Insérez des documents volumineux dans une base de données vectorielle à l'aide de Supabase et Notion.
Gère des documents volumineux en les divisant en segments, en créant des intégrations et en les insérant dans une base de données vectorielle Supabase, en utilisant Notion comme source des documents.
Comment ça marche
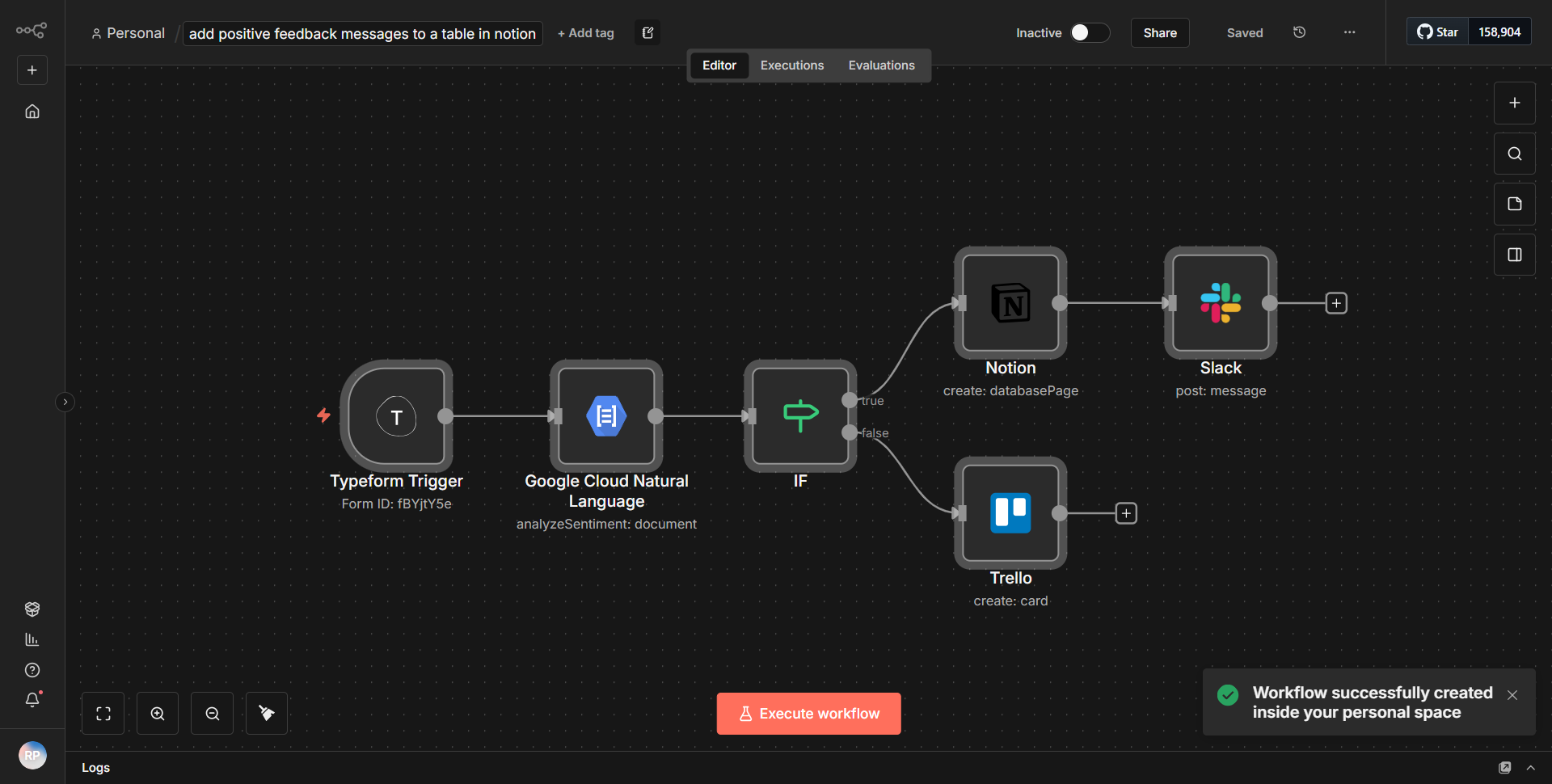
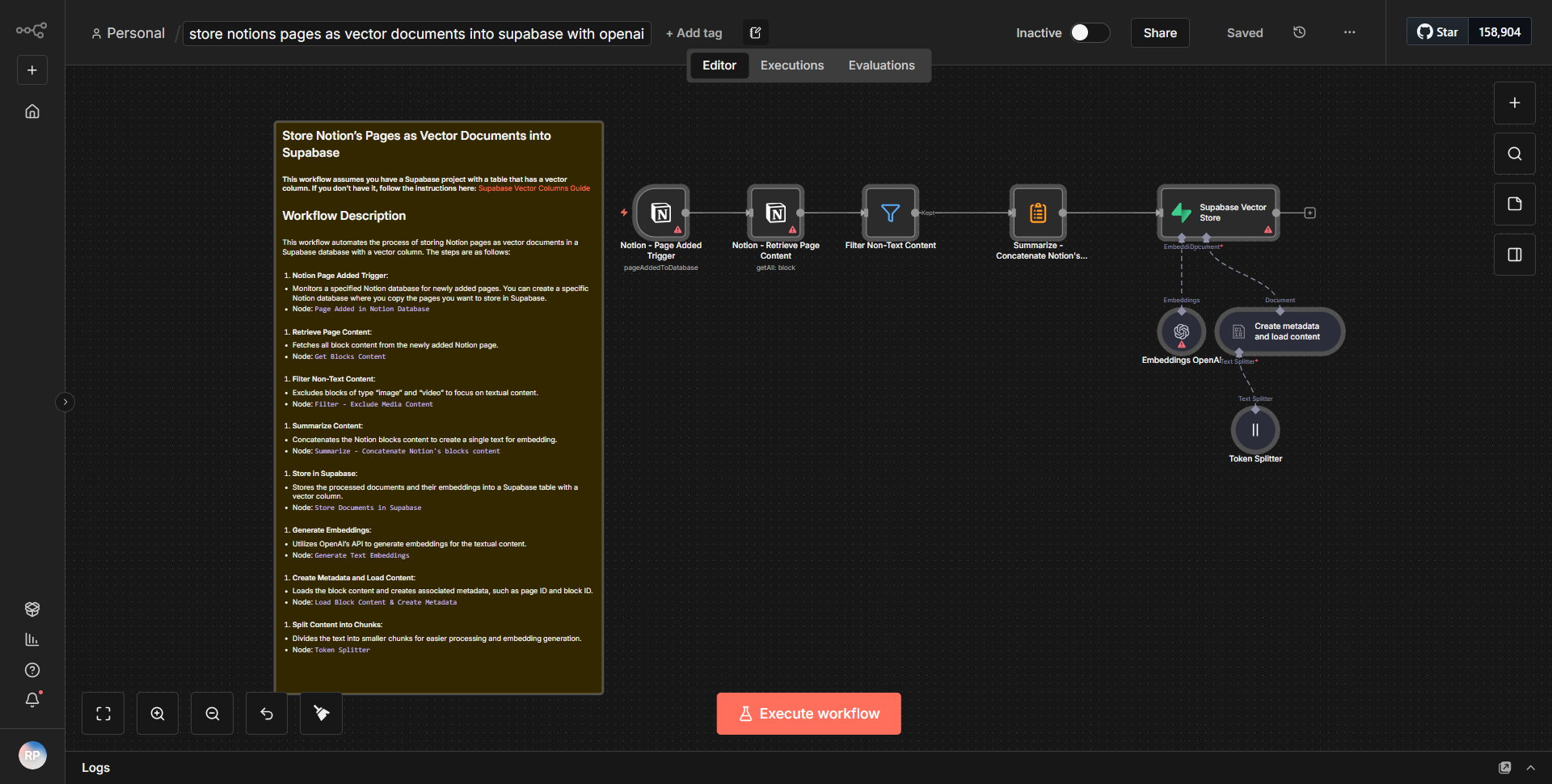
Le flux de travail est conçu pour traiter des documents volumineux à partir de Notion, les segmenter, créer des intégrations et stocker ces intégrations dans une base de données vectorielles Supabase. Le flux de travail commence par un nœud déclencheur qui récupère les documents d'une base de données Notion spécifiée. Une fois les documents récupérés, ils sont segmentés en parties plus petites pour faciliter leur traitement. Chaque segment est ensuite transmis à un nœud de création d'intégration, qui génère des représentations vectorielles des segments de texte. Ces intégrations sont cruciales pour la récupération ultérieure et les recherches de similarité dans la base de données vectorielles.
Une fois les intégrations créées, le flux de travail utilise un nœud Supabase pour insérer les intégrations dans une table vectorielle désignée dans la base de données Supabase. Cette étape garantit que les intégrations sont stockées dans un format permettant une interrogation et une récupération efficaces. Le flux de travail se termine par un message ou une notification de réussite, confirmant que les intégrations ont été insérées avec succès dans la base de données.
Les connexions entre les nœuds sont linéaires, chaque étape dépendant de la réussite de la précédente. Cette approche structurée garantit que les documents volumineux sont traités et stockés efficacement de manière à optimiser leur récupération lors des opérations futures.
Principales fonctionnalités
1. Segmentation des documents :
le flux de travail divise intelligemment les documents volumineux en segments gérables, permettant un traitement et une création d'intégration efficaces.
2. Génération d'intégration :
il utilise des algorithmes avancés pour créer des intégrations vectorielles à partir de segments de texte, qui sont essentielles pour les recherches de similarité dans les bases de données vectorielles.
3. Intégration Supabase :
le flux de travail s'intègre de manière transparente à Supabase, permettant le stockage des intégrations dans une base de données vectorielles robuste.
4. Notion en tant que source :
en utilisant Notion comme source de document, le flux de travail exploite un outil populaire de prise de notes et de gestion de projet, le rendant accessible aux utilisateurs déjà familiers avec Notion.
5. Processus automatisé :
L'ensemble du flux de travail est automatisé, réduisant ainsi les interventions manuelles et rationalisant le processus de gestion des documents volumineux.
Intégration d'outils
- Notion :
utilisé comme source de documents, permettant au workflow de récupérer le contenu directement à partir d'une base de données Notion.
- Supabase :
agit comme une base de données vectorielle où les intégrations sont stockées, fournissant une solution évolutive pour gérer de grands ensembles de données.
- Nœuds n8n :
les nœuds spécifiques utilisés dans le flux de travail incluent :
• Noeud de notion pour récupérer des documents.
• Nœud de fonction pour segmenter les documents.
• Nœud d'intégration pour générer des représentations vectorielles.
• Nœud Supabase pour insérer des données dans la base de données.
Clés API requises
Pour exécuter correctement ce workflow, les clés API et informations d'identification suivantes sont requises :
- Clé API Notion :
nécessaire pour s'authentifier et accéder à la base de données Notion.
- Clé API Supabase :
requise pour la connexion et l'exécution d'opérations sur la base de données vectorielles Supabase.
- URL du projet Supabase :
nécessaire pour établir une connexion au projet Supabase spécifique où les intégrations seront stockées.