesarios.
2. Nodo OpenRouter:
una vez recuperados los archivos, se envían al nodo OpenRouter, que procesa los datos de texto. Este nodo es crucial para mejorar el contexto de los datos, permitiendo una segmentación más efectiva.
3. Nodo Gemini:
Después del procesamiento por parte de OpenRouter, los datos se pasan al nodo Gemini. Este nodo realiza la segmentación real sensible al contexto, dividiendo el texto en fragmentos manejables y preservando al mismo tiempo la integridad contextual de la información.
4. Nodo Pinecone:
una vez que se completa la segmentación, los fragmentos resultantes se envían al nodo Pinecone. Este nodo es responsable de almacenar los datos vectorizados en Pinecone, una base de datos vectorial que permite una recuperación eficiente y búsquedas de similitudes.
5. Resultado final:
el flujo de trabajo concluye con la transferencia exitosa de datos segmentados a Pinecone, donde se pueden utilizar para diversas aplicaciones, como aprendizaje automático o análisis de datos.
Características clave
- Segmentación sensible al contexto:
el flujo de trabajo emplea técnicas avanzadas para garantizar que la segmentación del texto mantenga la relevancia contextual, lo cual es fundamental para las aplicaciones que dependen de la comprensión del significado detrás de los datos.
- Integración perfecta:
el flujo de trabajo integra múltiples servicios (Google Drive, OpenRouter, Gemini y Pinecone), lo que permite un proceso optimizado desde la recuperación de datos hasta el almacenamiento.
- Transferencia de datos automatizada:
al automatizar la transferencia de datos segmentados a Pinecone, el flujo de trabajo reduce la intervención manual y aumenta la eficiencia en la gestión de datos.
- Escalabilidad:
el uso de Pinecone para el almacenamiento vectorial permite que el flujo de trabajo se escale de manera eficiente, acomodando grandes conjuntos de datos y consultas complejas.
- RAG mejorado (recuperación-generación aumentada):
al utilizar OpenRouter y Gemini, el flujo de trabajo mejora las capacidades de RAG, haciéndolo adecuado para aplicaciones que requieren recuperación y generación de datos de alta calidad.
Integración de herramientas
- Nodo de Google Drive:
se utiliza para recuperar archivos de Google Drive.
- Nodo OpenRouter:
Procesa los datos de texto para mejorar el contexto.
- Gemini Node:
Realiza una segmentación del texto sensible al contexto.
- Nodo Pinecone:
almacena los datos segmentados y vectorizados para una recuperación eficiente.
Se requieren claves API
- Clave API de Google Drive:
necesaria para acceder a archivos desde Google Drive.
- Clave API de Pinecone:
Necesaria para almacenar y administrar datos en Pinecone.
- Clave API de OpenRouter:
necesaria para procesar datos a través del servicio OpenRouter.
- Clave API de Gemini:
necesaria para utilizar el servicio Gemini para la segmentación.
No se necesitan claves API ni credenciales de autenticación adicionales más allá de las especificadas para los servicios respectivos.