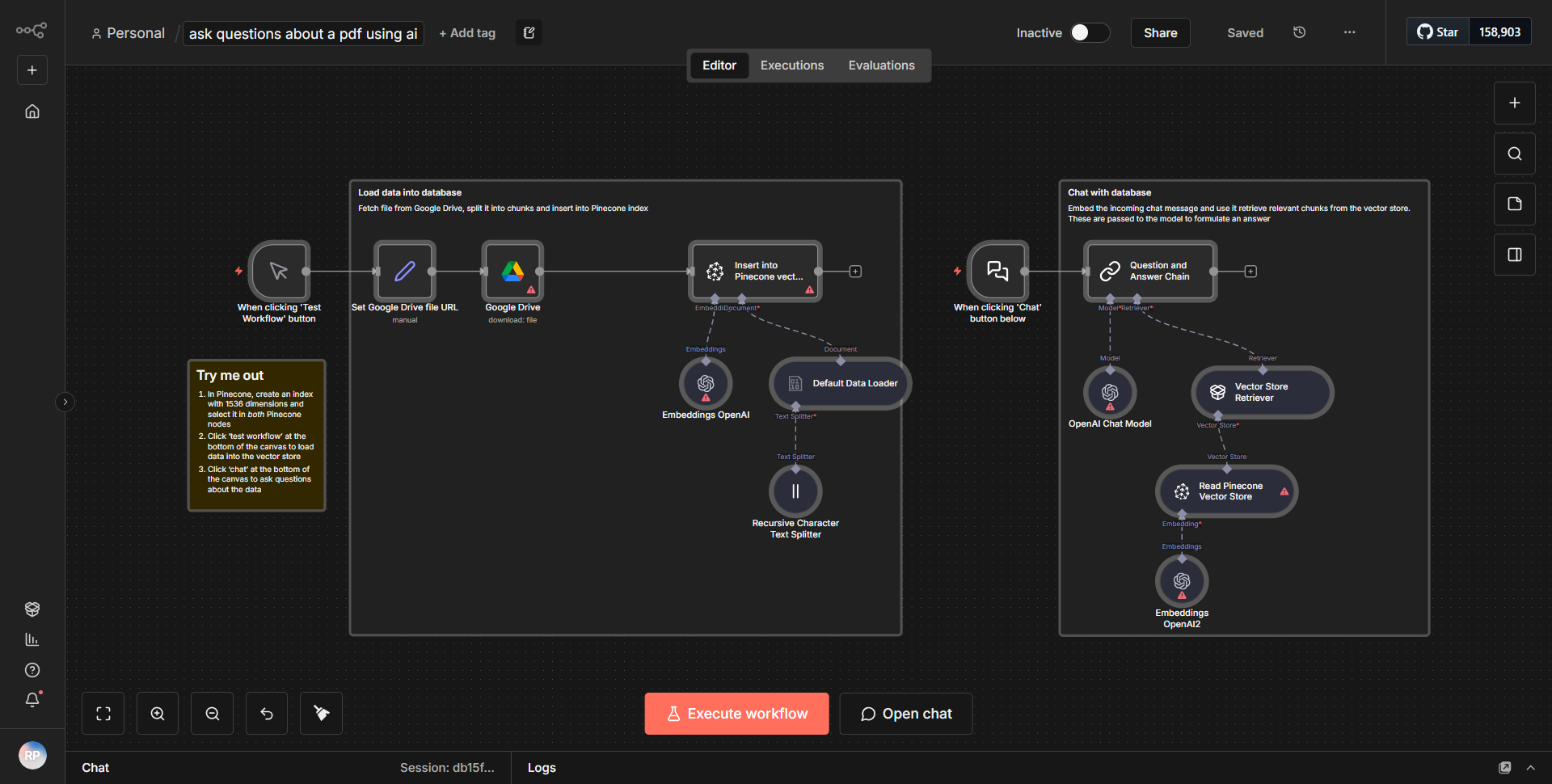
Renseignez-vous sur un PDF utilisant l’IA
Ce flux de travail récupère un fichier PDF de Google Drive, le divise en segments, traite les segments avec des intégrations OpenAI et facilite les interactions conversationnelles avec le contenu du document.
Comment ça marche
Ce flux de travail commence par la récupération d'un fichier PDF depuis Google Drive à l'aide du nœud Google Drive. Le nœud est configuré pour rechercher un fichier spécifique en fonction de son nom ou de son ID, garantissant ainsi l'accès au bon document. Une fois le PDF récupéré, le flux de travail passe au nœud « Extraction PDF », qui extrait le contenu texte du fichier PDF. Ce texte extrait est ensuite segmenté en parties plus petites pour faciliter le traitement.
Après l'extraction et la segmentation, le flux de travail utilise le nœud OpenAI pour générer des intégrations pour chaque segment de texte. Cette étape est cruciale car elle transforme les données textuelles dans un format pouvant être compris et traité par les algorithmes d’IA. Les intégrations permettent une interrogation et une interaction plus efficaces avec le contenu du document.
Une fois les intégrations créées, le flux de travail intègre une interface conversationnelle, permettant aux utilisateurs de poser des questions sur le contenu du PDF. Ceci est réalisé grâce à une série de nœuds qui gèrent les entrées de l'utilisateur, traitent les requêtes et renvoient des réponses pertinentes basées sur les intégrations générées précédemment. Le flux de travail crée efficacement une boucle dans laquelle les demandes des utilisateurs peuvent être traitées en continu, permettant une expérience interactive avec le contenu PDF.
Principales fonctionnalités
1. Récupération PDF :
le flux de travail s'intègre parfaitement à Google Drive pour récupérer des documents PDF, facilitant ainsi l'accès aux fichiers stockés dans le cloud.
2. Extraction de texte :
il utilise un nœud dédié pour extraire le texte des fichiers PDF, garantissant ainsi que toutes les informations pertinentes sont disponibles pour le traitement.
3. Segmentation du contenu :
le texte extrait est divisé en segments gérables, ce qui améliore l'efficacité du traitement de l'IA et permet des réponses plus précises aux requêtes des utilisateurs.
4. Incorporations d'IA :
en utilisant les intégrations d'OpenAI, le flux de travail transforme le texte en format vectoriel, permettant ainsi des capacités d'IA avancées pour comprendre et répondre aux demandes des utilisateurs.
5. Interface conversationnelle :
le flux de travail prend en charge un format de questions et réponses dynamique, permettant aux utilisateurs d'interagir de manière interactive avec le contenu du PDF, ce qui en fait un outil puissant pour la recherche d'informations et l'apprentissage.
Intégration d'outils
- Google Drive :
Utilisé pour récupérer le fichier PDF. Le nœud Google Drive est configuré pour accéder à des fichiers spécifiques en fonction de paramètres définis par l'utilisateur.
- Extrait PDF :
ce nœud est responsable de l'extraction du texte du document PDF, garantissant que le contenu est disponible pour un traitement ultérieur.
- OpenAI :
le nœud OpenAI est utilisé pour générer des intégrations à partir des segments de texte extraits, permettant des interactions d'IA sophistiquées.
- Webhook :
Ce nœud permet la réception des requêtes des utilisateurs, facilitant l'aspect conversationnel du workflow.
Clés API requises
Pour faire fonctionner ce workflow, les clés API et informations d'identification suivantes sont nécessaires :
- Clé API Google Drive :
requise pour l'authentification et l'accès aux fichiers stockés dans Google Drive.
- Clé API OpenAI :
nécessaire pour utiliser les services OpenAI pour générer des intégrations et traiter les requêtes des utilisateurs.
Aucune clé API ou identifiant d'authentification supplémentaire n'est requis au-delà de ceux mentionnés ci-dessus.