Inserción, inserción y recuperación de datos de Supabase
Este flujo de trabajo ilustra el proceso de ejecución de acciones de inserción, inserción y recuperación utilizando Supabase, particularmente destinadas a gestionar incrustaciones de vectores y sus metadatos relacionados.
Cómo funciona
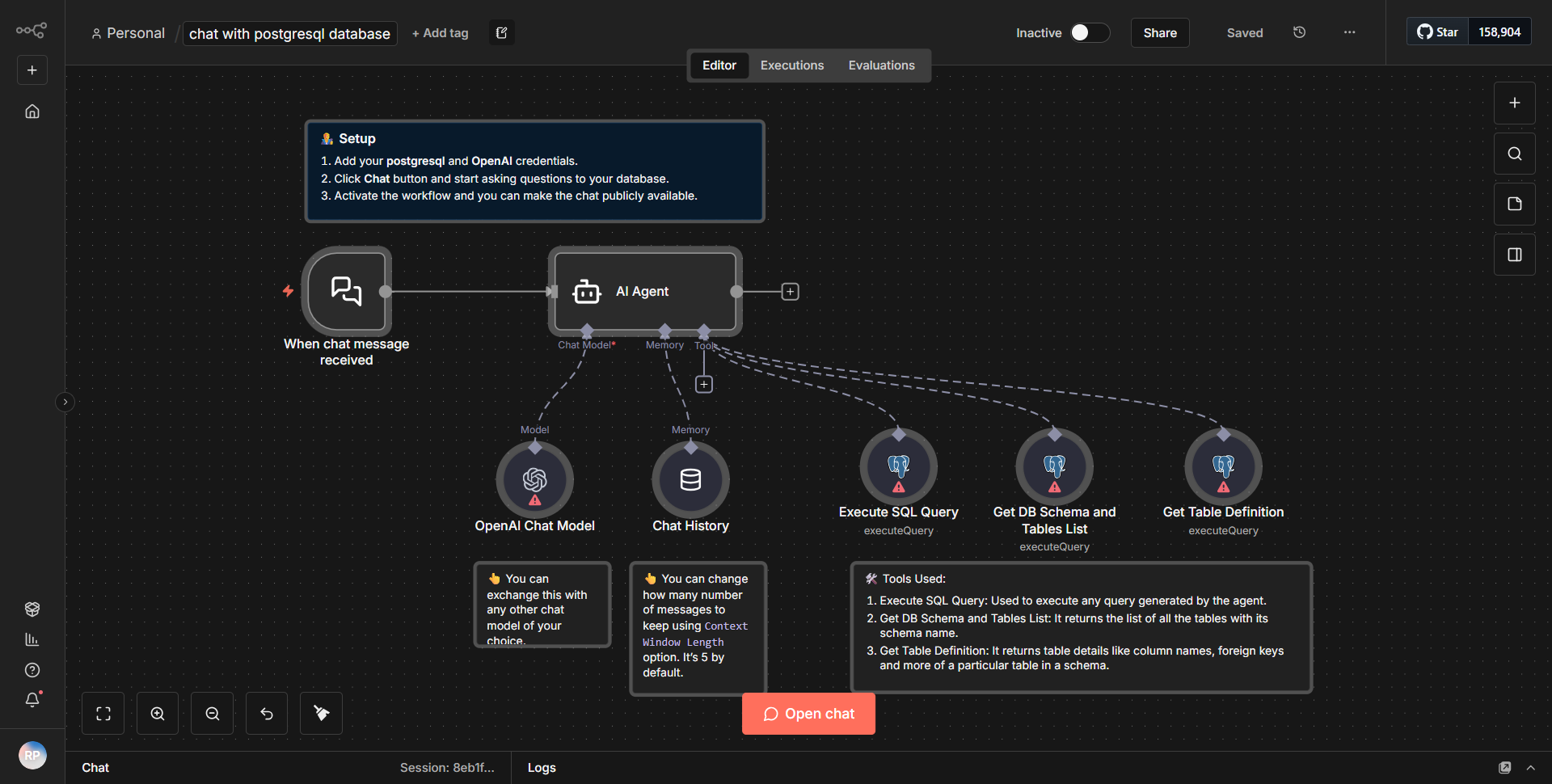
Este flujo de trabajo está diseñado para gestionar operaciones de datos en Supabase, centrándose específicamente en la inserción, inserción y recuperación de incrustaciones de vectores junto con sus metadatos asociados. El flujo de trabajo comienza con un nodo desencadenante que inicia el proceso en función de un evento específico.
1. Nodo de activación:
el flujo de trabajo comienza con un activador que escucha datos o eventos entrantes. Esto podría ser un webhook o un activador programado, según la implementación específica.
2. Preparación de datos:
después del activador, el flujo de trabajo utiliza un nodo de función para preparar los datos para su inserción. Este nodo procesa los datos entrantes y garantiza que estén formateados correctamente para Supabase. Puede implicar transformar la estructura de datos o extraer los campos necesarios.
3. Nodo de inserción de Supabase:
el siguiente paso implica un nodo de Supabase configurado para insertar nuevos registros en una tabla específica. Este nodo toma los datos preparados y los envía a Supabase, creando nuevas entradas en la base de datos.
4. Nodo Upsert de Supabase:
después de la inserción, el flujo de trabajo incluye una operación de inserción utilizando otro nodo Supabase. Este nodo busca registros existentes basándose en un identificador único y los actualiza si existen o los inserta si no es así. Esto garantiza que la base de datos se mantenga actualizada con la información más reciente.
5. Nodo de recuperación de Supabase:
Finalmente, el flujo de trabajo recupera datos de Supabase utilizando un nodo de recuperación. Este nodo consulta la base de datos en busca de registros específicos, que pueden usarse para un procesamiento posterior o devolverse como respuesta al desencadenante inicial.
A lo largo del flujo de trabajo, los datos fluyen sin problemas de un nodo al siguiente, lo que garantiza que las operaciones se ejecuten en la secuencia correcta para mantener la integridad y coherencia de los datos.
Características clave
- Inserción de datos:
el flujo de trabajo permite la inserción sencilla de nuevos registros en Supabase, lo que facilita la adición de nuevas incrustaciones de vectores y metadatos.
- Capacidad de inserción:
la funcionalidad de inserción garantiza que los registros existentes se actualicen sin duplicación, lo cual es crucial para mantener datos precisos en aplicaciones que cambian con frecuencia.
- Recuperación de datos:
la capacidad de consultar y recuperar datos de Supabase permite a los usuarios acceder y utilizar metadatos y incrustaciones de vectores almacenados de manera eficiente.
- Procesamiento de datos personalizado:
la inclusión de un nodo de función permite transformaciones de datos personalizadas, brindando flexibilidad en cómo se preparan los datos antes de enviarlos a Supabase.
- Arquitectura basada en eventos:
el flujo de trabajo puede activarse mediante varios eventos, lo que lo hace adaptable a diferentes casos de uso y escenarios de integración.
Integración de herramientas
- Supabase:
el servicio principal utilizado para las operaciones de bases de datos, incluida la inserción, inserción y recuperación de registros.
- Nodo de función:
Se utiliza para preparar y transformar datos antes de enviarlos a Supabase.
- Nodo de activación:
inicia el flujo de trabajo en función de eventos u horarios específicos.
Se requieren claves API
Para operar este flujo de trabajo, se requiere una clave API para Supabase. Esta clave es necesaria para autenticar las solicitudes realizadas al servicio Supabase. Asegúrese de que las credenciales adecuadas estén configuradas en el entorno n8n para facilitar una comunicación perfecta con la API de Supabase.