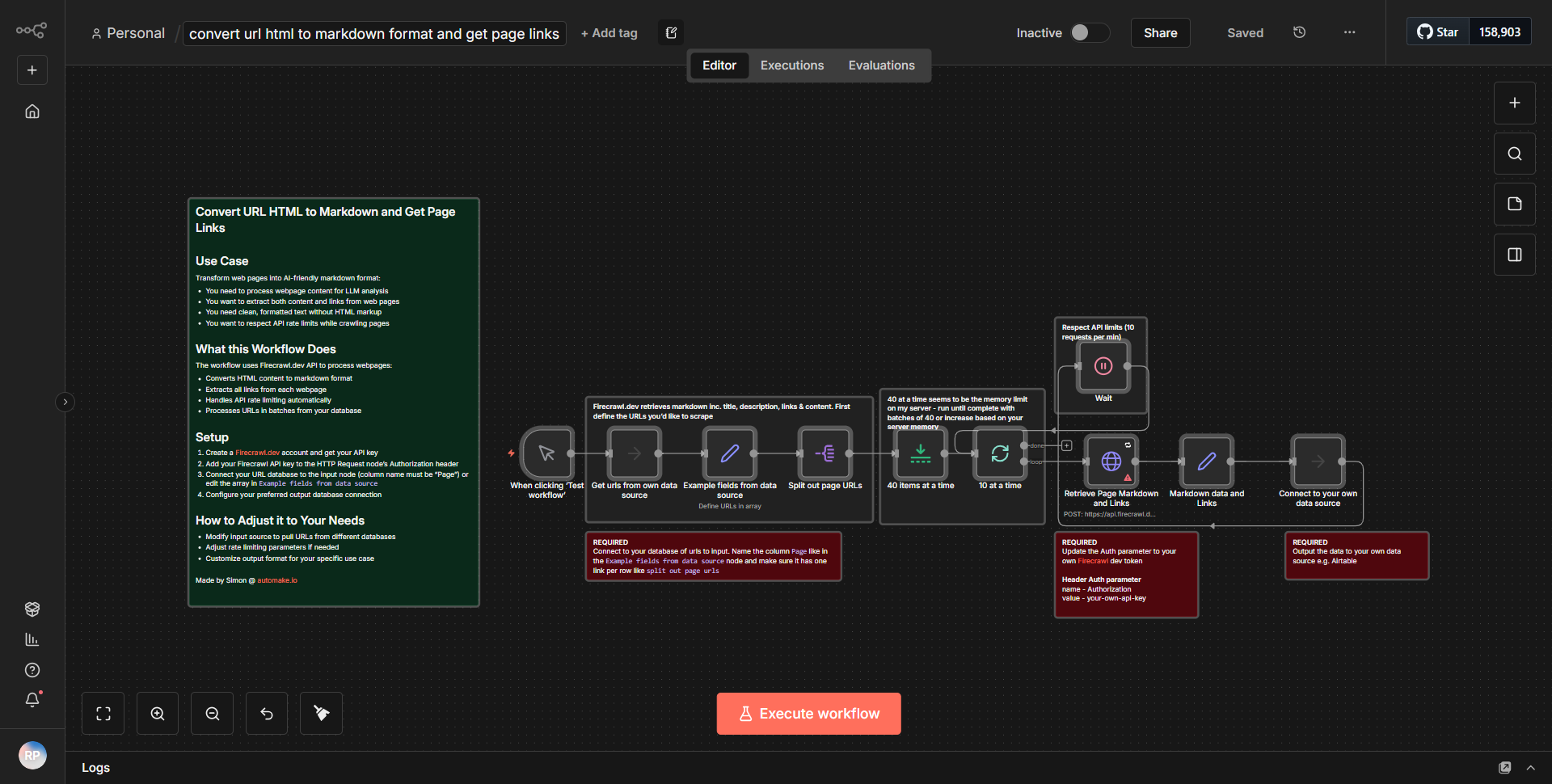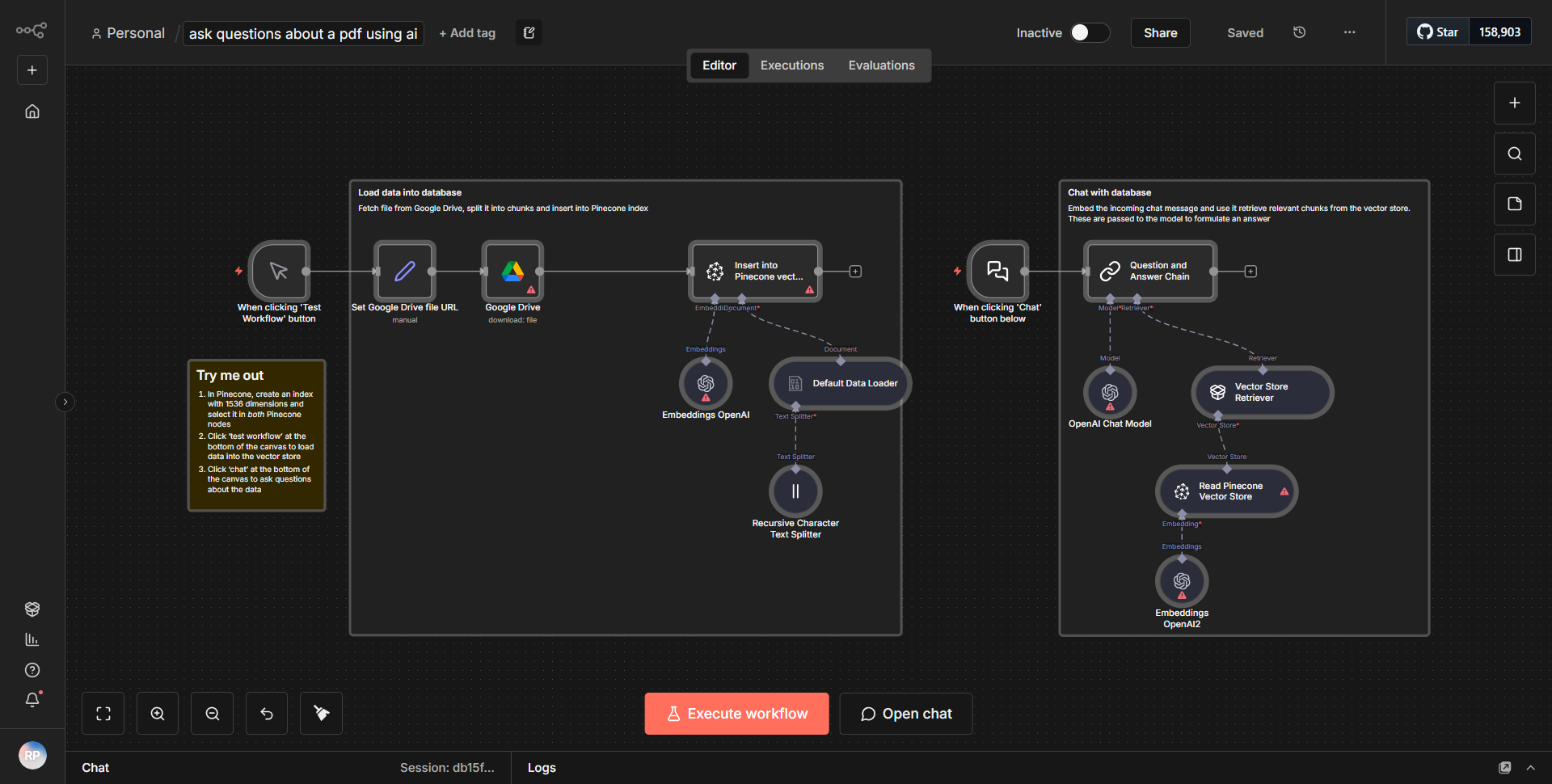
Consultar sobre un PDF que utiliza IA
Este flujo de trabajo recupera un archivo PDF de Google Drive, lo divide en segmentos, procesa los segmentos con incrustaciones de OpenAI y facilita las interacciones conversacionales con el contenido del documento.
Cómo funciona
Este flujo de trabajo comienza recuperando un archivo PDF de Google Drive utilizando el nodo de Google Drive. El nodo está configurado para buscar un archivo específico según su nombre o ID, asegurando que se acceda al documento correcto. Una vez recuperado el PDF, el flujo de trabajo continúa con el nodo "Extracción de PDF", que extrae el contenido del texto del archivo PDF. Este texto extraído luego se segmenta en partes más pequeñas para facilitar el procesamiento.
Después de la extracción y segmentación, el flujo de trabajo utiliza el nodo OpenAI para generar incrustaciones para cada segmento de texto. Este paso es crucial ya que transforma los datos textuales en un formato que los algoritmos de IA pueden entender y procesar. Las incrustaciones permiten consultas e interacción más eficientes con el contenido del documento.
Una vez creadas las incrustaciones, el flujo de trabajo incorpora una interfaz conversacional que permite a los usuarios hacer preguntas sobre el contenido del PDF. Esto se logra a través de una serie de nodos que manejan la entrada del usuario, procesan las consultas y devuelven respuestas relevantes basadas en las incorporaciones generadas anteriormente. El flujo de trabajo crea efectivamente un bucle donde las consultas de los usuarios se pueden procesar continuamente, lo que permite una experiencia interactiva con el contenido PDF.
Características clave
1. Recuperación de PDF:
el flujo de trabajo se integra perfectamente con Google Drive para recuperar documentos PDF, lo que facilita el acceso a los archivos almacenados en la nube.
2. Extracción de texto:
Emplea un nodo dedicado para extraer texto de archivos PDF, asegurando que toda la información relevante esté disponible para su procesamiento.
3. Segmentación de contenido:
el texto extraído se divide en segmentos manejables, lo que mejora la eficiencia del procesamiento de IA y permite respuestas más precisas a las consultas de los usuarios.
4. Incrustaciones de IA:
al utilizar incrustaciones de OpenAI, el flujo de trabajo transforma el texto en un formato vectorial, lo que permite capacidades avanzadas de IA para comprender y responder a las consultas de los usuarios.
5. Interfaz conversacional:
el flujo de trabajo admite un formato dinámico de preguntas y respuestas, lo que permite a los usuarios interactuar de forma interactiva con el contenido del PDF, lo que lo convierte en una poderosa herramienta para la recuperación y el aprendizaje de información.
Integración de herramientas
- Google Drive:
Se utiliza para recuperar el archivo PDF. El nodo de Google Drive está configurado para acceder a archivos específicos según parámetros definidos por el usuario.
- Extracción de PDF:
este nodo es responsable de extraer texto del documento PDF, asegurando que el contenido esté disponible para su posterior procesamiento.
- OpenAI:
el nodo OpenAI se utiliza para generar incrustaciones a partir de los segmentos de texto extraídos, lo que permite interacciones sofisticadas de IA.
- Webhook:
Este nodo permite la recepción de consultas de los usuarios, facilitando el aspecto conversacional del flujo de trabajo.
Se requieren claves API
Para operar este flujo de trabajo, se necesitan las siguientes claves API y credenciales:
- Clave API de Google Drive:
necesaria para autenticar y acceder a archivos almacenados en Google Drive.
- Clave API de OpenAI:
necesaria para utilizar los servicios de OpenAI para generar incrustaciones y procesar consultas de los usuarios.
No se requieren claves API ni credenciales de autenticación adicionales además de las mencionadas anteriormente.