Insira documentos grandes em um banco de dados vetorial usando Supabase e Notion.
Lida com documentos extensos dividindo-os em segmentos, criando embeddings e inserindo-os em um banco de dados vetorial Supabase, utilizando o Notion como fonte dos documentos.
Como funciona
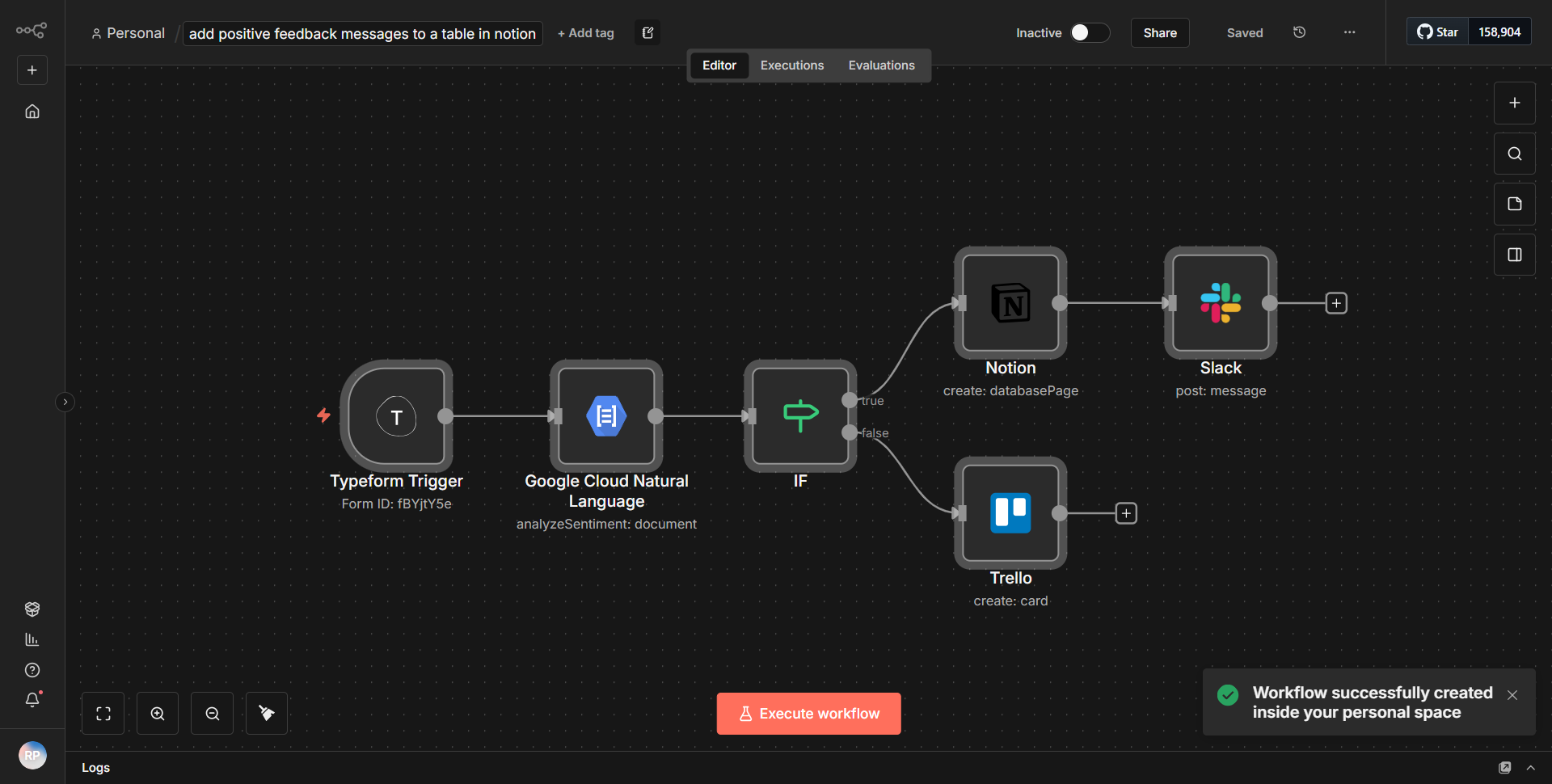
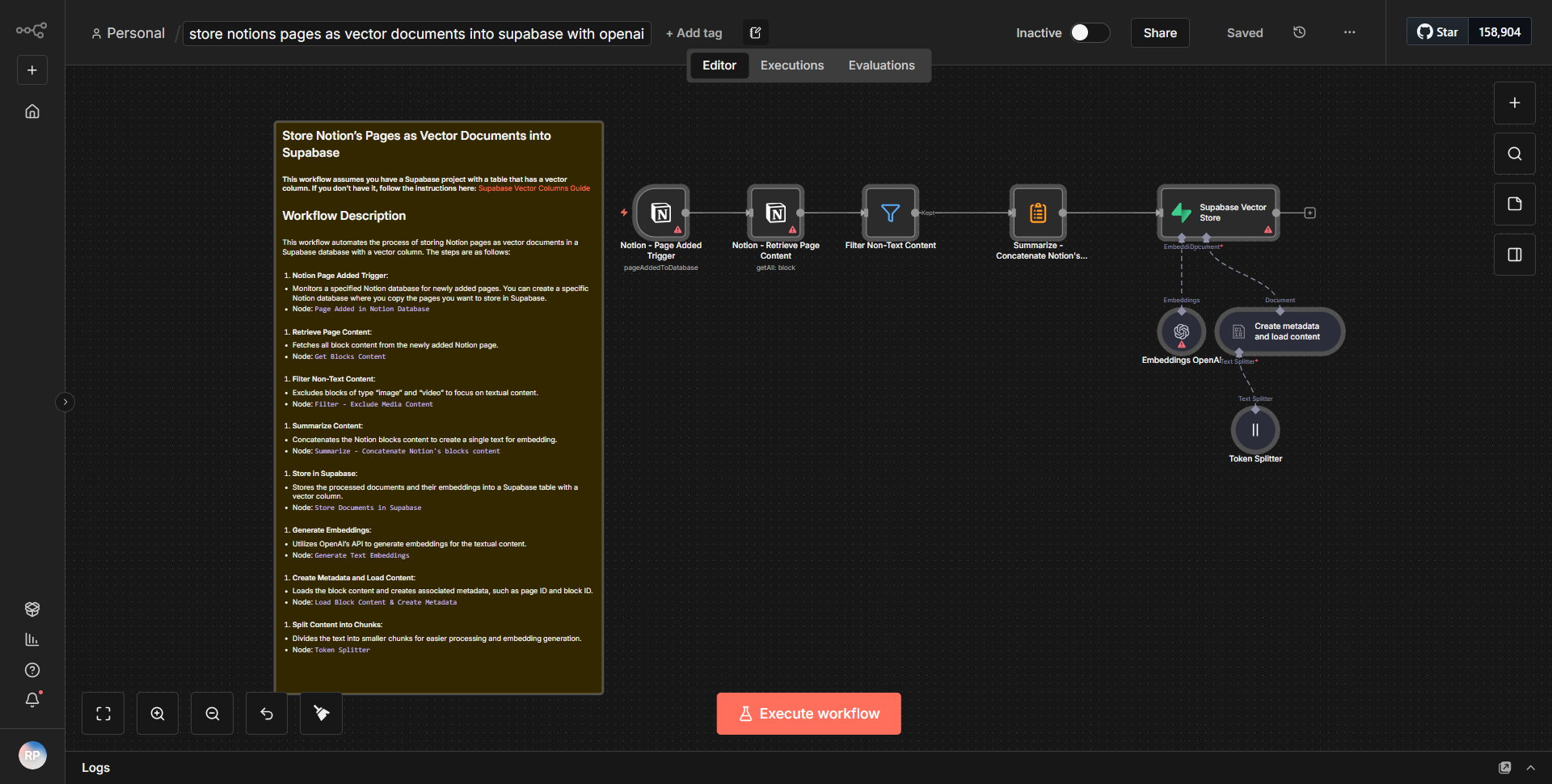
O fluxo de trabalho foi projetado para processar documentos grandes do Notion, segmentá-los, criar embeddings e armazená-los em um banco de dados vetorial Supabase. O fluxo de trabalho começa com um nó acionador que recupera documentos de um banco de dados Notion especificado. Uma vez obtidos os documentos, eles são segmentados em partes menores para facilitar o processamento. Cada segmento é então passado para um nó de criação de incorporação, que gera representações vetoriais dos segmentos de texto. Essas incorporações são cruciais para recuperação posterior e pesquisas de similaridade no banco de dados de vetores.
Após a criação dos embeddings, o fluxo de trabalho utiliza um nó Supabase para inserir os embeddings em uma tabela de vetores designada no banco de dados Supabase. Esta etapa garante que os embeddings sejam armazenados em um formato que permita consulta e recuperação eficientes. O fluxo de trabalho termina com uma mensagem ou notificação de sucesso, confirmando que os embeddings foram inseridos com sucesso no banco de dados.
As conexões entre os nós são lineares, com cada etapa dependente da conclusão bem-sucedida da anterior. Esta abordagem estruturada garante que documentos grandes sejam manuseados e armazenados de forma eficaz, de forma a otimizar a sua recuperação em operações futuras.
Principais recursos
1. Segmentação de documentos:
o fluxo de trabalho divide de forma inteligente documentos grandes em segmentos gerenciáveis, permitindo processamento eficiente e criação de incorporação.
2. Geração de incorporação:
utiliza algoritmos avançados para criar incorporações vetoriais a partir de segmentos de texto, que são essenciais para pesquisas de similaridade em bancos de dados vetoriais.
3. Integração Supabase:
O fluxo de trabalho se integra perfeitamente ao Supabase, permitindo o armazenamento de embeddings em um banco de dados vetorial robusto.
4. Notion como fonte:
Ao usar o Notion como fonte do documento, o fluxo de trabalho aproveita uma ferramenta popular de anotações e gerenciamento de projetos, tornando-o acessível para usuários já familiarizados com o Notion.
5. Processo Automatizado:
Todo o fluxo de trabalho é automatizado, reduzindo a intervenção manual e agilizando o processo de manuseio de documentos grandes.
Integração de ferramentas
- Notion:
usado como fonte de documentos, permitindo que o fluxo de trabalho busque conteúdo diretamente de um banco de dados do Notion.
- Supabase:
atua como banco de dados vetorial onde os embeddings são armazenados, fornecendo uma solução escalável para gerenciar grandes conjuntos de dados.
- Nós n8n:
nós específicos usados no fluxo de trabalho incluem:
• Nó de noção para busca de documentos.
• Nó de função para segmentação de documentos.
• Incorporação de nó para geração de representações vetoriais.
• Nó Supabase para inserção de dados no banco de dados.
Chaves de API necessárias
Para executar esse fluxo de trabalho com êxito, são necessárias as seguintes chaves de API e credenciais:
- Chave API do Notion:
necessária para autenticar e acessar o banco de dados do Notion.
- Chave de API Supabase:
necessária para conectar e executar operações no banco de dados vetorial Supabase.
- URL do Projeto Supabase:
Necessário para estabelecer uma conexão com o projeto Supabase específico onde os embeddings serão armazenados.